Die Cloud-Anbieter wissen nicht, was die Kunden wollen, was also falsch und was richtig ist. Dafür muss noch nicht mal selbst programmiert werden, sondern eine fehlerhafte Konfiguration angebotener Dienste reicht aus. Prominentes Beispiel dafür ist der von AWS angebotene Speicherdienst S3, im April diesen Jahres, schätzte die Firma digital shadows [1], dass rund 1,5 Milliarden Dateien durch Fehlkonfigurationen ungeschützt dort lagern, darunter befinden sich medizinische Daten, Patentanträge und mein persönliches Highlight sogar „Security Audits“. Wer in die Cloud geht, sollte sich bewusst machen, dass der Grundgedanke die generelle Erreichbarkeit ist, die Einschränkungen muss man selbst vornehmen. Es muss also von Anfang an ein Sicherheitskonzept existieren. Dieses umfasst neben den üblichen Härten der genutzten Systeme, sauberer Programmierung auch den Aufbau oder vielmehr das Design der virtuellen Netzwerkumgebung. Eng mit der Zugriffsschutz verknüpft ist sozusagen das Gegenteil auch ein Aspekt von Sicherheit: das Sicherstellen der Erreichbarkeit.
Aufbau einer (ausfall-)sicheren, skalierbaren Struktur
Bereits im Insider 2017 ist die Netzwerk-Gestaltung innerhalb der Cloud Thema des Netzwerk Insiders gewesen. Der Schwerpunkt lag dabei auf dem Design. Dieser Artikel befasst sich mit den Themen Skalierbarkeit und ein wenig auch mit Sicherheit.
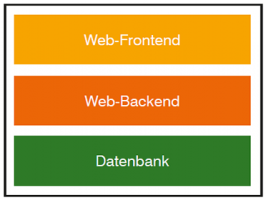
Abbildung 1: 3-tier Web-Architektur
Betrachten wir dazu zunächst eine typische 3-tier Web-Anwendung wie sie häufig in Clouds betrieben wird. Abbildung 1 zeigt sehr schematisch eine solche Architektur.
Nicht immer sind Front- und Backend unterschiedliche Systeme. Im Gegenteil: bei vielen kleineren Web-Auftritten und -Angeboten wird zwar verbal unterschieden, defacto handelt es sich jedoch um dasselbe System. Ein typisches Beispiel sind viele mit WordPress realisierte Auftritte: zwar ist die Datenbank ein eigenes System und bestenfalls eine eigene Serverumgebung, Front- und Backend sind jedoch identisch.
Um gleichzeitig ausfallsicher und skalierbar zu sein, muss man die Datenbank und auch das Backend, also die eigentliche Anwendungsebene, redundant auslegen.
Eine solche redundante Architektur zeigt Abbildung 2. Auffällig ist, dass das Front-End nicht redundant zu sein scheint. Darauf wird später eingegangen.
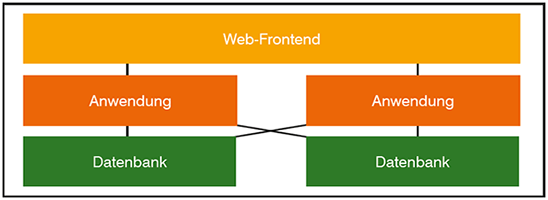
Abbildung 2: Redundante 3-tier Web-Architektur
Anwendungen in dieser Gestalt zu betreiben ist jetzt weder neu noch besonders Cloud-spezifisch. Auch im eigenen Rechenzentrum betreibt man schon lange solche Formen von Anwendungen. Darum übertragen wir diese Architektur nun in die Cloud und schauen dabei, welche Mittel einem für die Realisierung zur Verfügung stehen und worauf man achten muss.
Das Frontend
Um einige Methoden der Anwendungs-Ebene verstehen zu können, muss man zunächst einmal die Möglichkeiten kennen, die für das Frontend einer Web-Anwendung zur Verfügung stehen. Also jener Ebene, auf die die User aus dem Internet zugreifen.
CloudFront
CloudFront ist das Content Delivery Network (CDN) von AWS. Es können sowohl über HTTP/HTTPS wie auch RTMP Daten verteilt werden. Man kann die CloudFront also für Web-Anwendungen und für Streaming Dienste nutzen. Allerdings kann nur statischer Content per RTMP gestreamt werden: Video on Demand lässt sich also mit der CloudFront realisieren, Live-Übertragungen sind hingegen nicht möglich.
Das Vorgehen dabei ist recht einfach, wie in Abbildung 3 dargestellt: ruft ein User eine URL auf, die mittels des CDN verteilt wird, so wird seine Anfrage zum nächsten Point-of-Presence (PoP) der CloudFront geleitet. Im günstigsten Fall liegen die angeforderten Daten dort bereits im CDN vor und können sofort zum User gesendet werden, ohne dass die Anfrage zum eigentlichen Ursprung der Information geleitet und dort beantwortet werden muss. Ruft ein User in Florida bswp. eine Homepage auf, die in Frankfurt gehostet ist, so greift er auf einen PoP in den USA zu. Der PoP besorgt sich die Daten dann in Frankfurt, wenn sie nicht bereits vorliegen. Dabei werden eine Menge statische Dateien transferiert (Bilder, CSS-Dateien, Texte). Diese statischen Informationen sendet der PoP nicht nur an den User, sondern speichert sie auch selbst ab. Ruft ein anderer User später dieselbe Homepage auf, so liegen diese statischen Informationen auf dem PoP bereits vor und er sendet sie direkt an den User, ohne dass die Anfrage nach Frankfurt geleitet werden muss. Das spart dem Internet Bandbreitenverbrach und dem User Wartezeit. Wie lange die Daten im Cache des PoP gültig sind, gibt der Betreiber der Webseite vor.
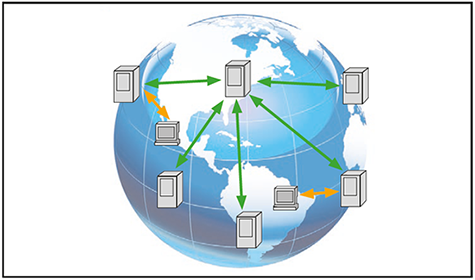
Abbildung 3: Coudfront
Da sich die CloudFront nur um die Verteilung, nicht aber die dauerhafte Speicherung und Aufbereitung der Daten kümmert, muss das anderswo geschehen. Im einfachsten Fall könnte das bspw. ein Webauftritt sein, der rein aus statischen Seiten besteht, diese können auf dem Speicherdienst S3 hinterlegt werden. Im Falle von Streaming ist das sogar die einzige Möglichkeit, deshalb ist auch kein Live-Streaming möglich. Für HTTP(S) kommen alle denkbaren HTTP Quellen in Betracht, wie bspw. Webserver, S3, Container, etc. Diese müssen nicht einmal in AWS gehostet werden, jedoch natürlich von der CloudFront aus erreicht werden können.
Der größte Vorteil der CloudFront ist die schnelle, weltweite Datenübertragung aus Sicht des Nutzers – vorausgesetzt die Daten liegen auf dem angefragten PoP vor. Die CloudFront eignet sich also für viel besuchte Webauftritte. Ein Nebeneffekt der CloudFront ist die Ausfallsicherheit: natürlich kann es zu Ausfällen einzelner Systeme oder gar eines ganzen PoP bei AWS kommen, jedoch wird Amazon sehr schnell darauf reagieren und Anfragen im Zweifelsfall zu einem anderen PoP umleiten. Zudem sind nur die Nutzer von einem Ausfall betroffen, die zu dem entsprechenden PoP geleitet werden. Es käme nicht zu einem kompletten Ausfall der Anwendung.
Sicherheitstechnisch bietet die CloudFront nur wenig Schutz für die Anwendungen. Zwar kann und sollte man sowohl die Datenbanken als auch die Anwendungsdienste vor externen Zugriffen schützen, indem man bei IPv4 mit privaten IP Adressen arbeitet und bei IPv6 die internen IP Adressen aus dem Internet heraus mittels Access-Listen nicht erreichbar macht. Angriffe auf dynamische Systeme sind jedoch weiterhin möglich, da diese von der CloudFront nur durchgeleitet nicht jedoch gescannt oder gefiltert werden. Allerdings ist es möglich, das mittels des Zusatzdienstes „Web Application Firewall“ zu realisieren, dazu später mehr.
Die Zugriffe auf die CloudFront können ebenfalls mittels einer ACL gefiltert werden, ebenso ist es möglich, bestimmte Regionen vom Zugriff auszuschließen, jedoch bietet das nur wenig Sicherheit. Eine geographische Filterung dürfte es in den meisten Fällen auch eher aus anderen Gründen erfolgen: beispielsweise wenn man das Angebot für unterschiedliche Märkte unterschiedlich gestalten möchte.
Eher ungeeignet ist die Cloudfront für Web-Auftritte, die nur sporadisch genutzt werden und für Anwendungen mit (fast) ausschließlich dynamischem Content arbeiten. Auch ist die CloudFront ausschließlich für HTTP(S) und RTMP verfügbar. Anwendungen, die andere Ports und Protokolle nutzen wollen, müssen auf den Load Balancer zurückgreifen.
Load Balancer
Benötigt man kein CDN oder kann es nicht nutzen (kein HTTP(S)/RTMP Traffic), so kann man alternativ einen oder mehrere Load Balancer nutzen. Grundsätzlich ist die Load Balancing Funktion von AWS nicht auf den Anschluss an das Internet beschränkt, sondern kann auch (mit einer Ausnahme, s.u.) für ein VPC internes Load Balancing genutzt werden.
Amazon bietet drei Arten von Load Balancern:
- Application Load Balancer
Diese Variante ist für die Lastverteilung von HTTP und HTTPS Verkehr. Dabei muss der Verkehr nicht zwingend über Port 80 respektive Port 443 transportiert werden, jedoch muss es das HTTP(S) Protokoll sein. Im Falle von HTTPS muss es auch am Load Balancer terminiert werden.
Das ist notwendig, damit der Load Balancer anhand der Layer 7 Informationen die Daten/Anfragen an die richtigen internen Dienste weiterleitet.
Als interne Dienste kommen neben virtuellen Servern (EC2 Instanzen) auch andere AWS Dienste infrage, beispielsweise ECS (Elastic Container Services, sprich Docker).
Der Load Balancer verteilt nicht nur die Anfragen auf die internen Instanzen, sondern überwacht auch, ob diese funktionieren und nimmt nicht funktionale Ziele aus der Lastverteilung, bis diese wieder funktionieren.
Da der Laod Balancer die eintreffende Last kennt, kann er mit anderen AWS Funktionen für die Skalierung der internen Anwendungsinstanzen zusammenarbeiten. Beispielsweise können bei Bedarf weitere EC2 Server gestartet werden oder Informationen an das ECS gegeben werden, um die Anzahl verfügbarer Container zu regeln. Umgekehrt geben diese Dienste die notwendigen Informationen an den Load Balancer zurück; beendet das ECS beispielsweise einen Container, so wird dieser aus dem Load Balancing herausgenommen.
Die Besonderheit des Application Load Balancers ist, dass er auf Layer 7 und ausschließlich für HTTP(S) arbeitet, d.h. anhand von HTTP Informationen kann er geeignete interne Dienste für die Weiterleitung identizieren und weiterleiten. So kann man z.B. ein Videoportal realisieren, bei dem die Videos auf anderen Systemen gehostet werden als die Webseite, beides jedoch unter derselben Domain erreichbar ist.
- Network Load Balancer
In weiten Zügen verhält sich der Network Load Balancer wie der Application Load Balancer. Der Unterschied ist, dass er auf dem OSI Layer 4 arbeitet, nicht auf Schicht 7. Das hat den Vorteil, dass auch nicht HTTP Datenströme auf verschiedene Instanzen innerhalb des VPC verteilt werden können. Der Nachteil ist, dass diese Lastverteilung keine Anwendungsdaten berücksichtigen kann. Setzt man den Netzwerk Load Balancer für HTTP ein, so können beispielsweise keine URL-Pfade für die Verteilung genutzt werden, sondern alle Anfragen eines Clients landen auf derselben internen Instanz.
- Classic Load Balancer
Diese Variante der Vorläufer der beiden anderen wird (zur Zeit noch?) von AWS angeboten. Sie beinhaltet in einer Konfiguration ein wenig von den beiden neueren Load Balancern. So kann sie sowohl für HTTP(S) als auch für TCP genutzt werden, hat jedoch verglichen mit den neueren Varianten auch Einschränkungen: so beherrscht der Classic im Vergleich zum Application Load Balancer weder HTTP/2 noch ein pfadbasiertes Routing, wie zuvor vorgestellt. Auf Seiten des Network Load Balancing können bspw. nicht mehrere Ports derselben Instance als Ziele zugeordnet werden, auch werden die Quell-IP Adressen in jedem Fall geändert wohingegen der Network Load Balancer auch transparent arbeiten kann.
Hat man diesen Load Balancer in Betrieb, gibt es keinen Grund ihn aktuell abzulösen, jedoch sollte man bei neuen Projekten besser die neuen Varianten nutzen.
Den Load Balancern ist gemein, dass sie einer Availability Zone zugeordnet werden, die Lastverteilung jedoch auch über die eigene Zone hinaus erfolgen kann, allerdings nicht muss. Dadurch ist ein Load Balancer zunächst einmal ein Single Point of Failure. Zwar sichert Amazon die Load Balancing Funktion ab und überwacht die Funktionalität, fällt jedoch das gesamte Rechenzentrum aus, in dem der Load Balancer läuft, so sind auch die Dienste nicht mehr erreichbar, die in den noch arbeitsfähigen Availability Zonen gehostet werden. Für die Hochverfügbarkeit sollte man also in mehreren Zonen Load Balancer betreiben.
Die Lastverteilung auf die Load Balancer erfolgt dabei über das hauseigene DNS, Route 53: betreibt man zwei Load Balancer, so wird der DNS-Namen des Dienstes vom DNS mal mit der IP Adresse des einen LB, mal mit der des anderen aufgelöst. Die Cache-Zeit (TTL) des Eintrages ist dabei mit 60 Sekunden sehr niedrig angesetzt, um auf Ausfälle oder Laständerungen sehr schnell reagieren zu können.
Wie bereits erwähnt können die Load Balancer selbst die Last jedoch Zonen-übergreifend verteilen. Ist das, wie in Abbildung 4 dargestellt, eingeschaltet, so wird die Last von beiden LB gleichmäßig auf die 5 Systeme verteilt. Jedes Instanz bekommt somit im Durchschnitt 20% der Last ab.
Hat man dieses Feature nicht aktiviert, so kommt es zu einer anderen Verteilung, wie exemplarisch in Abbildung 5 gezeigt: beide Load Balancer bekommen 50% der Anfragen. Da diese jedoch in der Availability Zone gehalten worden, bekommt jede Instanz von Zone 1 rund 16,7% des gesamten Verkehrs, wohingegen die Instanzen in Zone 2 jeweils 25% von allem verarbeiten müssen.
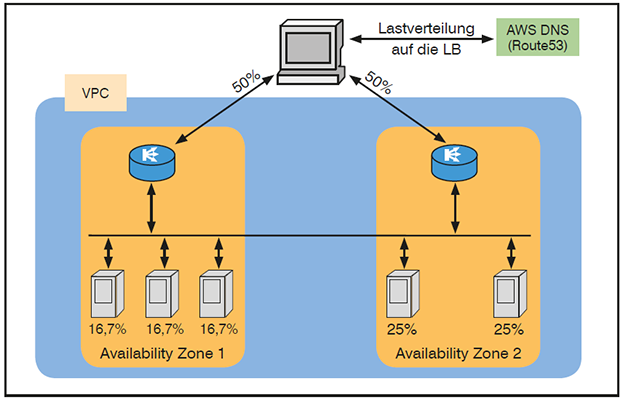
Abbildung 5: Load Balancer ohne zonenübergreifendem Load Balancing
Es ist von der Variante des Load Balancers und der Art, wie er in Betrieb genommen wurde (mittels Console oder über CLI) abhängig, ob ein zonenübergreifendes Load Balancing überhaupt möglich und per default aktiviert ist oder nicht.
Sicherheit ist nicht der Fokus der Load Balancer: sie sind primär als hochperformante Datenschaufeln angelegt, da fehlt die Zeit, noch tiefe Inspektionen dessen vorzunehmen, was man transportiert. Somit bleibt die Funktionalität diesbezüglich auf der Ebene von Access-Listen beschränkt.
Auf den ersten Blick wirkt ein Application Load Balancer wie eine abgespeckte Variante der CloudFront, da beide Web-Anwendungen adressieren. Dem ist jedoch nicht so, es gibt gravierende Unterschiede: so kann der Load Balancer auch VPC intern genutzt werden und Entscheidungen auf Basis von HTTP Informationen treffen, beides ist der CloudFront nicht möglich. Seine Einschränkung liegt im Fehlen der CDN Funktion. Benötigt man beides, kann man natürlich beides betreiben, indem die CloudFront die Daten über den Load Balancer abruft.
Der Netzwerk Load Balancer erweitert die Nutzbarkeit der Load Balancing Funktion bei AWS über die reinen Web-Anwendungen hinweg, bleibt jedoch auf reines Layer-4 Load Balancing beschränkt. In den meisten Fällen dürfte das jedoch völlig ausreichen.
Mehr Sicherheit: Web Application Firewall (WAF)
Weder die CloudFront noch der Application Load Balancer adressieren die Sicherheit. Access Listen sind zwar ganz nett, aber sie als ernst zu nehmende Firewall zu betrachten ist doch eher Marketing. Darum gibt es speziell für Web-Anwendungen eine Erweiterung bei AWS: die Web Application Firewall, kurz WAF.
Die WAF-Funktion kann sowohl zusammen mit der CloudFront als auch mit den Load Balancern genutzt werden. Sie ähnelt dabei Access Listen, jedoch hat sie einen anderen Funktionsumfang, der das Filtern von typischen Angriffen auf Web-Anwendungen erlaubt. Dazu stehen folgende Möglichkeiten zur Verfügung:
- Quell-IP-Adressen,
- Geolokalisierung der Quelle der Anfrage,
- Auswertung der Anforderungs-Headern,
- reguläre Ausdrücke zum Auswerten von Anforderungen (GET/POST-Requests),
- Länge der Anforderungen,
- Erkennen von schädlichem SQL-Code (SQL Injections) in Anfragen,
- Erkennen eines möglicherweise schädlichen Skripts (Cross-Site Scripting).
Wie bei klassischen Access Listen können auf Basis dieser Filter Regeln erstellt werden, die den Zugriff erlauben oder verbieten. Um nicht in die Falle zu laufen, die Web-Anwendung durch die Aktivierung abzuschießen, gibt es noch eine dritte Möglichkeit: das Zählen. Dabei werden die Hits erfasst, man sieht also, ob eine Regel zur Anwendung kam oder nicht. Dieses kann genutzt werden, um die WAF-ACL zu testen und zu monitoren. Außerdem können so auch Denial of Service Angriffe identifiziert werden.
In Abbildung 6 sieht man beispielhaft die Anlage einer WAF-ACL. Dabei ist zu beachten, dass der Punkt „AWS resource to associate“ optional ist. Es ist durchaus möglich und oft auch sinnvoll, die ACL weder einer Anwendung („CloudFront“) noch einer Region zuzuordnen. Wie ACLs in AWS können nämlich auch WAF-ACLs mehr als einer Ressource zugeordnet werden, wenn sie einmal geschrieben sind. Umgekehrt gilt jedoch, dass jede Ressource nur eine WAF-ACL haben kann.
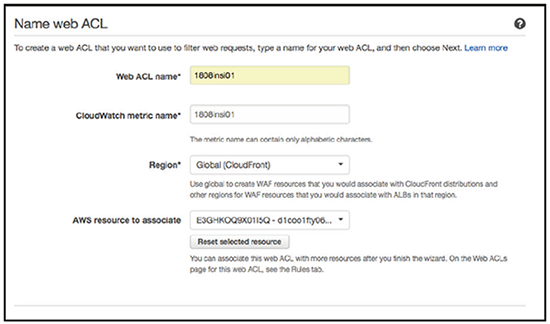
Abbildung 6: Anlegen einer WAF-ACL
Abbildung 7 zeigt beispielhaft das Aufsetzen eines Filters auf Basis regulärer Ausdrücke. Zu beachten ist, dass es sich hier nur um die Bedingung, nicht die Aktion handelt (erlauben, verwerfen, zählen).
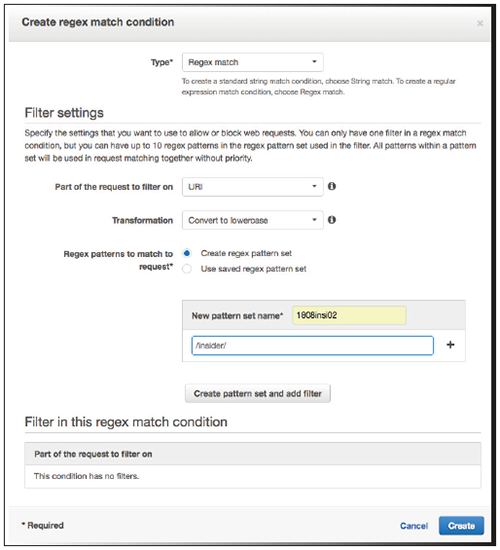
Abbildung 7: Beispiel eines Filters einer WAF-ACL
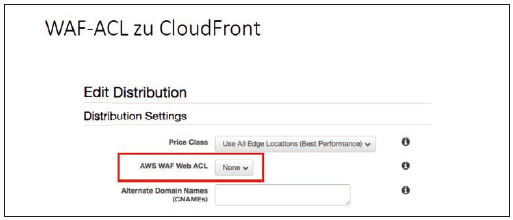
Anders als Load Balancer oder CloudFront ist die WAF keine Instanz, sondern ist ein Regelwerk. Das heißt, anders als der Name vermuten lässt, ist es keine Firewall, der man eine IP Adresse zuweisen muss und die man zwischen Internet und Load Balancer / CloudFront positioniert. Vielmehr wird das Regelwerk direkt an den Dienst gebunden. Abbildung 8 zeigt wie eine WAF-ACL einer CloudFront Distribution zugeordnet wird.
Neben dem Filtern von Anfragen kann die WAF aber noch mehr: unter dem Schlagwort „WAF Shield“ verbirgt sich die Abwehr von Distributed Denial of Service (DDoS) Angriffen. Dafür gibt es zwei Varianten des AWS Shields: „Standard“ und „Advanced“.
Die Standard-Variante gibt es sozusagen kostenlos für alle AWS Kunden. „Sozusagen“ heißt, dass AWS versucht anomalen Traffic automatisch zu erkennen, indem der Netzwerk-Flow überwacht wird, also Layer 3 und 4. Beim Advanced Shield wird zusätzlich auch das Verhalten von Layer 7 auf Anomalitäten überwacht. AWS wehrt auf dieser Basis automatisch bestimmt, typische DDoS Angriffe wie Syn Flooding oder UDP Reflection ab.
Kombiniert man den Shield mit der WAF-ACL ist jedoch mehr möglich: man kann WAF-ACLs erstellen, um Angriffe zu erkennen und darauf zu reagieren. Die WAF-ACLs dienen zunächst mal nur der Erkennung und somit als Trigger, der bei Überschreitung bestimmter Grenzwerkte Aktionen auslöst, beispielsweise weitere Filter aktiviert. Das ist dann in der Standard-Version jedoch nicht mehr kostenlos, da die WAF-Filter Geld kosten. Hat man sich hingegen für den Advanced Shield entschieden, sind einige solcher Maßnahmen im Preis inbegriffen.
Hat man viele Ressourcen, die man in AWS mit WAF-Regeln absichern will, so sollte man einen Blick auf den vergleichsweise neuen AWS Firewall Manager werfen. Der Firewall Manager kann auch nützlich sein, wenn man häufig neue zu schützende Ressourcen hinzufügt, um Regeln automatisch zuzuweisen. Die Regeln werden neuen Ressourcen automatisch nach einer Policy zugewiesen. Ein einfaches Beispiel wäre eine Policy, die festlegt, dass alle Ressourcen in der CloudFront durch eine bestimmte WAF-ACL geschützt werden, wenn sie ein bestimmtes Tag zugewiesen bekommen. Der Firewall Manger arbeitet sogar Kontoübergreifend. Da der Firewall Manager selbst keine weitere Sicherheit bietet, wird er hier nicht weiter betrachtet.

Teile diesen Eintrag