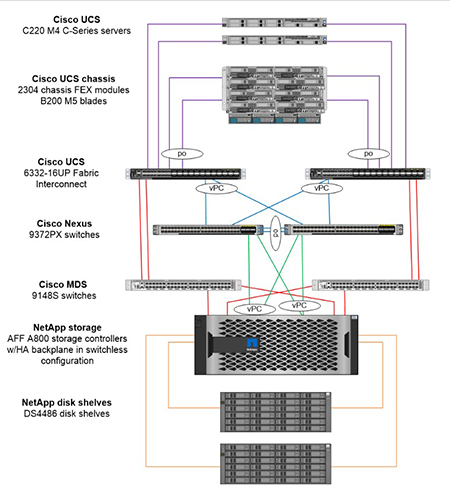
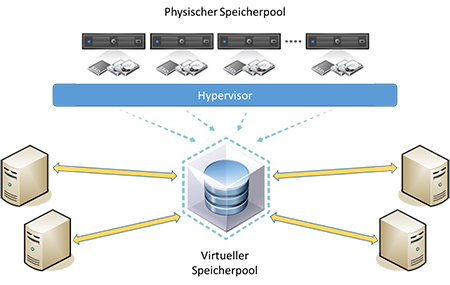
Die technische Seite – vorhandene Infrastruktur
In vielen Unternehmen ist zumindest ein Teil der Infrastruktur, insbesondere der Storage, schon vorhanden und sollte nach Möglichkeit effizient genutzt werden, um die meist hohen Anschaffungs- und Betriebskosten zu rechtfertigen. Mit Blick auf die zusätzlichen impliziten Lizenzkosten, die bei Nutzung einer CI- oder HCI-Lösung anfallen können, kann eine Herausforderung darin liegen, die Ausgaben für eine solche Lösung zu rechtfertigen.
Sollte sich allerdings eine bestehende zentrale Speicherlösung als Flaschenhals bei der Performance erwiesen haben, zum Beispiel im Bereich Big Data oder KI, so können sowohl CI als auch HCI eine Entlastung der bestehenden Umgebung darstellen und deren Lebenszeit für weniger Performance-kritische Anwendungen und Services signifikant erhöhen.
Es besteht bei einigen Fabrikaten (zum Beispiel Dell VxRail) außerdem die Möglichkeit, zusätzlich zum integrierten (verteilten) Storage auch externen (schon vorhandenen) Storage anzubinden, so dass ein Zwischenweg zwischen „alles ersetzen“ und „Bestehendes weiternutzen“ möglich ist. Hier muss aber berücksichtigt werden, dass dieses Einsatzszenario dem eigentlichen Gedanken von (H)CI widerspricht und somit einige zusätzliche Herausforderungen mit sich bringt. Zum Beispiel ist es nicht möglich, den schon vorhandenen Storage in der zentralen Oberfläche der (H)CI-Lösung zu administrieren, sondern man muss diesen Speicher auf Ebene der Virtualisierungslösung (zum Beispiel VMware vSphere) einbinden und administrieren. Durch diesen „Mischbetrieb“ geht ein Teil des Betriebsvorteils, den (H)CI verspricht, wieder verloren.
Ein weiterer, nicht zu vernachlässigender Aspekt ist die vorhandene (oder zu planende) Backup-Infrastruktur. Während CI-Systeme teilweise Fibre Channel nutzen und somit eine direkte Anbindung von FC-basierten (Virtual) Tape Libraries (VTLs) unterstützen können, ist beim Einsatz von HCI die Ethernet-Schnittstelle meist die einzige Möglichkeit, Daten aus der Virtualisierungsumgebung in ein Backup-System zu übertragen. Daher ist bei der Planung einer solchen Umgebung auch die Berücksichtigung eventuell zusätzlicher Systeme oder Software für die Datensicherung wichtig. Dies kann von „einfachen“ Lösungen, bei denen die VMs innerhalb der (H)CI-Umgebung die zu sichernden Daten auf externe Server kopieren, über Agents, die diese Aufgabe übernehmen, bis hin zu Speziallösungen gehen, die die Spezifika des jeweiligen Anbieters berücksichtigen. Letztere können eine einfachere Einrichtung und einen unkomplizierteren Betrieb erlauben, sind aber meistens mit höheren Kosten verbunden. Außerdem ist eine Wiederherstellung der Daten bei einem Herstellerwechsel eventuell erschwert.
All diese Punkte sollen auf keinen Fall pauschal den Einsatz von (H)CI als wenig sinnvoll darstellen; der verringerte Betriebsaufwand kann durchaus Anpassungen an der bestehenden Infrastruktur rechtfertigen. In einer Reihe von Projekten hat die ComConsult auch schon die Umsetzung solcher Lösungen betreut, in denen die bestehende Infrastruktur bereits alle Rahmenbedingungen erfüllt hat und die Einführung von (H)CI die logische Weiterführung der bisherigen RZ-Strategie darstellte. Als Beispiel seien hier abgeschlossene Umgebungen genannt, die nur in begrenztem Umfang (zum Beispiel beim Backup) mit der existierenden Infrastruktur „verheiratet“ werden mussten.
Am leichtesten ist die Einführung von (H)CI natürlich, wenn noch keine Infrastruktur vorhanden ist, zum Beispiel bei einem neuen Rechenzentrum oder einem Hardware-Refresh. In diesem Fall kann die Entscheidung für oder gegen (H)CI – abgesehen von den eventuellen Kosten – auf Basis des Betriebs, der IT-Sicherheit und der zu erwartenden Größe der Umgebung getroffen werden.
Die betriebliche Seite – organisatorische Strukturen und Silos
Eine meist viel wichtigere Rolle als die vorhandene Infrastruktur und die Kosten stellt der eigentliche Betrieb der Lösungen dar. Ein häufig von den Herstellern angepriesener Vorteil von CI und HCI ist das (angeblich) sehr einfache und meist intuitive Management aus einer zentralen Oberfläche, auf der alle Aspekte der Lösung überwacht und verwaltet werden. Wenn die Lösung von wenigen Personen betreut wird, ist dies natürlich ein unbestreitbarer Gewinn an Komfort und Effizienz. In vielen Unternehmen ist aber eine mehr oder weniger strikte Trennung zwischen den einzelnen Bereichen vorhanden, was auch als „Silodenken“ bezeichnet wird. Die Silos können dabei sehr unterschiedlich gestaltet und auch mehr oder weniger gegen die anderen Silos abgeschirmt sein. So können für die einzelnen Bereiche auch unterschiedliche Dienstleister verantwortlich sein. Bei einer Aufteilung zwischen
- Compute
- Storage
- Netzwerk
- IPAM (IP-Adressmanagement)
- IT-Sicherheit
- Firewall
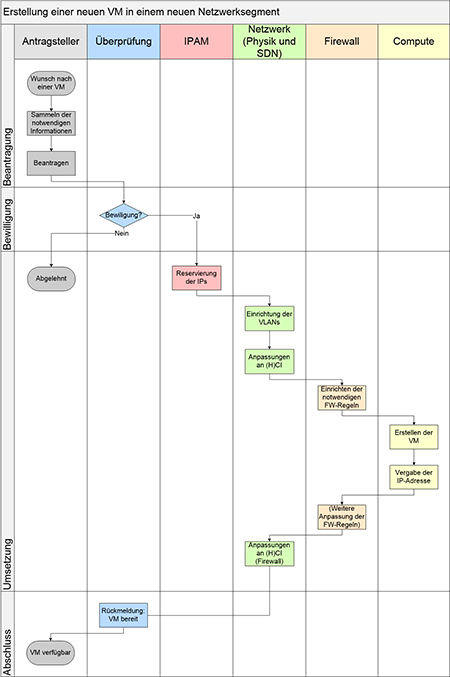
Abbildung 3: Beispielprozess Erstellung einer neuen VM in einem neuen Netzwerk-Segment mit strengem Silodenken
müssen so zum Beispiel fünf Bereiche (IPAM wird in der Regel auch weiterhin organisatorisch getrennt bleiben.) koordiniert werden, die im schlimmsten Falle nicht immer dieselben Ziele verfolgen. Zwar kann in einem solchen Fall eine (H)CI-Lösung im Allgemeinen so eingerichtet werden, dass jeder Bereich nur die für ihn relevanten Elemente sehen und administrieren kann, dadurch wird aber der ursprüngliche Gedanke des „Single Pane of Glass“ ad absurdum geführt, da zwar alle die gleiche Oberfläche nutzen, aber keiner die Gesamtsicht auf alles hat. In einer sehr strengen Silo-Welt kann daher die Einführung einer solchen Lösung sogar zu zusätzlichem Aufwand führen, da die Rechtevergabe und die Eingewöhnung in ein neues Tool zu Reibungsverlusten führen können. Unter der Voraussetzung, dass der Storage für die (H)CI-Lösung eingerichtet und verfügbar ist, ist ein beispielhafter Prozess für die Einrichtung einer VM in einem neuen Netzwerksegment in Abbildung 3 dargestellt.
Je weniger strikt die Trennung der Bereiche voneinander ist, desto attraktiver wird eine (hyper)konvergente Lösung. Der Idealfall ist (zumindest aus Sicht der Hersteller) ein übergreifendes Team, das alle Bereiche behandelt und in dem die Mitarbeiter alle Bereiche zumindest grundlegend kennen und bei Bedarf auf Experten zurückgreifen können. Damit unterscheidet sich der Betrieb einer (H)CI-Lösung nur geringfügig von anderen, weniger stark integrierten SDDC-Lösungen (siehe auch [1]). Der in Abbildung 4 dargestellte Prozess vereinfacht sich demnach sehr stark.
Auch hier ist natürlich ein Mittelweg möglich. In vielen Fällen, gerade bei kleinen bis mittelgroßen Unternehmen, sind die Verantwortlichkeiten zwar klar aufgeteilt, es herrscht aber dennoch ein reger Austausch zwischen den Abteilungen und ein Interesse an mehr als dem eigenen Thema. In diesen Fällen können auch verschiedene Silos ergebnisorientiert und unkompliziert den gemeinsamen effektiven und effizienten Betrieb einer Lösung gewährleisten. In einem solchen Fall können CI und HCI zu schnellerer Bereitstellung von Diensten führen. Durch die potentielle Zeitersparnis ist es den beteiligten Mitarbeitern häufig möglich, sich stärker mit Innovationsprojekten zu beschäftigen und damit das eigene Unternehmen langfristig konkurrenzfähig zu halten.
Gibt es betrieblich eine besondere Präferenz oder eine einfache Entscheidungsmöglichkeit entweder für CI oder für HCI? Leider nicht. Hier muss jedes Unternehmen eine individuelle Entscheidung treffen. Wenn beispielsweise schon Erfahrungen mit „klassischen“ Herstellern wie DellEMC oder NetApp vorhanden sind, so kann eine auf den Produkten dieser Hersteller basierende CI-Lösung aufgrund des vorhandenen Knowhows interessant sein.
Ihre Firma hat bereits in anderen Bereichen VMware VSAN und/oder VMware NSX im Einsatz? Dies sind die Grundbausteine vieler HCI-Lösungen, so dass aus vorhandener Erfahrung der Einstieg in die HCI-Welt mit wenig zusätzlichem Aufwand verbunden ist.
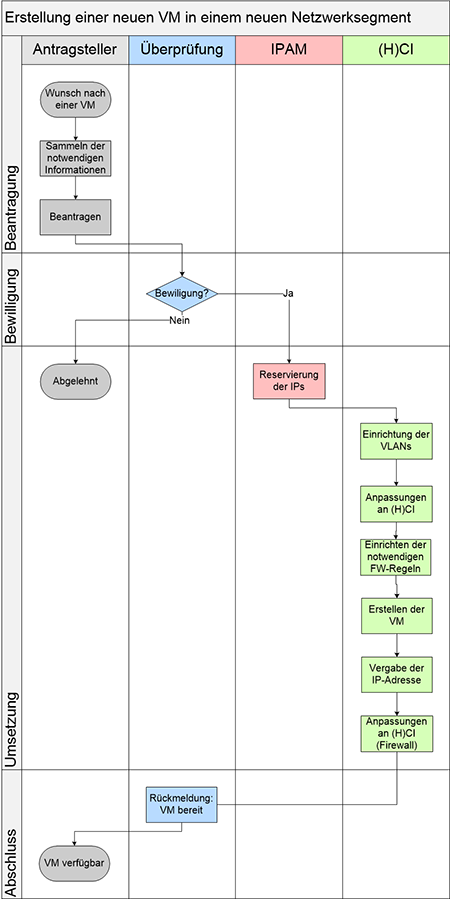
Abbildung 4: Beispielprozess Erstellung einer neuen VM in einem neuen Netzwerk-Segment mit kombiniertem Team
Denn die Einführung einer neuen Technologie stellt betrieblich immer eine Herausforderung dar. Dies beginnt bei der Implementierung und endet noch lange nicht nach einer erfolgreichen Inbetriebnahme oder Migration. Gerade im Fehlerfall zeigen konvergente und hyperkonvergente Systeme ihre guten und schlechten Seiten. Einerseits kann die enge Verzahnung der einzelnen Komponenten die Fehlersuche erschweren, andererseits ergeben sich durch den zentralisierten Ansatz neue Analysemöglichkeiten. Das Troubleshooting wird daher in einigen Bereichen deutlich einfacher, benötigt aber in anderen Bereichen eventuell neue Ansätze. Auch dies ist ein für den (erfolgreichen) Betrieb elementar wichtiger Aspekt, der keinesfalls vernachlässigt werden darf!
Genau wie im technischen Bereich ist auch beim Betrieb der Einsatz von (H)CI in neuen, abgeschlossenen Umgebungen ein interessanter Einstiegspunkt. Auf betrieblicher Seite ermöglicht ein solches Szenario das Etablieren und Testen neuer Betriebsansätze und –prozesse, aus denen positive Effekte für den übrigen Betrieb gewonnen werden können. Ein externer Dienstleister kann unter Umständen bessere SLAs und sonstige Vertragsbedingungen anbieten, wenn er die Möglichkeit hat, mit einer hochintegrierten Lösung zu arbeiten. Dies ist insbesondere dann interessant, wenn Sie manche Dienste inkl. zugrunde liegender Hardware zwar an eigenen Standorten aufstellen, aber nicht selber betreiben wollen.
Die IT-Sicherheit – Anforderungen an und Möglichkeiten von (hyper-)
konvergenten Lösungen
Was die Sicherheitsaspekte einer konvergenten oder hyperkonvergenten Lösung angeht, so ändert sich der bisherige Ansatz, da viele sicherheitsrelevante Komponenten in die (H)CI-Lösung wandern und höchstens bei der Kommunikation mit externen Systemen die bisherigen Komponenten wie Firewalls eine Rolle spielen. Das Ziel der Konsolidierung im Rechenzentrum verstärkt sich noch einmal, wie es schematisch in Abbildung 5 dargestellt ist.
Bei dieser Konsolidierung müssen speziell die Aspekte der (logischen) Trennung auf Speicher- und Netzwerk-Ebene beachtet werden.
Bei Converged Infrastructure werden prinzipiell dieselben Mechanismen eingesetzt wie bei „klassischer“ Infrastruktur. Wenn nötig können Funktionalitäten wie VLANs auf Netzwerk- und Port Zoning auf Speichernetz-Ebene verwendet werden. Diese werden, je nach Einsatzszenario (teilweise) automatisiert von der jeweiligen Management-Oberfläche umgesetzt, so dass hier eine erhebliche Aufwandsminderung möglich ist. Diesen Mechanismen muss aber ein entsprechendes Vertrauen entgegengebracht werden, da manuelle Anpassungen an Teilen der Umgebung schwer bis unmöglich sein können. Daher können sich hier auch Software-Bugs in den Automatisierungs- oder Abstraktionsschichten schnell und weitreichend auswirken.
Wenn die Trennung zwischen Mandanten oder Segmenten nicht direkt auf Hardware-Ebene bzw. den aktiven Komponenten der Infrastruktur stattfindet, sondern in der jeweils eingesetzten Virtualisierungslösung, so muss diese den Ansprüchen des jeweiligen Unternehmens bezüglich Güte der Trennung gerecht werden. Bei hyperkonvergenter Infrastruktur entfällt sogar die Möglichkeit einer Anpassung unterhalb der Virtualisierungsschicht, so dass hier ausschließlich deren Trennungs- und Sicherheitsmechanismen eingesetzt werden können.
Auf der einen Seite kann es bei der Trennung verschiedener Bereiche – je nach Tätigkeitsbereich des Unternehmens – regulatorische Anforderungen geben, die erfüllt sein müssen. In manchen Bereichen bieten die Hersteller von (H)CI-Lösungen hier entsprechende Nachweise, Zertifizierungen oder Maßnahmenkataloge, die bei der Umsetzung der Forderungen helfen können. Sollte für bestimmte Bereiche sogar eine physische Trennung erforderlich sein, beispielsweise für eine Demilitarized Zone (DMZ) oder Systeme mit erhöhtem Schutzbedarf, können diese auf einer dedizierten CI- oder HCI-Lösung betrieben werden, da gerade in kritischen Bereichen ein einfacher Betrieb auch die Sicherheit erhöhen kann.
Auch die immer weiter verbreitete Nutzung von Container-Technologien stellt aus Sicht der IT-Sicherheit eine neue Herausforderung dar, da Container eine weniger starke Isolation von Diensten gegeneinander bietet, so dass die Mechanismen der Virtualisierungslösung nur noch eine untergeordnete Rolle spielen. In diesem Fall sind die Isolationsmechanismen von (H)CI-Lösungen auf VM-, Netzwerk- und Speicherebene im Allgemeinen ausreichend.
Container stellen dabei eine von mehreren möglichen Diensten dar, die auf einer (hyper-)konvergenten Lösung betrieben werden können. Diese und weitere Technologien sollen im folgenden Abschnitt betrachtet werden.
Dienste und Anwendungen – was wird auf der (H)CI-Lösung betrieben?
Ebenfalls von hoher Bedeutung für die Sinnhaftigkeit einer (H)CI-Lösung sind die Dienste, die darauf betrieben werden sollen. Im Folgenden sollen verschiedene Möglichkeiten als Beispiele betrachtet werden:
- Klassische, auf bare-metal optimierte Software
- Virtualisierte Workloads
- Dienste in Form von Microservices, die typischerweise auf Container-Plattformen basieren
- Cloud-artige Dienste, die den Nutzern schnell und unkompliziert zur Verfügung gestellt werden sollen
Klassische, zum Beispiel aus Lizenzgründen nicht für Virtualisierungsumgebungen geeignete oder optimierte Dienste und Anwendungen sind natürlich keine vielversprechenden Kandidaten für CI und eventuell für HCI vollständig ungeeignet. Sämtliche Vorteile, die die Lösungen durch den hohen Integrationsgrad, das zentrale Management und die eingeführten Abstraktionsschichten haben, werden hier vollständig zunichtegemacht.
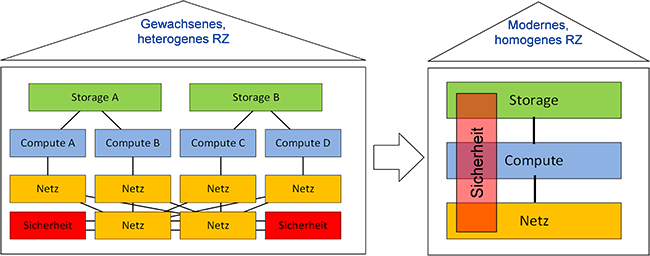
Abbildung 5: Übergang von „Best-of-Breed “ zu übergreifenden, integrierten Elementen eines stark konsolidier-ten RZs, wie es mit CI oder HCI umgesetzt werden kann
Virtualisierte Workloads, wie sie schon heute in den meisten Rechenzentren eher die Regel als die Ausnahme sind, können davon profitieren, auf einer (H)CI betrieben zu werden. Sollte zum Beispiel eine Umgebung an ihre Kapazitätsgrenzen stoßen, ist eine schnelle Erweiterung durchaus vorteilhaft. Auch können die zentralen Management-Interfaces eine bessere Einsicht in eventuelle Engpässe bieten oder Korrelationen aufzeigen, die bei getrenntem Compute, Storage und Netzwerk nur schwer zu erkennen sind.
Auch Container können von CI oder HCI profitieren, da die der Container-Lösung zugrunde liegende (virtualisierte) Infrastruktur schnell und mit wenig Aufwand provisioniert, überwacht und bei Bedarf skaliert wird. Auch bei Erreichen der Kapazitätsgrenzen einer konvergenten Lösung ist eine Erweiterung prinzipbedingt schneller und einfacher als bei einer individuellen Beschaffung von Compute, Storage und Netzwerk. Dieser Ansatz ist in gutem Einklang mit der Grundidee hinter dem Einsatz von Containern: Einfache, schnelle und flexible Skalierung eines Dienstes durch Hinzufügen zusätzlicher Ressourcen.
All ihre Stärken können CI und HCI dann ausspielen, wenn auf ihnen eine „eigene Cloud“ betrieben werden soll. Die Skalierungseinheiten – seien es Racks (CI) oder einzelne Knoten (HCI) – basieren auf der Idee eines „Scale-out“, so dass Kapazitätserweiterungen durch Hinzufügen neuer Blöcke erreicht werden. Dies ist auch der Ansatz, den die sog. „Cloud-Scaler“ verfolgen, bei denen hunderte oder sogar tausende Mandanten, virtuelle Systeme und Anwendungen betrieben werden. Hier ist eine Optimierung oder ein Upgrade einer Einzelkomponente keine wirtschaftliche Option mehr, da der Aufwand in keiner Relation zum Leistungszuwachs steht. Hier ist es deutlich sinnvoller, „einfach noch ein paar Server“ zu kaufen, um die Umgebung zu erweitern. Als weiteren Bonus bieten einige konvergente Lösungen bereits Oberflächen an, mit denen (interne) Kunden sich virtuelle Maschinen, Anwendungsplattformen oder ganze Applikationen wie in der Cloud selbst zusammenstellen können. Natürlich ist hier eine gewisse Vorarbeit seitens der Betreiber der Lösung notwendig. Auch manche Prozesse und Genehmigungen werden immer noch länger dauern als eine „einfache“ Bestellung in der Cloud, aber meist können die vorhandenen Tools die Bereitstellungszeiten stark reduzieren. Zwar ist dies auch in bestehenden Umgebungen mithilfe zusätzlicher Software möglich, die Implementierung kann aber sehr viel aufwändiger sein als bei einer (H)CI-Umgebung, die die Software mitbringt.
Die Größe der Umgebung und wie schnell sie wächst
Bisher wurden bei den Einsatzszenarien CI und HCI in den meisten Bereichen als gleichwertig betrachtet. Es gibt aber, neben den technischen Rahmenbedingungen, ein Entscheidungskriterium, bei dem zwischen den beiden unterschieden werden kann und sollte: Die initiale Größe der Umgebung und das erwartete Wachstum.
In zunächst kleinen Umgebungen, in denen auch ein stetiges, aber überschaubares Wachstum erwartet wird, ist CI aus verschiedenen Gründen klar im Nachteil. Auf der einen Seite sind die Initialkosten für ein (teilweise oder vollständig) bestücktes Rack sehr hoch. Wenn nur ein sehr geringer Teil der Ressourcen einer CI-Lösung genutzt wird, ist eine Anschaffung nur schwer zu rechtfertigen. Bei Erreichen der Kapazitätsgrenze eines Blocks wiederholt sich dann die Herausforderung: Für ein Minimum an zusätzlich benötigter Leistung muss ein großer Block angeschafft werden.
HCI bietet hier einen wesentlich besser an die Anforderungen angepassten Ansatz: Man kann mit wenigen Systemen einsteigen und diese bei Bedarf durch einzelne Knoten erweitern, so dass sowohl Anschaffungs- als auch Erweiterungskosten begrenzt bleiben.
Genau andersherum sieht es natürlich in Umgebungen aus, die schon initial eine gewisse Größe haben, und bei denen der Bedarf an Ressourcen eher sprunghaft ansteigt. Hier kann CI die deutlich bessere Wahl gegenüber HCI sein.
Nicht zuletzt muss auch im Auge behalten werden, wie groß die Umgebung bis zum Ende ihrer Lebenszeit werden kann. HCI-Lösungen unterstützen typischerweise kleinere Maximalwerte für Storage-Kapazität und Compute-Ressourcen als CI-Lösungen.
Welche Lösung ist also die richtige für Sie? Ist eine konvergente oder hyperkonvergente Lösung überhaupt sinnvoll? Beantworten Sie folgende Fragen für sich selbst und schätzen den Einfluss auf den erfolgreichen Einsatz einer (hyper-)konvergenten Lösung ab:
- Welche Infrastruktur (Ethernet, FC, Backup) ist bei mir schon vorhanden?
- Wie sieht meine Teamstruktur aus?
- Welche Teile meiner Infrastruktur werden von externen Dienstleistern betrieben?
- Welche Anforderungen aus Sicht der IT-Sicherheit habe ich bezüglich der logischen und/oder physischen Trennung von Systemen und Diensten?
- Welche Workloads sehe ich in meiner neuen Umgebung?
- Wie groß ist meine geplante Umgebung und mit welchem Wachstum rechne ich?
Verweise
[1] M. Ermes, „VMware NSX in Theorie und Praxis“, Netzwerk-Insider, Juli 2019