Hintergrund dafür ist, dass die klassischen Schnittstellen letztlich für die Ansteuerung von drehenden Platten entwickelt wurden. Das Small Computer System Interface, genutzt im SAS und Fibre Channel, wurde bereits im Jahr 1986 vorgestellt. Anspruch von SCSI war und ist es, eine möglichst breite Palette von Peripheriegeräten steuern zu können. Dem entgegengesetzt wird von der PCIe Foundation der Standard NVMe entwickelt, um die vorhandene Leistungsfähigkeit von Festkörperspeichern optimal nutzen zu können.
Innerhalb eines Servers bzw. SAN-Speichers kann damit eine enorme Leistungssteigerung erreicht werden. Wie Abbildung 1 zeigt, führt die Anbindung von SSDs mittels NVMe zu einer deutlichen Reduzierung der Latenz.
Im Server können damit die vorhandenen Ressourcen bestmöglich ausgenutzt werden. Wird Speicherkapazität über ein Netzwerk zur Verfügung gestellt, muss dieses allerdings ebenfalls dazu in der Lage sein, die Vorteile von SSDs an den Server weiterzugeben.
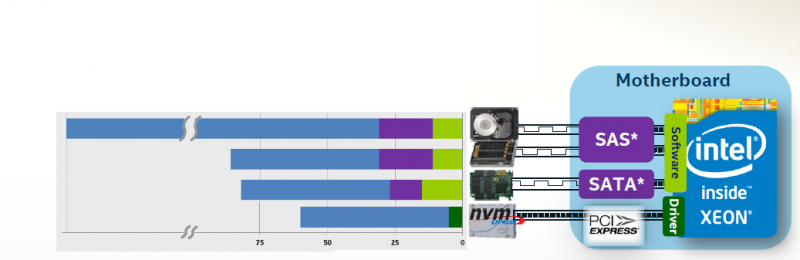
Abbildung 1: Kombinierte Festplatten-, Controller- und Software-Latenz bei der Nutzung von unterschiedlichen Schnittstellen. Quelle: communities.intel.com
Um NVMe over Fabric zu verstehen lohnt es sich, zunächst ein etwas detaillierteres Bild von NVMe zu zeichnen. Entwickelt wurde NVMe für die Datenübertragung auf dem leistungsfähigen PCIe-Bus. Ausgangspunkt war das von Intel im Jahr 2008 vorgestellte NVMHCI Protokoll welches, unter dem Vorsitz von Intel, schließlich durch den herstellerunabhängigen NVMe-Standard abgelöst wurde.
Die aktuell üblichen Form-Faktoren m.2 und u.2 erlauben eine Nutzung von bis zu 4 PCIe-Lanes für ein Endgerät. Für den PCIe 3.0 Standard sind also mit NVMe Netto-Übertragungsraten von annähernd 4 GB/s für eine SSD möglich. Mit der Adaption der, mittlerweile veröffentlichen, PCIe Version 4.0 wird sich diese Rate noch einmal verdoppeln. Selbst der 2017 publizierte SAS 4.0 Standard beschreibt eine maximale Bandbreite von lediglich knapp 3 GB/s.
Doch die limitierte Bandbreite ist nicht der einzige Nachteil der Technologien, welche auf SCSI basieren. Hinzu kommt nämlich noch, dass die Bandbreite nur bei seriellen Lesevorgängen erreicht wird. Insbesondere in einem virtualisierten Rechenzentrum kommt so etwas – mit der Ausnahme von Backups und Restores – aber nur sehr selten vor: Üblicherweise greifen die verschiedenen Virtuellen Maschinen (VMs) hochgradig zufällig auf Daten zu. Hier bietet NVMe den entscheidenden Vorteil einer Parallelisierung von Befehlen. Klassische drehende Platten können davon nicht profitieren – sie müssen den Lesekopf in die richtige Position bringen, um mit dem Auslesen beginnen zu können. Anders die Situation bei Festkörperspeichern: Hier sind der Parallelisierung durch die zu Grunde liegende Halbleitertechnologie nur wenige Grenzen gesetzt.
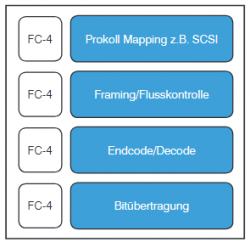
Abbildung 2: Protokollstapel im Fibre Channel Protocol
Hier setzt eben NVMe an. Wie der Name schon sagt, wurde NVMe für die Kommunikation mit nicht flüchtigem Arbeitsspeicher (Non Volatile Memory) entwickelt. Zum Zeitpunkt der Entstehung kamen die, auf NAND-Flash basierenden, SSD-Festplatten dem am nächsten. Mittlerweile drängen Technologien wie der von Intel und Micron entwickelte 3D Cross Point Speicher auf den Markt, welche das Potential haben, NAND-Flash in ihrer Performance noch zu übertrumpfen. Sofern sie über den PCIe-Bus mit der CPU kommunizieren – und nicht als DIMM noch näher an der Datenverarbeitung sitzen – nutzen auch diese Technologien NVMe. Aber das ist eine andere Geschichte.
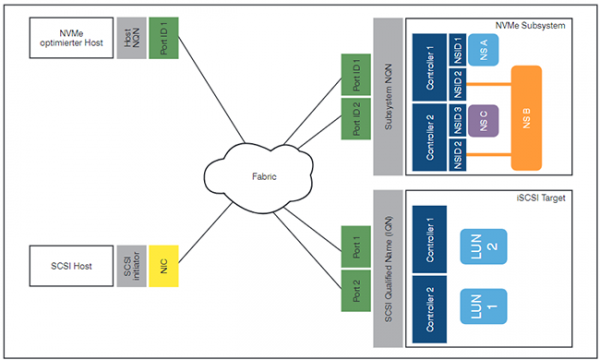
Interessanter ist die Frage, welche Vorteile der Quantensprung an Leistungsfähigkeit, den NVMe ermöglicht, für den Nutzer von zentralisiertem SAN-Speicher hat. Unter Nutzung der „traditionellen“ blockbasierten Netzwerkprotokolle fällt die Antwort relativ ernüchternd aus: Unabhängig davon, ob eine Fibre Channel Infrastruktur, Ethernet oder gar Infiniband im SAN zum Einsatz kommen, werden letztlich SCSI-Befehle übertragen. In Abbildung 2 sei als Beispiel für diese Technologie der Protokollstapel im klassischen Fibre Channel Protokoll dargestellt.
Klassischerweise werden SCSI-Befehle transportiert um entfernte Speichersysteme zu steuern. Die Möglichkeit zur parallelen Verarbeitung von Speicherbefehlen bleibt damit ungenutzt. Außerdem sind mittlerweile High-End-Speichersysteme verfügbar, die ausschließlich NVMe-SSDs nutzen. Wie in Abbildung 3 dargestellt, bedingt die Nutzung von SCSI-Befehlen eine – latenzbehaftete – Protokollumsetzung innerhalb des Zielspeichersystems.
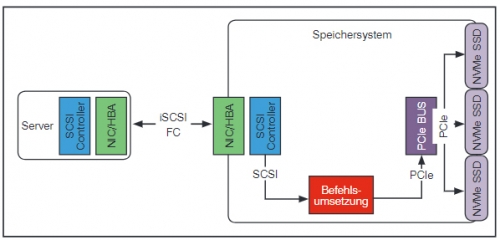
Abbildung 3: SAN-Kommunikation mit einem NVMe-Speichersystem unter Nutzung von SCSI-Befehlen
Um eine Nutzung von zentral verfügbarem NVMe-Speicher ohne Performance-Einbußen zu ermöglichen, wurde daher NVMe over Fabric (NVMe oF) entwickelt. Bereits im NVMe Standard der aktuellsten Version wird auf diese Technologie und ihre Unabhängigkeit vom Trägerprotokoll hingewiesen:
“The NVMeTM over Fabrics specification defines a protocol interface and related extensions to the NVMe interface that enable operation over other interconnects (e.g., Ethernet, InfiniBand™, Fibre Channel).”
Im Folgenden werde ich die zu Grunde liegenden Technologien genauer beleuchten, Umsetzungsvarianten beschreiben und mögliche Einsatzszenarien darstellen.
2. Die wichtigsten Unterschiede zwischen SCSI und NVMe
Vergleicht man in Abbildung 4 den SCSI-Protokollstapel (links im Bild) mit NVMe, kann man erkennen, dass NVMe auf einen „Treiberstapel“, wie er bei SCSI vorgesehen ist, verzichtet.
Im SCSI-Treiberstapel werden drei Schichten unterschieden:
- Der Upper Layer wird genutzt, um Filesysteme auf unterschiedlichen Geräteklassen einzurichten. Auch hier kann man erkennen, dass SCSI für ein sehr breites Anwendungsfeld entwickelt wurde: Es existieren fünf Hauptmodule (Disk, cdrom/dvd, tape, media changer und generic SCSI devices).
- Der Middle Layer dient zur Trennung der oberen und unteren Schicht. Hier werden Treiber aus dem „Lower Layer“ registriert und Befehle zwischen Upper und Lower Layer transportiert. Außerdem findet in dieser Schicht das „Error Handling“ statt. Vergleichbar mit TCP im Netzwerkstapel werden hier z.B. Retries initiiert, falls die Antworten aus dem Lower Layer nicht innerhalb des konfigurierten Timeouts eintreffen
- Im Lower Layer schließlich laufen die Hardware-Treiber von Geräten wie RAID-Controllern, SAS-Festplatten oder HBAs.
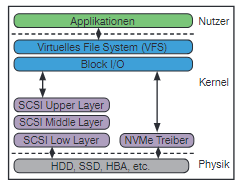
Abbildung 4: Vergleich des NVMe und SCSI im I/O-Stapel eines Linux Betriebssystems
Im Gegensatz dazu verzichtet NVMe auf einen Protokollstapel. Wie in Abbildung 4 dargestellt, wird der NVMe-Treiber direkter angesprochen. Diese „Verschlankung“ ist möglich, da im Prinzip nur eine Geräteklasse mit einem schmalen Spektrum an Eigenschaften unterstütz werden muss: Nicht flüchtiger Arbeitsspeicher. Laut Messungen von Intel[4] ist durch dieses Modell eine Verringerung der Latenz um mehr als 50 % möglich.
Eine Gemeinsamkeit zwischen SCSI und NVMe bleibt allerdings erhalten: Die Identifizierung von Speicherzielen mittels logischer Bezeichner. Im SCSI-Umfeld sind das die sogenannten Logical Unit Numbers (LUNs), welche von SAN-Speichern genutzt werden. Mit ihrer Hilfe wird die physikalische Kapazität der Datenträger für die Nutzer abstrahiert bereitgestellt. NVMe unterscheidet Speicherbereiche durch ihre „Namespace ID (NSID)“. Wie in Abbildung 5 dargestellt, können die Namespaces dabei sowohl einem Controller exklusiv zugeordnet werden als auch von mehreren Controllern gleichzeitig genutzt werden. Eine mögliche Anwendung davon wären z.B. dual homed SSDs wie sie auch mit SAS möglich sind. Mit deren Hilfe kann z.B. zusätzliche Ausfallsicherheit innerhalb des Speichersystems oder Servers erreicht werden.
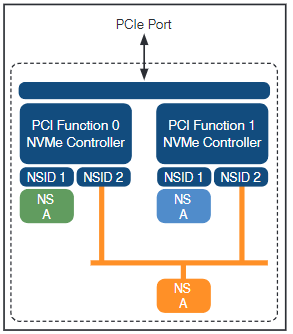
Abbildung 5: Zwei NVMe Controller, die jeweils auf einen privaten (NSID 1 und 3) und einen geteilten Namespace (NSID 2) zugreifen. Quelle: NVM Express Base Specifi cation Revision 1.3c 24. Mai 2018
Die Vielzahl an unterstützten Geräteklassen hat eine weitere Konsequenz für SCSI: Mehr als 140 Befehle stehen zur Verfügung. Dazu zählen z.B. „Move Medium“ oder „Play Audio“ die für NVMe aller Wahrscheinlichkeit nach keine Rolle spielen werden. Der NVMe Befehlssatz ist daher deutlich schlanker: Es können 26 Befehle genutzt werden, um die Hardware zu steuern. Von diesen Befehlen müssen mindestens 10 Admin- und 3 I/O-Kommandos (Lesen, Schreiben, Flush (verschiebt Daten aus flüchtigen in nicht flüchtige Bereiche)) genutzt werden. D.h. der minimale Befehlssatz enthält lediglich 13 Einträge.
Die wahrscheinlich entscheidendste Neuerung von NVMe allerdings ist die eingangs erwähnte Möglichkeit zur Parallelisierung von Kommandos. Theoretisch sind bis zu 64.000 parallele I/O-Warteschlangen mit jeweils bis zu 64.000 Kommandos möglich. Einen besonderen Vorteil bietet diese Architektur in Mehrkernarchitekturen. Wie in Abbildung 6 dargestellt ist es möglich, jedem Kern dedizierte Warteschlangen zuzuweisen.
Dabei wird zwischen der „Submission Queue“ – Befehle die vom Anforderer versendet wurden – und der „Completion Queue“ – den Antworten des Speichers – unterschieden. Es ist möglich, einer Completion Queue mehrere Submission Queues zuzuordnen (vgl. Abbildung 6 core 1). Außerdem sind spezifische Interrupts (MSI-X) je Warteschlange möglich, wodurch die Effektivität und die Auslastung der CPU weiter optimiert werden: Können z.B. Daten in einer der Warteschlangen von der SSD geliefert werden, müssen nicht alle Prozessorkerne gestoppt werden um die Daten abzurufen, sondern nur der für diese Warteschlange verantwortliche. Darüber hinaus ist es möglich, die unterschiedlichen Warteschlangen durch Prioritäten zu unterscheiden.
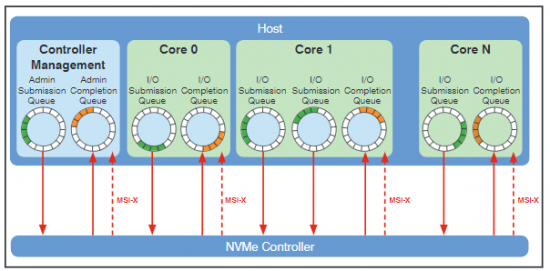
Abbildung 6: I/O-Submission und Completion Queues (Warteschlangen) die unterschiedlichen Prozessorkernen zugeordnet sind. Quelle: NVM Express Inc.
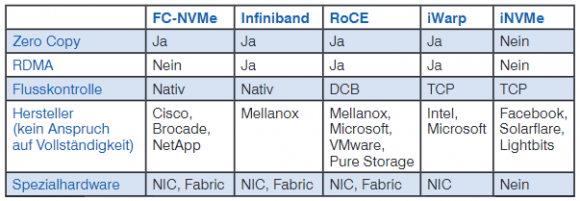
In der Tabelle 1 sind noch einmal die wesentlichen Unterschiede zwischen SCSI und NVMe zusammengefasst.
In einer Testinstallation wurde von IBM der aktuell erreichbare Performance-Unterschied zwischen NVMe und SATA (Serial ATA, neben SAS eine weiterer Standard, der ebenfalls weit verbreitet ist) gemessen. Die Ergebnisse sind in Abbildung 7 dargestellt. Hier werden SATA-und NVMe-Devices (Flash und 3DXpoint/Optane) einmal über den „Umweg“ Linux-Kernel und einmal direkt aus der Applikation angesprochen. Damit wird zum einen klar, wie groß der Vorteil von NVMe gegenüber SATA ist. Außerdem kann in dieser Messung gezeigt werden, dass die direkte Anbindung eine deutliche Steigerung der IOPS ermöglicht.
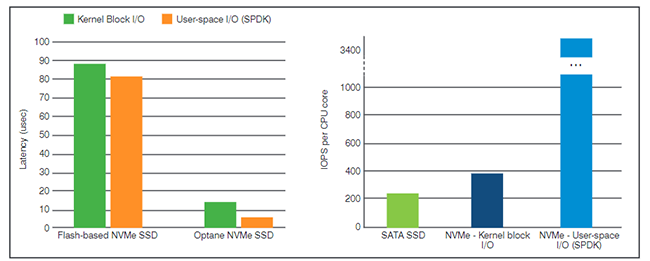
Abbildung 7: Vergleich von Latenz und erreichten IOPS von NVMe SSDs, Optane NVM und SATA. Die Devices sind entweder über den Linux-Kernel oder direkt über die Applikation angebunden (Kernel Block vs. User Space). Quelle: IBM Redbooks: IBM Storage and the NVM Express Revolution. I. Koltsidas, Vincent Hsu, 2017
In absoluten Zahlen scheint die Verringerung der Latenz für Flash-Speicher nicht so beeindruckend. Kommen allerdings neue Speichertechnologien wie Intel Optane (3D-XPoint) zum Einsatz, wird die Latenz aufgrund des niedrigen Basiswertes auf weniger als 10 µs halbiert.
3. Übertragungsprotokolle
3.1 Was muss die Fabric leisten?
Entwickelt wurde NVMe für die Übertragung auf dem PCIe Stack. Im Gegensatz zu SAS ist PCIe bereits als Fabric ausgelegt. Dadurch ist die Implementierung von NVMe auf einer alternativen Fabric vergleichsweise einfach. In Abbildung 8 ist beispielhaft der im Standard definierte Protokollstapel dargestellt.
Konsequenz dieser Architektur – in Kombination mit den in Abbildung 6 dargestellten Warteschlangen – ist, dass einzelne CPU Kerne über eine Fabric auf Daten einer SSDs zugreifen können (Abbildung 9).
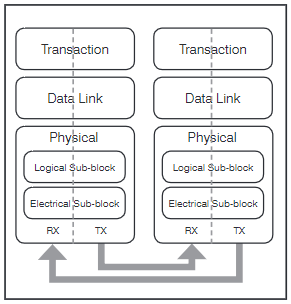
Abbildung 8: High-Level-Diagramm des PCIe Protokollstapels. Quelle: PCI Express ® Base Specifi cation Revision 3.0 November 10, 2010
Um nun die Leistungsfähigkeit von NVMe-Festplatten über größere Distanzen nutzbar zu machen, ist eine zu PCIe alternative Fabric-Technologie erforderlich. Neben den generellen Vorteilen eines SAN (auf die wir hier nicht näher eingehen), spricht auch die enorme Leistungsfähigkeit von NVMe SSDs dafür. Einzelne Server sind in vielen Fällen gar nicht dazu in der Lage, die I/O-Performance von NVMe SSDs zu nutzen. Würde man z.B. nur die Hälfte der 128 PCIe Lanes einer modernen AMD EPYC CPU mit NVMe SSDs „bestücken“, könnte man die CPU (theoretisch, wenn man z.B. RAID-Verfahren außen vor lässt) mit bis zu 63 GB/s an Daten „überfluten“. Daher kann eine Zentralisierung der, meist noch vergleichsweise teuren, NVMe-Speicher durchaus Sinn machen.
Im Prinzip wäre es möglich, PCIe als Netzwerkprotokoll zu nutzen. Allerdings sprechen dafür weder eine breite Produktauswahl – aktuell ist die Firma Dolphin mit der IX-Produktfamilie einer der wenigen Hersteller für PCIe-Netzwerktechnologie – noch belastbare Praxiserfahrungen. Darüber hinaus skaliert die Anbindung von SSDs über PCIe schlecht. Glücklicherweise gibt es sehr etablierte Protokolle, die ihre Eignung für die Anbindung von zentralen Speichersystemen auch und vor allem im unternehmenskritischen Umfeld vielfach nachgewiesen haben. Unglücklicherweise steht der Anwender weiterhin vor der Qual der Wahl: Für alle im Unternehmens-SAN üblicherweise eingesetzten Protokolle wurde NVMe over Fabric (NVMe-oF) von unterschiedlichen Herstellern implementiert.
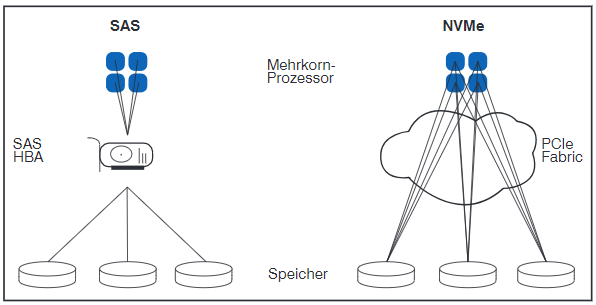
Abbildung 9: Zugriff auf Daten mit SAS und NVMe
Das zugrundeliegende Schichtenmodell ist in Abbildung 10 dargestellt. Der NVMe over Fabrics Standard, aus dem diese Abbildung entnommen ist, beschreibt lediglich die NVMe spezifischen Änderungen, die erforderlich sind, um die Speicherkommunikation zu entfernten Zielen aufzubauen. Das entspricht der obersten Schicht in der Abbildung. Behandelt werden dort z.B. zusätzliche Befehle oder Änderungen in den Warteschlangen-Mechanismen.
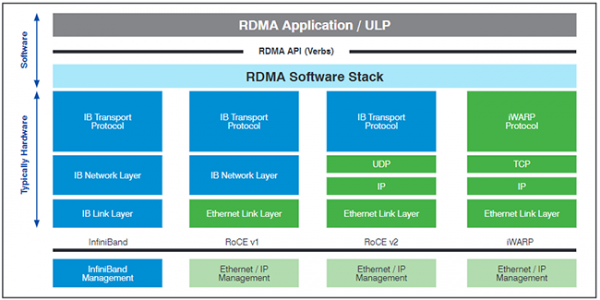
Fabric-spezifische Eigenschaften werden in den „Transport Binding Specifications“ z.B. für Fibre Channel (FC-NVMe) oder Ethernet (NVMe over RoCE, NVMe over iWARP) beschrieben.
Unabhängig von der Fabric ist der Verbindungsaufbau zwischen Host und NVMe-Subsystem. Als Subsystem wird – analog zur NVMe-Basis-Spezifikation – einer oder mehrere Controller verstanden, welche Zugriff auf die Namespaces ermöglichen (siehe z.B. auch Abbildung 5). Die Subsysteme wiederum sind über Ports, die durch ihre 16-bit Identifier und einen sogenannten NVMe Qualified Name (NQN) beschrieben sind, mit der Fabric verbunden. Baut der Host nun eine Verbindung mit einem Controller auf, sendet er zunächst ein „Fabrics Connect“ Kommando. Darin sind der 16-bit Host-Identifier, der eigene und der Remote-NQN enthalten. Optional kann noch eine In-Band-Authentisierung genutzt werden, um die Sicherheit im Speichernetz zu erhöhen.
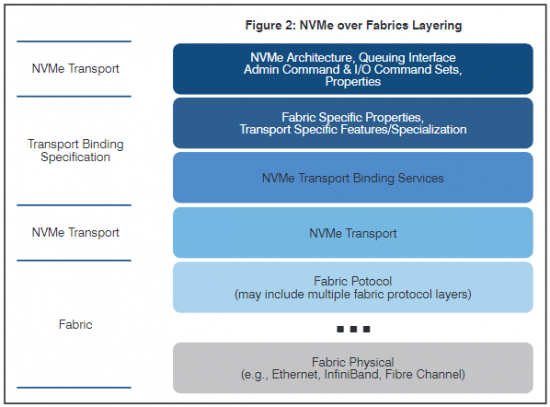
Abbildung 10: Schichtenmodell von NVMe over Fabric. Quelle: NVM Express over Fabrics Revision 1.0a 17. Juli 2018
In Abbildung 11 ist der resultierende Aufbau dargestellt. Zusätzlich in der Abbildung enthalten ist ein Discovery Service. Dieser kann – ähnlich z.B. dem Domain Name System im IP-Umfeld – genutzt werden, um zentral Informationen über die Erreichbarkeit von Subsystemen bereitzustellen.
Welche Voraussetzungen muss nun eine Fabric mitbringen, um NVMe-oF zu ermöglichen bzw. was muss zusätzlich implementiert werden?
- Verlustfreiheit ist die wichtigste und eine zwingende Anforderung an ein Speichernetz, das zur Übertragung von Datenblöcken genutzt wird. Der NVMe-oF Standard verlangt lediglich „reliable NVMe command and data delivery“. D.h. eine zuverlässige, verlustfreie Übertragung der Kommandos und Daten. In den relevanten Speicherprotokollen kommen dafür unterschiedliche Methoden zur Flusskontrolle zum Einsatz.
- Zero-Copy beim Zugriff auf entfernte Daten ist eine Fähigkeit, welche die Vorteile von NVMe optimal nutzt. D.h. es ist eine vorteilhafte, aber keine zwingende Anforderung. Zero Copy bedeutet, dass beim Übertragen von Daten keine DRAM zu DRAM Kopien innerhalb des Quell- bzw. Zielsystems erforderlich sind. Damit wird die CPU entlastet, da sie bei einem Kopiervorgang beteiligt wäre, und die Latenz verringert. Anstatt Zero Copy zu nutzen, arbeiten Protokolle wie TCP Socket-basiert. D.h. im Rahmen des Verbindungsaufbaus werden beim Sender und beim Empfänger Pufferbereiche im Arbeitsspeicher definiert. In Abbildung 12 a) ist die Übertragung unter Nutzung des TCP/IP-Stapels dargestellt. In einem ersten Schritt werden die relevanten Daten im DRAM vom Anwendungsbereich in den TCP/IP-Puffer kopiert. Auf diese Daten erhält die NIC Zugriff und kopiert sie in den eigenen Puffer. Von dort werden sie zum Zielhost übertragen. Am Ziel läuft derselbe Vorgang in umgekehrter Richtung ab. In Abbildung 12 b) erhält die NIC direkten Zugriff auf den DRAM-Bereich der Applikation. Womit auf einen Kopiervorgang innerhalb des Arbeitsspeichers verzichtet werden kann.
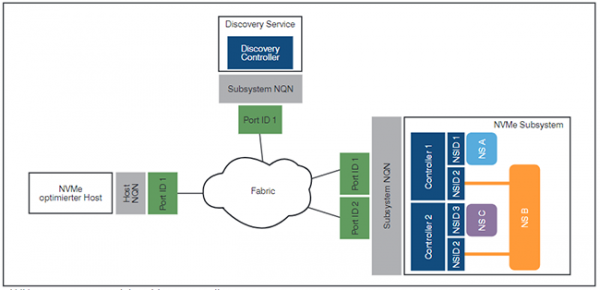
Abbildung 11: NVMe over FabricRevision 1.0a 17. Juli 2018
Bei der Nutzung von NVMe-oF werden sogenannte „Scatter Gather Lists (SGL)“ übertragen, die den Ort der benötigten Daten im Arbeitsspeicher beschreiben. D.h. für Schreibvorgänge zeigt die SGL auf die Speicherbereiche, die auf die SSD geschrieben werden sollen. Für Lesevorgänge zeigt die SGL die Speicherbereiche an, in die von der SSD geschrieben werden soll.
Übertragen werden die SGLs zusammen mit den Kommandos in sogenannten „Capsules“. Dabei wird zwischen Command-Capsules (Host → NVMe-Subsystem) und Response-Capsules (NVMe-Subsystem → Host) unterschieden. Wie in Abbildung 13 dargestellt enthalten die Capsules sowohl die Submission/Completion Queue Entries (SQE/CQE, siehe auch Abbildung 6) als optional auch Daten bzw. SGLs.
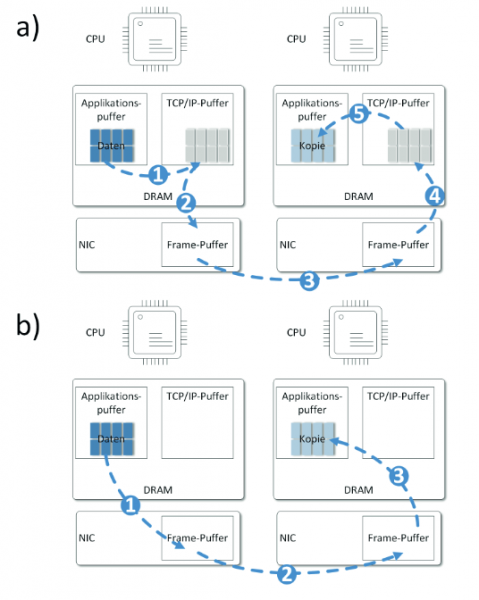
Abbildung 12: Übertragen von einem Quell- zu einem Zielhost. In a) fi ndet die Übertragung Socket basiert über den TCP/IP-Stack mittels einer DRAM-Kopie statt. In b) erhält die NIC direkten Zugriff auf den entsprechenden Speicherbereich. Nach “The Future of Flash: NVMe over Fibre Channel”, Brocade Dell/EMC-World 2017
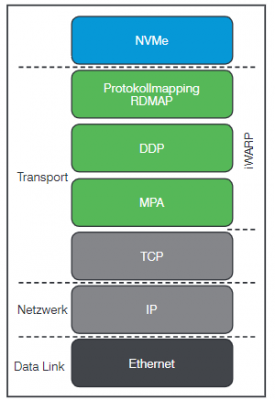
Im NVMe-oF-Standard sind sowohl der Transport von Daten in Capsules (“Message-Based”) als auch der direkte Speicherzugriff („Memory-Based”) zugelassen. Auch eine Kombination der beiden Varianten ist zulässig. Die genaue Spezifikation der SQEs bzw. CQEs sind im Transport-Binding beschrieben.
3.2 NVMe over Fibre Channel
Wie in Abbildung 2 zu sehen, wurde Fibre Channel für den Transport von SCSI entwickelt. Anzunehmen, dies ist eine „exklusive Verbindung“ wäre allerdings falsch. Fibre Channel wurde von Beginn an dafür entwickelt, als Transportbasis für Speicherprotokolle zu dienen. So wurden frühe Implementationen z.B. genutzt um ESCON zu übertragen. Auch dessen Nachfolger FICON wird mittels Fibre Channel transportiert. Zum Austausch des Speicherprotokolls muss lediglich die FC-4-Schicht angepasst werden. In der NVMe-Terminologie entspricht das dem Transport-Binding aus Abbildung 10.

Abbildung 13: Command und Response Capsule. Quelle: NVM Express over Fabrics Revision 1.0a 17. Juli 2018
Standardisiert wird NVMe over Fibre Channel (FC-NVMe) vom T11 Komitee des „International Committee on Information Technology Standards
(INCITS)”, welches auch für die restlichen Fibre Channel Standards verantwortlich zeichnet. Die finale Version des FC-NVMe Standards wurde im April dieses Jahres veröffentlicht.
Ein entscheidender Vorteil für Anwender, die bereits ein Fibre Channel SAN auf dem Stand der Technik (Gen 5 oder 6) betreiben, ist, dass keine neue Hardware erforderlich ist um FC-NVMe zu implementieren. Einzige Ausnahme ist natürlich das neue Storage Array bzw. die NVMe-Festplatten in den Storage Hosts. In Abbildung 14 ist dargestellt, wie das Mapping von NVMe SQEs, Daten und CQEs auf Fibre Channel Information Units realisiert wird.
Die bereits erwähnten Anforderungen „Verlustfreiheit“ und „Zero Copy“ werden in einem Fibre Channel SAN, unabhängig vom übertragenen Speicherprotokoll, ohne weitere Modifikationen erfüllt. Ohne im Detail darauf einzugehen sei das Aushandeln von „Buffer Credits“ beim Fabric Login erwähnt. Je nach Fibre Channel Service Klasse wird damit eine Ende-zu-Ende- oder eine Port-zu-Port-Flusskontrolle ermöglicht: Die Datenquelle sendet nur so viele Pakete, wie vom Empfänger mindestens verarbeitet werden können. Bis eine „Receive Ready Meldung“, d.h. das O.K. zum Weitersenden, eingegangen ist, wird die Transmission unterbrochen. Auf diese Art und Weise wird das Verwerfen von Paketen aufgrund von vollständig gefüllten Puffern vermieden. Auch die Zero-Copy-Funktion (der FC-HBA greift direkt auf die Daten im Arbeitsspeicher zu, die übertragen werden müssen) ist im Fibre Channel Protocol bereits enthalten.
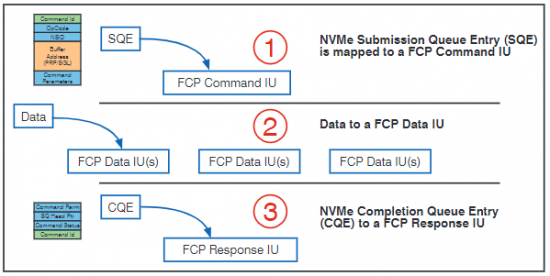
Abbildung 14: Mapping von NVMe zu Fibre Channel. Quelle J. Metz, Let’s Talk „Fabrics“, SNIA 27.6.2018 17. Juli 2018
Durch seine große Verbreitung in Unternehmensnetzwerken und den geringen Modifikationsaufwand scheint Fibre Channel also eine naheliegende Wahl, um NVMe-oF zu implementieren. Wichtig dafür ist auch, dass in einem bestehenden SAN die Koexistenz von SCSI over FC und NVMe over FC (FC-NVMe) problemlos möglich ist. Bestehende Hardware kann also parallel zu leistungsfähigem NVMe-Speicher weiter genutzt werden, ohne Netzwerkkomponenten wie NICs austauschen zu müssen. Bereits im Jahr 2016 wurden erste FC-NVMe-Demonstrationen gezeigt (Flash Memory Summit Santa Clara CA). Dieses Jahr wurden bereits die ersten Produkte der großen Speicherhersteller vorgestellt. Beispielhaft sei das NetApp AFF A700 Array erwähnt, das mit der Einführung des ONTAP 9.4 Dateisystems FC-NVMe ermöglicht.
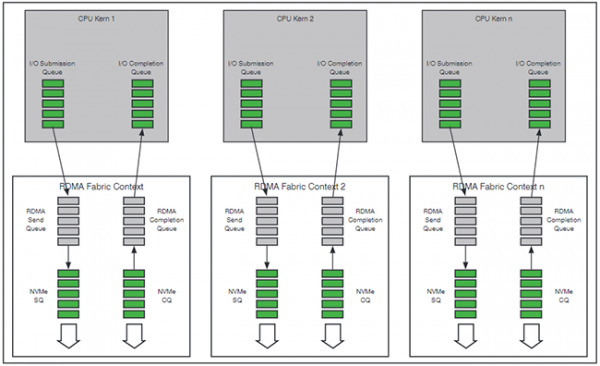
Abbildung 15: Zuordnung von NVMe SQEs und CQEs zu den RDMA Completion Queues (CQ)
3.3 NVMe over Infiniband
Im Vergleich zu den im Rechenzentrum etablierten Protokollen Ethernet und auch Fibre Channel ist Infiniband mit seiner Markteinführung Anfang der 2000er Jahre relativ jung. Entwickelt wurde Infiniband für Umgebungen, in denen allerhöchste Performance erforderlich ist. Laut Herstellerangaben sind mit Infiniband-Switches Port-zu-Port-Latenzen von weniger als 90 ns bei Bandbreiten von 200 Gbit pro Sekunde und Port möglich.
Wichtigster Grund Infiniband – als vergleichsweise exotische Technologie – hier zu erwähnen, ist die „Remote Direct Memory Access (RDMA)“ Implementierung. RDMA wurde entwickelt, um über das Netzwerk auf den Arbeitsspeicher eines entfernen Hosts zugreifen zu können. Ursprüngliches Einsatzszenario für RDMA ist, genauso wie für Infiniband, das High Performance Computing auf einer großen Anzahl von parallelen Hosts. Im Zusammenhang mit NVMe-oF ermöglicht RDMA, wie oben gefordert, die Übertragung von Daten über das Netzwerk ohne eine DRAM-zu-DRAM-Kopie zu erstellen (Zero Copy). Auch wenn RDMA für Infiniband entwickelt wurde, stellt es die Grundlage für die beiden wichtigsten Ethernet-Varianten von NVMe-oF dar, aber dazu später mehr.
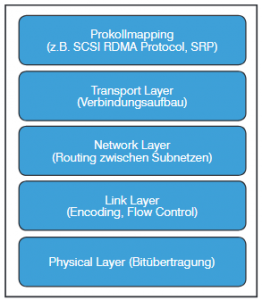
Abbildung 16: Infi niband Protokollstapel
RDMA stellt den Applikationen sogenannte „Verbs“ als Application Programming Interface (API) zur Verfügung. Diese Verbs werden von den RDMA-fähigen NICs bzw. HCAs zur Speicherkommunikation genutzt. D.h. es wird, wie auch für NVMe over Fabric vorgesehen, auf Basis von Messages kommuniziert. Die Zuordnung der Verbs erfolgt, wie in Abbildung 15 dargestellt, zu den entsprechenden Warteschlangen. Bei der Nutzung von RDMA wird dabei zwischen „Work Queues“, zu denen auch „Send Queues“ zählen, und Completion Queues unterschieden. D.h. am NVMe-Modell sind keine Modifikationen erforderlich um RDMA zu nutzen, die Zuordnung von Warteschlangen-Paaren zu CPU-Kernen kann erhalten bleiben. Außerdem ist keine Anpassung von Applikationen erforderlich, die bereits RDMA nutzen. Dazu zählt z.B. Storage Spaces Direct im Microsoft Windows Umfeld oder auch der Linux-Kernel.
Wie alle modernen Netzwerkprotokolle nutzt auch Infiniband einen Protokollstapel mit Schichten, die unterschiedliche Funktionen bei der Kommunikation zwischen Applikationen erfüllen. In Abbildung 16 ist zu erkennen, dass Infiniband, wie auch Fibre Channel, zur Übertragung von Speicherbefehlen geschaffen wurde. Auch im Fall von Infiniband stand von Anfang an die Möglichkeit zum direkten Zugriff auf den Host DRAM durch die Netzwerkkarte im Vordergrund.
Das SCSI RDMA Protocol (SRP) z.B. ermöglicht die direkte Nutzung von SCSI-Geräten mittels RDMA. Die Adaption für NVME-oF ist also auch für das Infiniband-Protokoll mit vergleichsweise geringem Aufwand verbunden.
Auch die Anforderung – reliable NVMe command and data delivery – ist dank der Infiniband-Flusskontrolle gegeben. Die im Link-Layer implementierte Flusskontrolle sorgt dafür, dass ein Paketverlust aufgrund von überfüllten Warteschlangen vermieden wird. Sender und Empfänger tauschen permanent Informationen zum Status der Pakete und zum „Credit Limit“ d.h. zum noch verfügbaren Puffer aus. Dafür werden sogenannte „Credit Packets“ genutzt, die in Hardware verarbeitet werden. Um die Zuverlässigkeit des Transports zusätzlich zu erhöhen, werden außerdem zwei Mechanismen zur Erkennung von Bitfehlern genutzt: Zum einen – wie in anderen Netzwerkprotokollen auch – eine Checksumme für den unveränderlichen Teil der Pakete. Diese zyklische Redundanzprüfung (Invariant Cyclic Redundancy Check, ICRC) wird durch einen weiteren Prüfschritt für das gesamte Paket – einschließlich der veränderlichen Teile im Header – ergänzt. Durch die VCRC (Variant CRC) können Übertragungsfehler auf einer Hop-zu-Hop Basis erkannt werden. Dafür wird die VCRC Checksumme vor jedem Netzwerk-Hop neu berechnet, ICRC hingegen unterstützt bei der Ende-zu-Ende Kontrolle der Daten.

Abbildung 17: NVMe Techdemo von IBM auf dem AI Summit New York, 5.- 6. Dezember 2017
Wie schon erwähnt wird Infiniband auch und vor allem im High Performance Computing genutzt. In diesem Umfeld spielen Latenz und Übertragungsraten eine besonders große Rolle. Daher ist es nicht erstaunlich, dass frühe Technologiedemonstrationen zu NVMe-oF mit Infiniband durchgeführt wurden. So zeigte z.B. IBM Ende 2017 auf dem AI Summit in New York eine Ende-zu-Ende Implementierung von NVMe over Fabric (Abbildung 17).
3.4 NVMe over Ethernet
Ethernet hat sich als Netzwerktechnologie durchgesetzt. Dieses Statement gilt für viele Bereiche, das Rechenzentrum und den Campus eingeschlossen. Die Gründe dafür sind vielfältig: Hohe Bandbreiten von mittlerweile (zumindest in der Theorie) bis zu 400 Gbit/s pro Port, eine breite Herstellerunterstützung und eine gewaltige installierte Basis. Bei vielen Servern werden mittlerweile 10 GE Ports auf dem Mainboard mitgeliefert. Selbst im Speicherbereich – mit dem Platzhirsch Fibre Channel – konnte Ethernet mittels iSCSI, NFS und FCoE einen signifikanten Marktanteil erreichen.
Zur Flusskontrolle wird im Ethernet typischerweise TCP eingesetzt. Als „General Purpose Protokoll“ leidet der vielfach erprobte, aber auch etwas behäbige TCP/IP Stapel unter gewissen Einschränkungen in der Performance. TCP/IP kann zwar in Hardware verarbeitet werden, trotzdem bleibt der Nachteil der Speicherbereichskopien (Abbildung 4). Die iSER (iSCSI Extensions for RDMA) Erweiterung hat sich an dieser Stelle nicht durchgesetzt. Stattdessen wurden zwei Ansätze standardisiert, um RDMA auf einer Ethernet-Fabric zu übertragen: RDMA over Converged Ethernet (RoCE) und Internet Wide-area RDMA Protocol (iWARP).
Beide Varianten können genutzt werden, um NVMe über Ethernet zu etablieren. Allerdings sind dafür spezielle, RDMA-fähige Ethernet-Adapter erforderlich. Diese Tatsache hat zur Gründung einer NVMe Working Group geführt, die sich mit der Standardisierung von NVMe over TCP (iNVMe) befasst. Unterstützt wird diese Variante unter anderem von Schwergewichten wie DellEMC und Facebook, das an einer Weiterentwicklung seiner Lightning JBOF (Just a Bunch of Flash) Plattform interessiert ist. Die verschiedenen Optionen werden im Folgenden vorgestellt.