Symptomatik eines Angriffs
Das Schwachstellenmanagement bietet die Grundlage für Risikoanalysen und präventive Sicherheitsmaßnahmen. Eine effektive Gefahrenabwehr geht jedoch darüber hinaus und muss in der Lage sein, Angriffe frühzeitig zu erkennen. Dazu muss betrachtet werden, welche Symptome bei einem Angriff auftreten. Auf dieser Basis wird entschieden, welche Parameter für die Überwachung von Bedeutung sind.
Einerseits sind hier handfeste IoCs zu nennen, die eine hohe Aussagekraft besitzen und auf einen konkreten Vorfall hindeuten. Die Feststellung solcher Symptome muss sofort zu einem Alarm seitens des SIEM führen und mit einem hohen Gewicht in die Risikoanalyse einfließen. Andererseits können auch unspezifische Symptome auftreten, aus denen zwar kein konkreter Vorfall, aber zumindest eine Anomalie erkennbar ist. Je nach Ausprägung sollte das SIEM hierbei eine Warnung ausgeben und die gesammelten Informationen im Rahmen der Risikoanalyse weiter berücksichtigen. Im Folgenden sind einige Beispiele für Symptome aufgelistet, die darauf hindeuten können, dass ein Server in der Cloud das Ziel eines Angriffs ist.
Anmeldeversuche
Fehlgeschlagene Anmeldeversuche können Hinweise darauf sein, dass ein unautorisierter Benutzer versucht, sich Zugang zu einem System zu verschaffen. Treten sie gehäuft und in kurzen zeitlichen Abständen auf (bspw. mehrmals pro Sekunde), sind sie ein sicheres Zeichen für einen Angriff. Anmeldevorgänge können ebenfalls in Zusammenhang mit Ort und Zeit gebracht werden. Finden sie von Quell-IP-Adressen aus anderen Ländern oder außerhalb der üblichen Geschäftszeiten statt, ist dies zumindest verdächtig.
Versuch einer SQL-Injection
Wird die Kommunikation einer Server-Anwendung von einer Web Application Firewall (WAF) überwacht, kann diese zur Erkennung von Versuchen einer SQL-Injection konfiguriert werden. Wenn z.B. in einem Anmeldeformular Zeichen eingegeben werden, die nicht als Teil eines Nutzernamens erlaubt sind (etwa Hochkommata, Gleichheitszeichen oder Klammern), kann dies von der Applikation gemeldet und von der WAF im Rahmen von Virtual Patching blockiert werden.
Anormales Nutzerverhalten
Proxys wie Secure Web Gateways (SWG) und WAFs analysieren Anwenderverhalten und sind in der Lage, anormales Nutzerverhalten zu erkennen. Kommuniziert ein Benutzer auf nicht vorgesehene Art mit einer Anwendung, kann dies auf missbräuchliche Verwendung hindeuten.
Rule Matches bei Firewalls
Verbindungen, die gegen das Regelwerk einer Firewall verstoßen, werden von dieser blockiert. Bei Mikrosegmentierung des Netzwerks und Einsatz von Detailregeln kann so die Kommunikation innerhalb der Netzwerk-Infrastruktur feingranular kontrolliert werden. Blockierte Verbindungen können Hinweise auf Sicherheitsvorfälle liefern.
Hinweise auf Malware-Infektion
Die Infektion eines Systems mit Malware kann sich in unterschiedlichen Symptomen äußern. Diese betreffen einerseits die Kommunikation des Systems. Zur Analyse kann ein IDS (Intrusion Detection System) eingesetzt werden, welches z.B. feststellen kann, dass ein System mit einem Command-and-Control-(C2-)Server kommuniziert. Andererseits treten auch Symptome im Zusammenhang mit dem Arbeitsspeicher und Dateisystem auf. Diese können von einem Virenscanner überwacht werden, der auf Basis von Signaturen und Verhaltensanalyse nach Malware sucht.
Änderung der Konfiguration
Bestimmte Änderungen an der Konfiguration von Servern können Hinweise auf Eindringlinge oder Malware geben. Diese Hinweise werden lokal, bspw. im Windows Event Log, protokolliert. Verdächtige Konfigurationsänderungen umfassen z.B. das Löschen von Regeln der Host-basierten Firewall oder die Deaktivierung des lokalen Virenscanners.
Auffällige Daten aus Systemmetrik
Ungewöhnliche Leistungsdaten eines Servers können ein Hinweis auf die Präsenz eines Angreifers sein. Auffällig sind vor allem eine hohe Prozessor- und Speicherauslastung, die nicht anhand gewöhnlicher Vorgänge plausibilisiert werden können.
Alle beschriebenen Symptome werden üblicherweise in Log-Dateien protokolliert. Beispielsweise sind Firewalls in der Lage, blockierte Verbindungen zu protokollieren. All diese Log-Dateien können dem SIEM zur Verfügung gestellt werden, welches dadurch einen umfassenden Blick über sicherheitsrelevante Ereignisse innerhalb der gesamten Infrastruktur erhält. Durch diese zentrale Position bei der Überwachung kann das SIEM eine Korrelation zwischen einzelnen Ereignissen herstellen. Somit können Angriffsmuster erkannt werden, indem Symptome an verschiedenen Stellen des Netzwerks miteinander korreliert werden.
Abwehrmaßnahmen bei Vorfällen und Anomalien
Das SIEM nimmt nicht nur eine zentrale Position bei der Erkennung von Angriffen ein, sondern auch bei der Umsetzung von Abwehrmaßnahmen. Dabei kann es auf unterschiedliche Weise zur Gefahrenabwehr beitragen.
In jedem Fall nimmt das SIEM eine passive Rolle ein. Hierbei steht die Alarmierung im Fall eines Incident im Vordergrund. Die Nutzer des SIEM, typischerweise die Security Analysts eines Security Operation Centers (SOC), bearbeiten die Meldungen des SIEM. Dabei wird zunächst geprüft, ob es sich um einen False Positive handelt. Ist dies nicht der Fall, beginnen die zuständigen Security Analysts mit der Verteidigung der Assets oder leiten diese Aufgabe an ein Incident Response Team weiter.
Zusätzlich zur Alarmierung können sich einige SIEM-Lösungen auch aktiv an den Abwehrmaßnahmen beteiligen, indem sie sie automatisch veranlassen und koordinieren. Dazu kommunizieren sie über dedizierte APIs (Application Programming Interfaces) mit angeschlossenen Sicherheitslösungen. Rule Matches und Alarme des SIEM können so an Befehle gekoppelt werden, die über diese Schnittstellen automatisch auf den Sicherheitssystemen abgesetzt werden.
Das automatische Einleiten von Sicherheitsmaßnahmen verkürzt die Reaktionszeit bei Incidents und wirkt sich damit positiv auf die Schadensbegrenzung aus. Allerdings sind solche Prozesse auch mit Risiken verbunden. So können auch dann Aktionen ausgelöst werden, wenn es sich bei einem Alarm um einen False Positive handelt. Die resultierenden Defensivmaßnahmen können den Betrieb innerhalb der Cloud massiv stören und die Verfügbarkeit der Systeme stark einschränken. Es sollte daher für jeden Einzelfall abgewogen werden, wie hoch das Risiko von unnötigen Betriebsstörungen ist und ob es durch die effektivere Schadensbegrenzung gerechtfertigt wird. Ein Mittelweg kann bei dieser Abwägung auch die Kopplung von aktiven Abwehrmaßnahmen des SIEM an eine manuelle Freigabe sein. Das Absetzen von Befehlen muss dabei durch einen autorisierten Benutzer bestätigt werden.
Ein klassisches Beispiel für aktive Maßnahmen eines SIEM ist z.B. die Änderung der Konfiguration einer Firewall. Wird ein Sicherheitsvorfall oder eine Anomalie beobachtet, ist das SIEM in der Lage, die Aktivierung von Regeln zu veranlassen, durch die das betreffende System von anderen Teilen des Netzwerks isoliert wird.
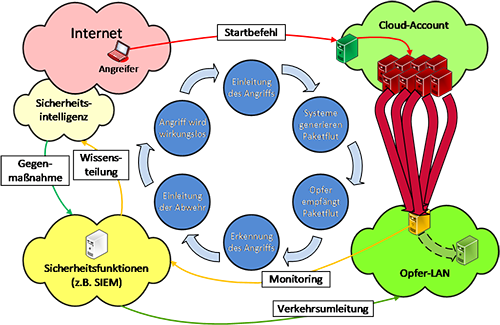
Im Falle einer DDoS-Attacke kann das SIEM als aktive Maßnahme die Umleitung des Verkehrs zu einem Scrubbing-Center einleiten. Ist es die eigene Cloud-Infrastruktur, die Teil des Angriffs ist, so ist es möglichdirekt vor kompromittierten Systemen eine Firewall-Regel zu erstellen, die das Verschicken von Traffic zum Angriffsziel unterbindet. Abbildung 2 skizziert die verschiedenen Phasen vom Beginn einer DDoS-Attacke bis zum Ergreifen von Gegenmaßnahmen durch das SIEM.
Vernetzung von SIEM und Cloud
Damit das SIEM Cloud-Komponenten überwachen kann, müssen entsprechende Kommunikationswege geschaffen werden. Hierbei gibt es verschiedene Möglichkeiten, Informationen aus der Cloud an das SIEM zu leiten.
Eine dieser Möglichkeiten besteht darin, SIEM-eigene Kollektoren in der Cloud zu betreiben. Diese sammeln Informationen von Cloud-Komponenten und leiten sie an das SIEM weiter. Ob ein einzelner oder mehrere Kollektoren eingesetzt werden, hängt dabei von der Architektur des SIEM und der Beschaffenheit der Cloud-Umgebung ab. Dies betrifft ebenso den Umfang eventueller Vorverarbeitung der Daten, etwa in Form von Filterung, Normalisierung und Kompression. In jedem Fall müssen die Daten jedoch gebündelt und verschlüsselt werden, bevor sie an das SIEM geschickt werden. Die Untersuchung der Daten auf IoCs findet bei dieser Möglichkeit erst bei Auswertung der Daten durch das SIEM statt.
Bei der zweiten Möglichkeit wird innerhalb der Cloud eine eigene Sicherheitsinfrastruktur betrieben. Das bedeutet, dass man die bekannten und bewährten Mittel der Sicherheitskomponenten (Firewalls, Proxies, …) in der Cloud-Infrastruktur aufbaut. Die Erkenntnisse dieser Sicherheitskomponenten werden anschließend dem SIEM gemeldet. Diese Methode bietet den Vorteil, dass dem SIEM Sensoren zur Verfügung gestellt werden können, deren Fähigkeiten die Analysemethoden des SIEM deutlich verfeinern können. Beispielsweise kann innerhalb der Cloud ein IDS (Intrusion Detection System) bzw. NIDS (Network Intrusion Detection System) betrieben werden, für das dann ein maßgeschneidertes Regelwerk entwickelt werden kann, mit dem Daten zielgerichteter nach Treffern durchsucht werden, als es mit dem SIEM-Regelwerk alleine möglich wäre.
Denkbar ist auch eine Mischung dieser beiden Möglichkeiten. Dabei werden sicherheitsrelevante Daten sowohl durch die Sicherheitsinfrastruktur in der Cloud als auch durch das SIEM selbst geprüft. Dieses korreliert dann seine eigenen Erkenntnisse mit den Auswertungen der angeschlossenen Sicherheitslösungen. Den vielfältigen Analysemöglichkeiten stehen hier jedoch ein größerer Konfigurationsaufwand und höhere Datenmengen gegenüber, die einen Anstieg der Lizenzkosten für das SIEM mit sich bringen können.
Konfiguration des SIEM
Wie effektiv ein SIEM im Zusammenspiel mit anderen Sicherheitslösungen die Server in einer Cloud schützen kann, hängt vor allem von der Konfiguration ab. Die hohe Kunst ist es, dabei die individuellen Anforderungen und Eigenarten aller Systeme so genau wie möglich mit der Konfiguration abzudecken. Gleichzeitig müssen jedoch auch möglichst viele Eventualitäten mit generischer Logik abgebildet werden. Hierbei kommt es vor allem auf ein adäquates Regelwerk, passende Schwellwerte bzw. deren automatische Justierung, ausgereifte Modelle für Maschinelles Lernen und verlässliche Threat Intelligence an.
Im Folgenden werden einige Aspekte zur Konfiguration des SIEM für das behandelte Angriffsszenario beschrieben:
Analyse von Log-Daten
Das klassische Einsatzgebiet eines SIEM ist die Auswertung von Log-Daten. Einschlägige Daten-Quellen sind dabei vor allem die Log-Daten von Sicherheitselementen wie Firewalls, exponierte Server und Server mit hohem Schutzbedarf sowie Gateways und Server für administrative Zugänge. Bei einem Angriff können mit hoher Wahrscheinlichkeit an all diesen Systemen Symptome beobachtet werden. Für das Regelwerk des SIEM sollten Alarme für folgende Ereignisse konfiguriert werden:
- Hohe Anzahl fehlgeschlagener Anmeldeversuche
- Verwendung von nicht erlaubten Ports und Protokollen, z.B. Port 23 / Telnet
- Treffer für Signaturen bei Host-basierten Virenscannern
- Veraltete Softwareversionen
- Befunde von Schwachstellenscannern
Analyse von Paketen
Die Kontrolle von Paketströmen ist im Allgemeinen eine sinnvolle Ergänzung zur Auswertung von Log-Daten. Einige SIEM-Lösungen bieten hierzu eigene, dedizierte Komponenten an. Alternativ oder zusätzlich können externe IDS-Lösungen angebunden werden. Alarme sollten für folgende Fälle konfiguriert werden:
- Hohe Netzlast
- Treffer für Signaturen bei IDS-Regelwerken
- Kommunikation mit nicht erlaubten IP-Adressen
Bestimmte Regeln des SIEM- bzw. IDS-Regelwerks sind an die Messung bestimmter Werte gekoppelt. Damit entschieden werden kann, wann die Anzahl fehlgeschlagener Anmeldeversuche bzw. der Datendurchsatz zu hoch sind, müssen geeignete Schwellwerte festgelegt werden. Ein Überschreiten des jeweiligen Schwellwerts führt dann zu einem Alarm. Während bei Anmeldeversuchen allgemeine Annahmen getroffen werden können (z.B. sind mehrere Versuche pro Sekunde stets ein bedenkliches Ereignis), ist dies im Fall der Netzlast schwieriger. Hierbei kommt es darauf an, auf Basis individueller Gegebenheiten sinnvolle Schwellwerte zu definieren und im Verlauf anzupassen. Dies kann durch kontinuierliche Reviews oder auch automatisch durch das SIEM geschehen.
Ein hilfreiches Mittel zur Bestimmung des individuellen Normalzustands ist Maschinelles Lernen (ML). Durch den Einsatz von ML erlernt das SIEM selbständig, welche Parameter-Konstellationen im Normalbetrieb gegeben sind, indem es über mehrere Iterationen ein Modell aufbaut. Mit jeder weiteren Iteration wird dieses Modell genauer und ermöglicht verlässlichere Aussagen bei der automatischen Erkennung von Anomalien. Im Fall der Netzlast könnten Berechnungen mit dem Modell Auskunft darüber geben, ob in bestimmten Bereichen des Netzwerks ungewöhnlich viele Daten übertragen werden oder anderweitig verdächtige Kommunikation stattfindet.
Teil der SIEM-Konfiguration ist ebenfalls die Auswertung von Threat Intelligence. Allgemein ist es empfehlenswert, stets mehrere Quellen zu abonnieren und Meldungen zu deduplizieren. Es existieren auch Feeds, die selbst bereits ein Destillat anderer Feeds sind. Interessant ist vor allem Threat Intelligence, die solide IoCs zu DDoS-Attacken und Malware-Infektionen liefert. Im Verlauf sollte individuell betrachtet werden, welche Threat Intelligence Feeds wichtige Informationen geliefert haben. Feeds, die sich längerfristig als eher uninteressant erwiesen haben, sollten eventuell wieder abbestellt werden.
Aufarbeitung von Sicherheitsvorfällen
Nicht immer können Angriffe auf die eigene Infrastruktur erkannt, geschweige denn verhindert werden. Angriffe bleiben besonders dann unerkannt, wenn für neuartige Angriffsmuster noch keine aussagekräftige IoCs bekannt sind. Im Zuge der Verbesserung der eigenen Verteidigung gilt es auch, aus Fehlern möglichst viel zu lernen.
Es lohnt sich daher, einschlägige Log-Daten längerfristig zu archivieren. Dies ist nicht nur für forensische Untersuchungen interessant, sondern auch für erneute Analysen im Rahmen von historischer Korrelation. Dabei werden neue Erkenntnisse genutzt, um zu ermitteln, ob man in der Vergangenheit Opfer eines Angriffs gewesen ist, der seinerzeit nicht bemerkt wurde.
Wird bspw. bekannt, dass eine Institution das Ziel eines DDoS-Angriffs gewesen ist, sollte kontrolliert werden, ob zum Zeitpunkt dieses Angriffs von den eigenen Systemen viele Daten an die IP-Adressen dieser Institution übertragen worden sind. Im besten Fall kann im Nachgang ermittelt werden, wie man den Vorfall hätte erkennen und verhindern können. Auf Basis dieser Erkenntnisse ist es dann möglich, die aktuelle Verteidigung zu verbessern.
Fazit
DDoS-Attacken können jeden treffen. Damit man selbst nicht Opfer einer solchen Attacke wird, gilt es, eine effektive Verteidigung aufzubauen. Dabei sollte man ebenfalls Szenarien abdecken, in denen die Server in der eigenen Cloud von Angreifern verwendet werden, um das eigentliche Ziel zu attackieren.
Im Zusammenspiel mit anderen Sicherheitslösungen kann ein SIEM eine zentrale Rolle bei der Verteidigung einnehmen. Dabei hilft es, Sicherheitsvorfälle zu erkennen und Abwehrmaßnahmen zu koordinieren. Darüber hinaus kann das SIEM zur Archivierung von einschlägigen Log-Daten genutzt werden und Unterstützung bei der Aufarbeitung vergangener Vorfälle leisten.
Abwehrmaßnahmen sind jedoch nur dann wirkungsvoll, wenn alle Sicherheitskomponenten im Verbund arbeiten. Die Konfiguration des SIEM und die Anpassung auf die individuellen Gegebenheiten der eigenen Infrastruktur sind dabei von entscheidender Bedeutung.
Quellen
[TrendMicro_DDoS] – https://blog.trendmicro.com/trendlabs-security-intelligence/multistage-attack-delivers-billgates-setag-backdoor-can-turn-elasticsearch-databases-into-ddos-botnet-zombies/
[BSI_Lagebericht2019] – https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Publikationen/Lageberichte/Lagebericht2019.pdf
[Insider-Artikel_ SecOps] – „SecOps: Operative Informationssicherheit“ in Der Netzwerk Insider vom Juni 2019


