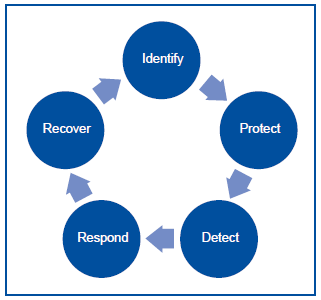
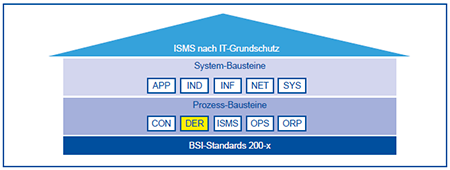
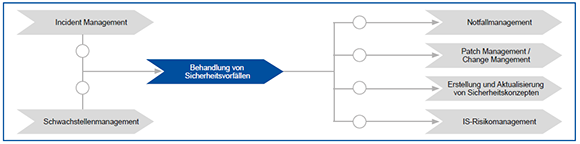
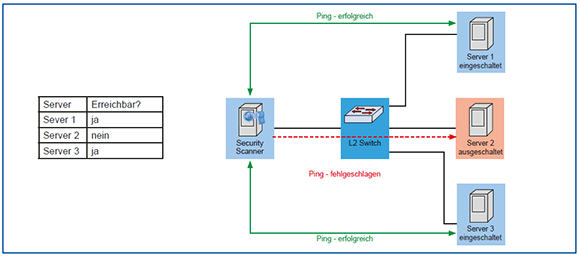
3. Einsatz von Schwachstellen-Scannern
Die gängigen Schwachstellen-Scanner erkennen Sicherheitslücken von diversen Komponenten. Diese beinhalten sowohl Server als auch Netzwerk- und Sicherheitskomponenten sowie Appliances. Durch die zunehmende Verbreitung von IoT-Geräten werden auch diese mittlerweile von Schwachstellen-Scannern unterstützt, sofern sie über das reguläre (IP-)Netzwerk erreichbar sind.
Produktbeispiele sind unter anderem Nessus, Qualys und das Open Vulnerability Assessment System (OpenVAS).
Der Ablauf eines typischen Schwachstellen-Scans, der auch die Sicht eines potentiellen Angreifers simuliert, teilt sich normalerweise in folgende Schritte auf:
- Erkennen von erreichbaren Systemen
- Netzwerk-Port-Scan (TCP und UDP) der entdeckten Systeme
- Scan der erkannten Dienste auf bekannte Schwachstellen
- Darstellung der Ergebnisse
Wichtig hierbei ist, dass Schwachstellen-Scanner nur bekannte Sicherheitslücken erkennen. Ein Schwachstellen-Scanner ist kein Wundermittel, das auch alle Zero-Day-Exploits erkennt!
In den folgenden Abschnitten soll kurz erläutert werden, wie die einzelnen Arbeitsschritte funktionieren.
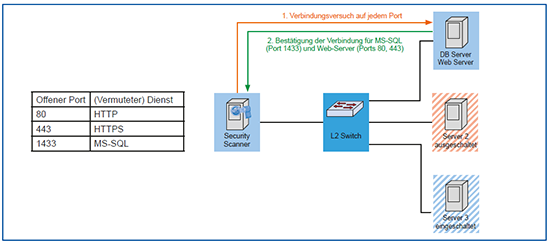
Erkennen von erreichbaren Systemen: Die Erkennung von erreichbaren Systemen funktioniert im Allgemeinen über ICMP Echo Requests (Pings). Dabei kann man entweder eine Liste von Zielen (IP-Adressen) oder ganze Subnetze überprüfen lassen (siehe Abbildung 4). Sollten Systeme auf Pings nicht reagieren, so gibt es auch die Möglichkeit, ein Ziel als immer erreichbar zu markieren, so dass auch ohne vorherigen Erreichbarkeitstest sowohl Port- als auch Schwachstellen-Scans durchgeführt werden.
Port-Scan: Alle erreichbaren Systeme werden darauf überprüft, welche Dienste sie anbieten. Dabei ist ein Dienst in der Regel mit jeweils mindestens einem Netzwerk-Port (TCP oder UDP) gleichbedeutend. Ein Schwachstellen-Scanner überprüft eine Liste von vorgegebenen Ports auf Erreichbarkeit und trifft Annahmen zu den darüber erreichbaren Diensten (siehe Abbildung 5). Dabei sind sowohl die Portlisten als auch die Korrelation zu üblichen Diensten variabel und wirken sich stark auf die Dauer eines Port-Scans aber auch auf die Dauer des eigentlichen Schwachstellen-Scans aus.
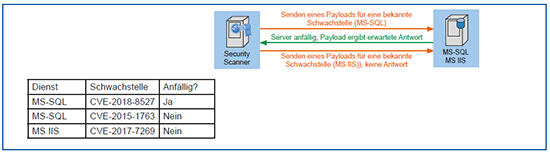
Schwachstellen-Scan: Mit den Ergebnissen der vorherigen Schritte können dann die vorhandenen Schwachstellen überprüft werden (siehe Abbildung 6). Wie bereits erwähnt können hier im Allgemeinen nur bereits bekannte Schwachstellen erkannt werden. Welche bekannten Sicherheitslücken überprüft werden können hängt dabei maßgeblich vom Hersteller des jeweiligen Tools ab. Sowohl die Geschwindigkeit, mit der bekannte Lücken eingepflegt werden, als auch die Genauigkeit der Tests spielen hier eine Rolle bei der Wahl des richtigen Anbieters.
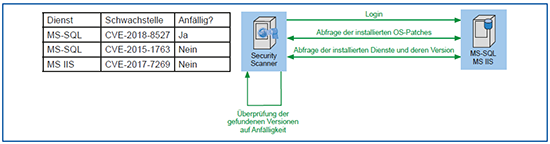
Agenten-basierter Scan und Scan mit Login-Daten: Als Alternative oder als Ergänzung eines klassischen Black-Box-Scan über das Netz können auch Agenten auf dem Zielsystem oder Login-Daten für das jeweilige Ziel eingesetzt werden. Diese sammeln die Daten direkt auf dem Zielsystem und melden diese an den zentralen Schwachstellen-Scanner. Dabei werden hauptsächlich die Versionen der installierten Software mit einer Liste von bekannten Schwachstellen abgeglichen. Diese Art der Überprüfung ist normalerweise schneller als ein Scan von außen. Das Beispiel per Login ist in Abbildung 7 dargestellt. Der Vorteil hier ist, dass nicht nur von außen erreichbare Dienste, sondern auch interne Abhängigkeiten auf Sicherheitslücken überprüft werden. Dies ermöglicht, auch mögliche indirekte Angriffe auf weitere Software besser zu erkennen. Ein solcher Scan per Login ist in vielen Fällen auch auf Netzwerkkomponenten und Appliances möglich, ein Einsatz von Agenten ist im Allgemeinen nur auf Servern und/oder Endgeräten möglich, sofern der Hersteller des Schwachstellen-Scanners für das jeweilige Betriebssystem einen Agenten anbietet.
Konfigurations- und Compliance-Checks: Einige Lösungen (z.B. Nessus) sind in der Lage, die Konfiguration von Servern und Netzwerkkomponenten zu überprüfen. Die eigentliche Überprüfung funktioniert per Login, überprüft allerdings nicht den Versionsstand der installierten Software, sondern die Konfiguration von (dem Scanner bekannten) Diensten. Beispiele hierfür sind Netzwerk-Switches oder Firewalls. Dabei werden die ermittelten Konfigurationen einerseits auf sicherheitsrelevante Aspekte überprüft. Eine typische Einstellung, die hier als unsicher eingestuft wird, ist die Aktivierung von Telnet zur Administration von Netzwerkkomponenten. Andererseits können Konfigurationsparameter gegen eine Liste von guten oder schlechten („known good“ und „known bad“) Werten abgeglichen werden. Grundlage der Prüfungen sind dabei auch die Empfehlungen der Hersteller für sichere Konfigurationen ihrer Produkte. Dabei muss aber beachtet werden, dass solche Tests im Allgemeinen nicht umfassend sind und anfällig für False Positives und False Negatives sein können.
Darstellung der Ergebnisse: Die im Rahmen eines Scans ermittelten Schwachstellen müssen dem Nutzer und den Systemverantwortlichen verständlich dargestellt werden. Dazu unterstützen alle gängigen Scanner die Erstellung von Reports mit diversen Filtereinstellungen. Typischerweise werden die Administratoren der Scanner-Infrastrukturen alle Informationen erhalten wollen. Das evtl. involvierte Management ist aber normalerweise nur an kritischen Sicherheitslücken interessiert, die eine unmittelbare Bedrohung für den produktiven Betrieb darstellen. Ein Systemadministrator möchte vielleicht wissen, welche ausnutzbaren Schwachstellen auf seinem System vorhanden sind, ohne Meldungen beachten zu müssen, die lediglich Informationen zum System beinhalten. Dazu erlaubt ein Schwachstellen-Scanner sowohl eine Filterung nach System als auch nach Schwere der Sicherheitslücke. Für Letzteres hat sich die Nutzung des Common Vulnerability Scoring System (CVSS) durchgesetzt.
Mögliche Architekturen für den Aufbau des Schwachstellen-Scanners
Nach der Erläuterung der Funktionsweise eines Schwachstellen-Scanners ergibt sich die Frage: Wo in meinem Netz positioniere ich meinen Schwachstellen-Scanner?
Da ein Schwachstellen-Scan weitreichenden Netzzugriff ggf. auf viele Zielsysteme benötigt, muss auch die Positionierung des Schwachstellen-Scanners genau geplant sein. Es wird dabei davon ausgegangen, dass das Netz segmentiert ist, die Kommunikation zwischen den Segmenten mit einer Firewall geschützt wird und zumindest die folgenden Netzwerkbereiche existieren:
- DMZs im Perimeter-Bereich (Internet-Anbindung)
- Segmente (Sicherheitszonen) im internen Netzwerk
- Separierung der Management-Systeme in dedizierten Segmenten (Managementnetz)
Die häufigsten Architekturen für die Positionierung des Schwachstellen-Scanners sind:
Zentraler Scanner: Hier wird ein Scan-System eingesetzt, das im Managementnetz (ggf. in einem eigenen Segment) verortet ist und auf der Firewall entsprechend weitreichenden Zugriff auf alle Zielsysteme erhält. Bei einer Lizenzierung pro Scanner ist dies die günstigste Option, allerdings muss die Hardware evtl. größer dimensioniert werden.
Satelliten-Scanner in jedem Netzsegment: Hier befindet sich in jedem Netzsegment ein „kleiner“ Scanner, der die Ziele in seinem Segment scannt und die Ergebnisse an einen zentralen Management-Server im Managementnetz übermittelt. Diese Lösung minimiert den Traffic zur internen Instanz und benötigt keine weitreichenden Freischaltungen zwischen verschiedenen Segmenten. Je nach Lizenzierungsmodell können hier allerdings hohe Kosten auftreten.
Vulnerability-Scanning-as-a-Service: Dies entspricht einem Schwachstellen-Scan aus der Cloud. Externe Scans aus der Sicht des Angreifers sind hiermit sehr einfach umsetzbar, allerdings muss für die Überprüfung von internen Systemen ein Cloud-Konnektor lokal installiert werden, welcher dann Zugriff auf die internen Systeme erhält. Die Aktualität der Schwachstellendatenbank ist hier am ehesten gegeben. Die Lizenzierung erfolgt im Allgemeinen pro Scan-Ziel und kann so bei einer großen Anzahl von Systemen sehr kostenintensiv werden.
Betriebliche Aspekte beim Einsatz von Schwachstellen-Scannern
Das Wissen über die vorhandenen Sicherheitslücken, wie es im ersten Unterkapitel beschrieben ist, ist zwar der technisch aufwendigere Aspekt, aber betrieblich ist der Umgang mit den gefundenen Schwachstellen wesentlich komplexer.
Ein besonders aufwendiger Aspekt, speziell bei der Einführung von Schwachstellen-Scans in bestehenden Umgebungen, ist die Klassifizierung der existierenden und neuen Systeme. Diese Klassifizierung beinhaltet:
- Zulässige Scan-Tiefe
Die im letzten Kapitel beschriebenen Netzwerk-Scans sollten zwar theoretisch keinen Ausfall der Zielsysteme verursachen, aber manche Systeme sind bezüglich ihrer Netzwerkanbindung nicht robust entwickelt. So gibt es immer wieder Systeme, die beispielsweise bei der Verarbeitung eines falsch geformten IP-Pakets abstürzen können. Auch produktive Systeme, deren Verfügbarkeit als unternehmenskritisch eingestuft wird, dürfen eventuell gar nicht oder nur mit geringer Tiefe gescannt werden. Daher ist es üblich, tiefgehende Scans in einer Testumgebung vorzunehmen, die möglichst genau der Konfiguration der Produktivumgebung entspricht.
- Scan-Frequenz
Auch die Häufigkeit von Scans muss für jedes System festgelegt werden. Dieser Aspekt gestaltet sich aber etwas einfacher, weil man einen sinnvollen Standardwert für alle Systeme vorgeben kann, von dem nur in Ausnahmefällen abgewichen werden sollte.
Die Durchführung der Scans muss ebenfalls klar definiert und dokumentiert werden, um eine Vergleichbarkeit von aufeinanderfolgenden Scans zu ermöglichen. Der vielleicht wichtigste Aspekt beim Einsatz eines Schwachstellen-Scanners ist aber der Umgang mit den gefundenen Schwachstellen jenseits des reinen Reports. Hier muss bewertet werden, wer für das Schließen einer Sicherheitslücke verantwortlich ist und welche Fristen eingehalten werden müssen.
4. Log Management
Log-Management (LM) ist ein Begriff, der die Zusammenführung, Speicherung und Verwaltung von Log-Daten beschreibt. Die hierzu gesammelten Daten sind oft textbasiert und entstammen verschiedenen Quellen innerhalb einer IT-Infrastruktur. Als Quellen dienen sowohl über IP erreichbare Geräte eines Netzwerks als auch Anwendungsinstanzen. Zum automatisierten Management von Log-Daten werden spezielle LM-Lösungen angeboten.
LM-Lösungen können in verschiedenen Betriebsformen realisiert werden. Üblich ist der Betrieb als lokal installierte Software. Alternativ werden auch vermehrt Cloud-Lösungen angeboten. Neben kommerziellen Produkten ist auch ein vergleichsweise großes Angebot an freier Software verfügbar.
Von Komponenten der IT-Infrastruktur erzeugte Log-Daten fließen (z.B. per Syslog) von der Quelle zum zentralen LM und werden dort gespeichert. Dabei werden sie entweder direkt von der Quelle oder über einen speziellen Kollektor bezogen. Dieser dient als eine dem LM vorgeschaltete Instanz, die die Log-Daten an das zentrale LM weiterleitet. Der Kollektor kann dabei auch als funktionale Schnittstelle genutzt werden, die die Rohdaten zur Weiterverarbeitung umformatiert oder vorab filtert. Die gesammelten Log-Daten werden in einer Datenbank oder in einer Ordnerstruktur abgelegt. Zur effizienteren Durchsuchbarkeit wird von den Rohdaten häufig ein Index erstellt. Hierbei handelt es sich um eine zusätzliche Datenstruktur, die das Durchsuchen der Daten um ein Vielfaches beschleunigt. Häufig werden die Rohdaten zur Einsparung von Speicherplatz komprimiert.
Dem operativen Benutzer des LM wird eine Oberfläche zur Verfügung gestellt, mit der auf gespeicherte Informationen zugegriffen werden kann. Ein wesentlicher Bestandteil sind Suchfunktionen, die auch komplexe Abfragen ermöglichen. Zusätzlich können oft Dashboards erstellt werden, auf denen Trendanalysen, statistische Auswertungen oder Alarme dargestellt werden können. Der Zugriff auf die Oberfläche wird üblicherweise durch die Abfrage von Zugangsdaten gesichert.
Produktbeispiele für LM-Lösungen sind: Graylog, Quest InTrust und Splunk.
5. Security Information and Event Management (SIEM)
SIEM beschreibt eine Technologie zur Überwachung von sicherheitsrelevanten IT-In-
frastrukturen und Systemen. Ziel ist sowohl das Management von sicherheitsbezogenen Log-Daten als auch die Detektion von Angriffen und anderen Sicherheitsvorfällen. Ein SIEM bezieht dazu Daten aus zu überwachenden Geräten. In einem SIEM werden oft von zumindest folgenden Systemen die Ereignis-Logs erfasst:
- Sicherheitselemente (Firewalls, IPSs, ….)
- Exponierte Server, die als Einstiegspunkt für Angriffe dienen können
- Server mit hohem Schutzbedarf
- VPN-Gateways / Access Gateways
- PAM-Systeme
Deren aufgezeichnete Daten werden in einer zentralen Komponente gesammelt, konsolidiert und analysiert. Dies ermöglicht eine zunächst ähnlich zu einer LM-Lösung übersichtliche und einheitliche Darstellung von Informationen aus verschiedenen Quellen und unterschiedlichen Formaten. Entscheidend ist jedoch für ein SIEM die Fähigkeit, Log-Daten system- und anwendungsübergreifend zu korrelieren und zu analysieren.
Im Laufe der Zeit haben sich SIEM-Lösungen stetig weiterentwickelt, um aktuellen Anforderungen weiterhin gerecht werden zu können. Ähnlich zu Firewalls hat sich auch hier der Begriff „Next-Gen SIEM“ etabliert [8]. Next-Gen SIEM-Lösungen sollen durch den Einsatz von Big-Data-Techniken einen wirkungsvollen Schutz vor modernen Cyber-Attacken bieten. Hierbei spielt vor allem der Einsatz von KI eine entscheidende Rolle.
Produktbeispiele sind: IBM QRadar, Splunk, LogRythm und Micro Focus ArcSight.
Technische Funktionsweise
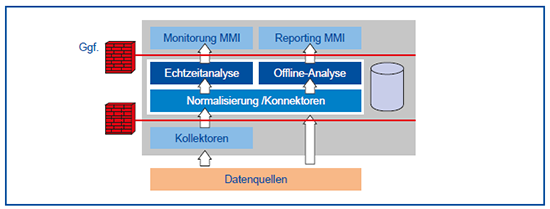
Die allgemeine Architektur eines SIEM-Systems zeigt die Abbildung 8. Es ist deutlich, dass es eine sichtbare Ähnlichkeit zu LM-Lösungen gibt, jedoch ist z.B. die Normalisierung unterschiedlicher Quellen eine entscheidende Eigenschaft.
Auf technischer Ebene sammelt ein SIEM zur Analyse Log-Daten aus verschiedenen Quellen. Diese umfassen laufende Anwendungen, Systeme und Endgeräte (Server aber ggf. auch Clients). Besonders interessant sind hierbei Sicherheitskomponenten wie z.B. Firewalls und Gateways sowie Infrastruktur-Komponenten wie Router und Switches. Die dort generierten Log-Daten werden über Kollektoren oder andere Schnittstellen an die zentrale Instanz des SIEM weitergeleitet.
Die Rohdaten, die in unterschiedlichen Formaten vorliegen können, werden anschließend normalisiert. Dazu werden die Daten inhaltlich ausgewertet und anhand eines gemeinsamen Formats neu strukturiert. Einerseits ermöglicht dies eine einheitliche und übersichtliche Darstellung der Informationen. Andererseits ist es durch die Zusammenführung einfacher, Querbezüge zwischen den Daten herzustellen. Bei der Analyse der Daten kommen, ähnlich wie bei einer Firewall, Regelwerke zum Einsatz. Über Regeln können Bedingungen definiert werden, ab wann ein Ereignis als problematisch, kritisch oder verdächtig einzustufen und wie dabei zu reagieren ist. Informationen werden bei der Analyse nicht nur isoliert betrachtet, sondern zu einem umfassenderen Gesamtbild kombiniert. Dies geschieht durch die Korrelation von Ereignissen. Während manche Ereignisse an unterschiedlichen Orten einzeln unauffällig erscheinen, können sie gemeinsam betrachtet dabei helfen, kritische Vorfälle zu identifizieren [9].
Werden Vorfälle entdeckt, kann je nach Schwere unterschiedlich reagiert werden. Die Art der zu treffenden Maßnahme kann dabei als Teil des Regelwerks festgeschrieben werden. Unkritische oder zunächst harmlose Vorkommnisse können beispielsweise lediglich gespeichert werden, sodass sie in Zukunft noch einmal berücksichtigt werden können. Eine Benachrichtigung des zuständigen Administrators wäre hierbei noch nicht nötig. Problematische Ereignisse dagegen können Warnungen hervorrufen und veranlassen, dass z.B. eine E-Mail an einen Administrator geschickt wird. Dieser kann sich zeitnah um das Problem kümmern. Wird ein Angriffsversuch erkannt, könnte ein Alarm außerdem via SMS an den Administrator versendet werden, sodass er sofort aktiv wird.
Funktionsumfang
Der Funktionsumfang eines SIEM setzt sich aus Security Information Management (SIM) und Security Event Management (SEM) zusammen.
SIM behandelt vorwiegend den Umgang mit Log-Daten aus verteilten Quellen. SIM ist mit LM vergleichbar, bezieht sich jedoch konkret auf den Bereich Informationssicherheit. Sinngemäß liegt jedem SIEM auch ein spezialisiertes LM zugrunde.
SEM befasst sich mit Echtzeit-Überwachung und Incident Management unter sicherheitstechnischen Aspekten. Der Benutzer soll dadurch ein Werkzeug erhalten, das kontinuierlich ein aktuelles Lagebild der IT-Infrastruktur liefert. Hierdurch sollen Probleme rechtzeitig erkannt und Reaktionszeiten auf ein Minimum reduziert werden. Probleme umfassen dabei kritische und verdächtige Ereignisse sowie Angriffe und Angriffsversuche. Der Begriff „Echtzeit“ ist hier insofern zu verstehen, dass Ereignisse unmittelbar nach ihrem Auftreten analysiert werden. Im Optimalfall meldet das überwachte System betreffende Informationen unverzüglich an das SIEM, welches sie sofort verarbeitet. Die Zeitspanne vom Auftreten des Ereignisses bis zu dessen Erkennung wird hierbei wesentlich durch die Dauer anfallender Rechenoperationen, Lese- und Schreibzugriffe sowie Übertragungsgeschwindigkeiten bestimmt. Ist das überwachte System oder das SIEM so konfiguriert, dass Informationen nur in periodischen Zeitintervallen übertragen werden, fallen hierfür zusätzlich entsprechende Zeitenspannen an.
Der zuvor dargelegte Umfang der Basisfunktionen wird von SIEM-Lösungen zumeist um zusätzliche Funktionen erweitert. Beispiele sind:
- Inspizieren von Netzwerkverkehr: Ähnlich einer Firewall und einem IPS sind manche SIEM-Lösungen in der Lage, Pakete inhaltlich zu analysieren. Dabei werden nicht nur die Verbindungsdaten wie Port und IP-Adresse, sondern auch die Nutzdaten von Paketen bewertet. Dies ermöglicht es u.a. festzustellen, ob die Nutzdaten von einer bestimmten Anwendung stammen und ob die Nutzdaten Anomalien aufweisen, die auf einen Angriff hindeuten können.
- Künstliche Intelligenz: In der Vergangenheit nutzten SIEM-Lösungen Techniken zur Anomalie-Erkennung, die sich vor allem auf Signaturen stützten. Auf diese Weise konnten lediglich bereits bekannte Bedrohungen erkannt werden. Bei Zero-Day-Attacken und APTs stoßen derartige Verfahren jedoch an ihre Grenzen, da über entsprechende Angriffe noch keine Informationen vorliegen oder sie gezielt vorhandenen Sicherheitsmechanismen ausweichen. SIEM-Lösungen profitieren hier maßgeblich von Künstlicher Intelligenz (KI). Einerseits ermöglicht KI einen effizienteren Umgang mit großen Datenmengen. Vor allem aber ist sie ein wertvolles Mittel, versteckte und komplexe Korrelationen zu entdecken und selbstlernend eine immer größere Palette an Anomalien immer präziser zu erkennen [10]. Auf diese Weise können auch bisher unbekannte Bedrohungen erkannt werden. Da der effiziente Einsatz von KI sehr rechenintensiv ist, sind Cloud-Lösungen (zumindest für spezifische SIEM-Komponenten) hier durchaus attraktiv.
- Nutzerbasierte Überwachung und Verhaltensanalyse: Einige SIEM-Lösungen sind in der Lage, die Aktionen von Benutzern (z.B. Administratoren oder anderen privilegierten Nutzern) gezielt zu überwachen. Analog zu Monitoring-Daten aus überwachten Geräten kann so das Nutzerverhalten überwacht und auf Konformität mit dem Regelwerk untersucht werden. Bei Verstößen können Warnungen oder Alarme ausgegeben werden. Das Konzept der Nutzerüberwachung wird bei einigen SIEM-Lösungen um eine Verhaltensanalyse erweitert, die auf KI basiert. Das SIEM ist dadurch imstande, das normale Verhalten eines Benutzers zu erlernen, Abweichungen festzustellen und diese zu bewerten. Bei Verdacht auf Identitätsdiebstahl oder schadenstiftende Aktivitäten kann dann das SIEM eine entsprechende Meldung machen. Aus dem Blickwinkel der Informationssicherheit mag eine solche Funktion ausgesprochen interessant sein, aus der Perspektive eines Datenschutzbeauftragten oder eines Betriebsrats bzw. Personalrats ist sie dagegen höchst bedenklich.
- Threat Intelligence Sharing: Threat Intelligence (auch: Cyber Threat Intelligence) ist eine allgemeine Bezeichnung für Informationen zu Bedrohungen im Bereich Informationssicherheit. Konkret handelt es sich dabei z.B. um Informationen zu Schadsoftware, Angriffsmuster, Signaturen oder Indicators of Compromise (IoCs). Threat Intelligence kann sowohl menschenlesbare als auch maschinenlesbare Dateien umfassen, die direkt verarbeitet werden können. Im Bereich SIEM hat sich Threat Intelligence Sharing als sinnvolle Ergänzung bei der Erkennung von Bedrohungen etabliert. Sie wird hauptsächlich in Form von Feeds genutzt, die frei von Communities zur Verfügung gestellt oder kostenpflichtig von Firmen abonniert werden können. Ähnlich zu Updates bei einem Viren-Scanner liefert Threat Intelligence Sharing einem SIEM kontinuierlich neue Informationen zur Erkennung und Einschätzung von aktuellen Bedrohungen.
Lizenzmodelle
Die Lizenzierung einer SIEM-Lösung erfolgt üblicherweise auf Basis des Volumens an Rohdaten bzw. der Anzahl von Ereignissen, die pro Zeiteinheit vom SIEM verarbeitet werden. Bei Überschreiten des lizenzierten Volumens verhalten sich die verschiedenen Produkte sehr unterschiedlich.
Beispiel QRadar: Die Kosten für IBM QRadar werden in Abhängigkeit von der eingehenden Datenrate berechnet. Möglich ist eine Lizenzierung per Events / s (EPS) oder Flows / min (FPM). Die dazu spezifizierte Rate legt den maximal möglichen Zustrom an Rohdaten in das SIEM fest. Wird der Wert überschritten, wird der Zustrom gedrosselt, sodass das Maximum nicht überstiegen werden kann. Die überschüssigen Daten werden dabei gepuffert. Sinkt die Datenrate wieder unter den Schwellwert, werden mit der übrigen Bandbreite die zwischengespeicherten Daten aus dem Puffer gelesen und verarbeitet bis dieser wieder leer ist.
Fließen Daten für mehr als 50% der Zeit gedrosselt ein, liefert QRadar eine entsprechende Benachrichtigung. Bis auf die Drosselung hat das Überschreiten des Limits keine weiteren Folgen. Die Drosselung selbst führt jedoch dazu, dass Daten nur noch verzögert verarbeitet werden können. Dies kann zur verspäteten Erkennung und Meldung von Problemen führen und die Korrelation von gewissen Ereignissen verhindern, wenn diese auf einem zeitlichen Intervall basiert.
Beispiel Splunk: Hier werden die Lizenzkosten anhand der Menge der einfließenden Rohdaten pro Tag berechnet. Der Hersteller bietet hierbei einen automatischen Rabatt an, wobei der Preis für ein Gigabyte proportional zur gesamten Menge abnimmt, für die die Lizenz gekauft wird. Lizenzen können individuell ab 1 GB pro Tag erworben werden, das Modell sieht kein Maximum vor. Die für die Lizenz festgelegte tägliche Datenmenge darf nur in begrenztem Umfang überschritten werden. Eine einmalige Überschreitung zieht keine Folgen nach sich, jedoch wird eine Benachrichtigung ausgegeben. Geschieht dies innerhalb von 30 Tagen fünfmal oder öfter, können die von Splunk gespeicherten Daten jedoch nicht mehr durchsucht werden. Hierbei werden die Rohdaten weiterhin gespeichert und indexiert, lediglich der Zugriff wird verweigert. Die Sperrung wird erst aufgehoben, wenn in einem Zeitraum von 30 Tagen die festgelegte Datenmenge nicht mehr überschritten oder eine neue Lizenz mit höherem Limit aktiviert wird.
Solche Lizenzmodelle erschweren die Planung eines SIEM, denn zunächst ist bei der Beschaffung eines SIEM oft unklar, mit welcher Ereignisrate bzw. welchem Rohdatenvolumen zu rechnen ist. Wenn nicht bereits ein LM-Werkzeug im Einsatz ist und man dies als Basis für eine Schätzung nutzen kann, schätzt man typischerweise für die verschiedenen Typen von IT-Komponenten das Volumen eines einzelnen Systems ab und rechnet dann auf die zu überwachende IT-Landschaft hoch. Außerdem kann sich bei einem Sicherheitsvorfall, z.B. bei einem Angriff oder bei der Ausbreitung eines Wurms bzw. eines Verschlüsselungstrojaners im Netz, im Vergleich zur Normalsituation die Rate an Ereignissen und damit das Rohdatenvolumen drastisch (und praktisch nicht im Vorfeld kaum einschätzbar) erhöhen. Als Konsequenz plant man dann zusätzlich zu dem geschätzten Volumen einen vergleichsweise großzügigen Puffer für das lizenzierte Rohdatenvolumen ein.
6. Fazit
Ein Richtlinienapparat zur Informationssicherheit ist ohne effektive und effiziente SecOps nur Papier. Die eigentliche Musik der Informationssicherheit spielt nämlich genau hier, d.h. bei einem SecOps-Team, das hilft proaktiv Schwachstellen zu vermeiden, bestehende Schwachstellen zu entdecken, diese zu schließen bzw. risikominimierende Sicherheitsmaßnahmen zu entwickeln und Sicherheitsvorfälle zu erkennen und effektiv zu beseitigen.
Inzwischen verfügen wir über bewährte Standards (insbesondere ISO 27xxx und BSI IT-Grundschutz), die helfen ein solides Management von Schwachstellen und Sicherheitsvorfällen aufzubauen und über Werkzeuge, wie z.B. Schwachstellen-Scanner, LM- und SIEM-Lösungen, die ein SecOps-Team bei der Arbeit im SOC unterstützen. Jedoch ist der Aufwand für die Planung eines solchen SOC und die effektive Nutzung des Werkzeugapparats immens.
Ein SecOps-Team muss mit einem erheblichen Know-how höchst komplexe Vorfälle system- und anwendungsübergreifend analysieren und insbesondere verstehen können. Bei dem typischen Personalnotstand in der IT ist der Aufbau eines SecOp-Teams oft eine Quadratur des Kreises. Natürlich denkt man dann schnell an das Outsourcen von SecOps, und Dienstleister haben hier auch durchaus ein sehr interessantes Portfolio. Es bleibt jedoch dabei: Die Kompetenz für die jeweiligen Geschäftsprozesse muss lokal bleiben, und dies gilt auch für die damit verbundene IT-Landschaft. Dies bedeutet zwingend: Operative Informationssicherheit kann nur zu einem gewissen Grad sinnvoll outgesourct werden.
7. Abkürzungen
APT Advanced Persistent Threat
BSI Bundesamt für Sicherheit in der Informationstechnik
CERT Computer Emergency Response Team
CMDP Configuration Management Database
CVSS Common Vulnerability Scoring System
DER Detektion und Reaktion
DMZ Demilitarisierte Zone
EPS Events per Second
FPM Flows per Minute
ICMP Internet Control Message Protocol
IoC Indicator of Compromise
IoT Internet of Things
IPS Intrusion Prevention System
ISMS Information Security Management System
ISO International Organization for Standardization
KI Künstliche Intelligenz
KVP Kontinuierlicher Verbesserungsprozess
LM Log Management
NAC Network Access Control
NIST National Institute of Standards and Technology
PAM Privileged Access Management
SDL Security Development Lifecycle SecOps Security Operations
SEM Security Event Management
SIM Security Information Management
SIEM Security Information and Event Management
SOC Security Operation Center
TCP Transmission Control Protocol
UDP User Datagram Protocol
8. Verweise
[1] Siehe https://www.nist.gov/cyberframework
[2] Siehe https://www.bsi.bund.de/DE/Themen/ITGrundschutz/ITGrundschutzKompendium/itgrundschutzKompendium_node.html
[3] Die Inhalte im Artikel „Abwehr zielgerichteter Angriffe – die Paradedisziplin der Informationssicherheit“ in Der Netzwerk Insider vom Mai 2017 sind (leider) immer noch höchst aktuell!
[4] Siehe hierzu „Moderne Zonenkonzepte erfordern Mikrosegmentierung“ in Der Netzwerk Insider vom April 2019
[5] Siehe https://www.microsoft.com/en-us/securityengineering/sdl
[6] Siehe http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf
[7] Siehe hierzu „Best Practice für die sichere Administration der IT“ in Der Netzwerk Insider vom Mai 2018
[8] Siehe z.B. https://securityboulevard.com/2018/03/nextgen-siem-isnt-siem/
[9] Siehe z.B. http://docs.splunk.com/Documentation/SplunkCloud/latest/Search/Abouteventcorrelation
[10] Siehe hierzu auch „Künstliche Intelligenz erobert die IT“ in Der Netzwerk Insider vom Dezember 2018