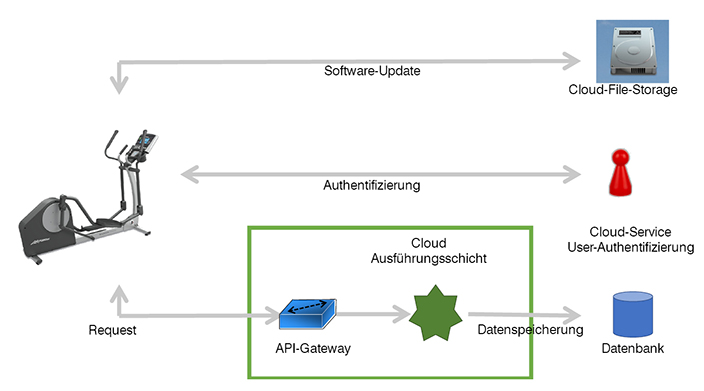
Aus welchen Elementen Cloud-Netze bestehen und wie skalierbare Anwendungen in der Cloud realisiert werden können, wurde bereits in anderen Insider-Artikeln behandelt. In diesem werden diese Elemente nun in einem fiktiven Beispiel zusammengeführt. Dabei soll exemplarisch aufgezeigt werde, warum auf das Wissen um IP-Netze keinesfalls verzichtet werden kann.
Die App
Bevor man Dienste und Infrastruktur eines Cloud-Anbieters anmietet bzw. zu nutzen beginnt, muss man natürlich zunächst einmal wissen, wofür man diese einsetzen will. In diesem fiktiven Beispiel soll es um ein Start-Up gehen, das mit einer App Furore machen will. Zum Jahresanfang bietet sich dafür eine „App der guten Vorsätze“ an. Man könnte sie auch „Speckweg App“ nennen, aber womöglich ist dieser Name schon geschützt. Auch wenn das Start-Up große Pläne hat, muss es schnell anfangen Geld zu verdienen und so startet man zunächst mit einer Funktion: einem Ernährungstagebuch. Davon gibt es zwar schon einige, aber dieses soll etwas Besonderes werden und sich von allen anderen absetzen. Warum? Betriebsgeheimnis! Wie bei Clouds üblich, sollen später dann weitere Funktionen nach und nach ergänzt werden, wenn sie fertig gestellt sind.
Die App umfasst zunächst folgende Funktionen:
- Anmeldung des Users
- Speichern persönlicher Kenndaten (Größe, Gewicht, Wohnort …)
- Speichern dessen, was man isst
- Datenbank mit allen Nahrungsmitteln und Convenience-Lebensmittel inkl. deren Nährwerten
- Auswertung der Mahlzeiten (Kalorien, Nährwerte, Fette…)
- Graphische Darstellung der Ernährungswerte
Da das kleine Unternehmen fest an seinen Erfolg glaubt, soll die Anwendung von vornherein so angelegt sein, dass sie für beliebige Nutzerzahlen skaliert. Außerdem ist geplant, die App weltweit zu vermarkten. Und selbstverständlich soll sie DSGVO-konform sein, d. h. Daten von Europäern bleiben in Europa. Da man nicht weiß, ob die DSGVO nicht Schule macht, sollen alle Daten eines Users soweit möglich in dessen Region gespeichert werden.
Konzept zu den Regionen
Alle großen Cloud-Anbieter haben Standorte in verschiedenen Regionen. Wenn man mit einer Anwendung online gehen will, muss man jedoch nicht zwingend alle Regionen abdecken. Jedoch gilt: je näher man am Nutzer ist, desto schneller ist die Anwendung. In dem Beispiel will man zunächst in Europa und in Australien starten, um möglichst weit voneinander entfernte Standorte zu haben. Da man jedoch auf einen durchschlagenden Erfolg hofft, sollte das IP-Konzept von vornherein darauf ausgelegt sein, um es später nicht ändern zu müssen.
IPv4 und IPv6 müssen dazu unterschiedlich betrachtet werden. Im Fall von IPv4 entscheidet man sich für das 10er Netz, was keine Schwierigkeiten bereitet, da man ja ein Start-Up ist.
Um ggf. später weitere Cloud-Provider nutzen zu können und zwischen den eigenen Cloud-Netzen die Kommunikation ohne umständliches NAT zu ermöglichen, verplant man nicht das gesamte 10er Netz, sondern nur einen Teilbereich davon. Im Beispiel hat man sich für eine 10er Bitmaske entschieden, so dass das 10er Netz in vier gleich große Teile aufgeteilt wird. Will man alle Cloud-Provider gleich behandeln, so kann man noch drei weitere mit IP-Adressen ausstatten.
Für die Regionen hat man sich für 12er Bitmasken entschieden. Es stehen also jeweils 16 Class-B-Netze für das IP-Design innerhalb einer Region zur Verfügung. Je eines dieser Class-B-Netze wird für die Virtual Private Clouds (VPC bei Amazon) bzw. virtuellen Netze (Azure) genutzt. So kann man pro Region 16 unabhängige, virtuelle Rechenzentren mit IP-Adressen ausstatten.
Um die Sache möglichst einfach zu halten, nutzt das Unternehmen für die Subnetze 24er Netze.
Dieses Design
- bietet ausreichend Platz für künftiges Wachstum.
- bietet die Möglichkeit mehrere virtuelle Netze in einer Region zu betreiben. So kann man bspw. die Entwicklung von den Produktivnetzen getrennt halten oder unterschiedliche, voneinander unabhängige Anwendungen betreiben, ohne dass diese sich in die Quere kommen können.
- erlaubt die Kommunikation über die Grenzen der virtuellen Netze / VPCs und Regionen hinweg, ohne dass NAT genutzt werden muss. Vorausgesetzt man arbeitet mit Tunneltechniken, um die VPCs und Regionen miteinander zu verbinden.
- erlaubt die Nutzung einfacher IP-Regeln bei Access-Listen oder auf Firewalls, um die Kommunikation zu erlauben bzw. zu unterbinden.
Für bereits existente Unternehmen ist das meist so einfach nicht möglich, da die privaten Netze bereits intern genutzt werden. In diesem Fall muss geschaut werden, wo noch ausreichend Adressräume frei sind. Die Grundprinzipien sollten jedoch analog zum Beispiel eingehalten werden.
Bei IPv6 funktioniert das etwas anders: statt mit Unique Local Addresses (ULAs) zu arbeiten, also dem Pendant zu dem privaten IPv4 Adressen, nutzt man öffentliche IP-Adressen, die einem die Cloud-Provider zur Verfügung stellen. Diese sind den IP-Regionen von V6 zugeordnet, d.h. bei europäischen Cloud Regionen kommen diese Adressen aus dem Bereich des RIPE bei australischen Cloud Regionen vom APNIC.
Die Cloud-Provider vergeben einen Bereich pro Virtuellem Netz / VPC (vgl. Abbildung 1)
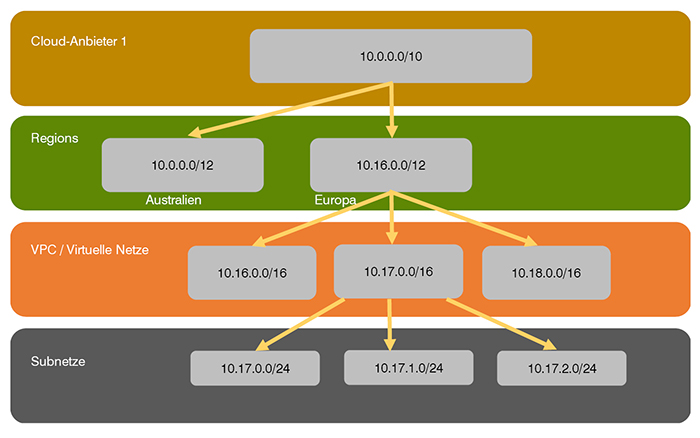
Abbildung 1: Regionen-übergreifendes IPv4-Design
Verbindung der Cloud-Regionen
Nun ist damit zu rechnen, dass zwischen den Regionen Daten ausgetauscht werden müssen. Dafür stehen verschiedene Möglichkeiten zur Verfügung:
- Internet
Natürlich kann das Internet genutzt werden, um die Daten zwischen den Regionen auszutauschen. Sollen jedoch auch sensible Daten ausgetauscht werden, ist diese Methode nicht zu empfehlen. Im Zweifelsfall sollte man also die Finger davonlassen. Jedoch gibt es durchaus Fälle, bei denen diese Variante die einfachste und kosteneffektivste ist.
- Punkt-zu-Punkt-VPN
Zwischen zwei Standorten kann man ein Punkt-zu-Punkt-VPN aufsetzen. Dafür bieten die Cloud-Provider meist sogar verschiedene Möglichkeiten an, die man nutzen kann. Alternativ ist es auch möglich so eine Verbindung selbst aufzusetzen, indem man die entsprechende Software (Firewalls, VPN-Gateways…) auf virtuellen Maschinen in der Cloud konfiguriert oder diese vorkonfiguriert von den entsprechenden Herstellern im Marketplace des Cloud-Anbieters mietet. Der Nachteil ist in beiden Fällen, dass die Verwaltung von Punkt-zu-PunktVerbindungen schnell sehr unübersichtlich werden kann, wenn es viele „Punkte“ werden, die da miteinander verbunden werden sollen. Beim Eigenbetrieb kommt obendrauf noch der Aufwand, den man für Wartung und Pflege benötigt.
- Punkt-zu-Mehrpunkt-Verbindungen
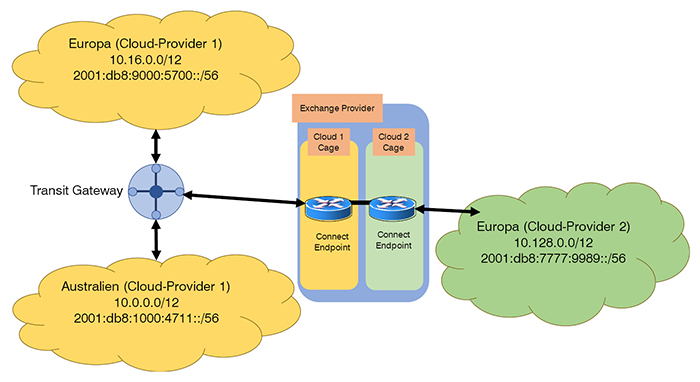
Unter dem Namen „Transit-Gateway“ vermarktet beispielsweise Amazon solch ein Produkt. Abbildung 3 zeigt, wie das für die Beispiel-App aussehen könnte: Da man hofft in Zukunft groß raus zu kommen, hat man sich für das Transit-Gateway entschieden. Zwar würde bei zwei Clouds eine Punkt-zu-Punkt-Lösung zunächst ausreichen, jedoch müsste man dann später auf die Mehrpunkt-Technik umsteigen, die Abbildung hat in Grau bereits die geplante Erweiterung für Nordamerika eingezeichnet.
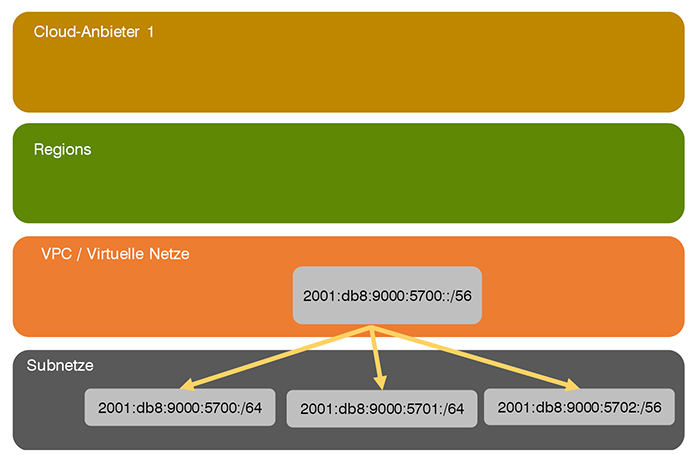
Abbildung 2: IPv6-Design
Bei der Einrichtung der Transit-Gateways gibt man an, welche VPCs damit verbunden sind. So lernt das Transit Gateway alle Netze in allen Regionen kennen. Ein automatisches Routing zwischen den Regionen ist damit jedoch noch nicht verbunden. Auch die Routing-Tabellen innerhalb der VPCs müssen angepasst werden. Die Abbildung zeigt das beispielhaft für die Default-Route in Europa. Dabei ist zu beachten, dass Routing-Tabellen pro Subnet deklariert werden. Es ist also nicht nötig, dass jedes System aus jedem Subnet alle Systeme der anderen Clouds erreichen kann. Auch ohne Access-Listen kann das mittels Routing-Tabellen unterbunden werden. Dazu später mehr.
Bis hierher kann das Design im Grunde am grünen Tisch gemacht werden, ohne zuvor die Anwendung genau unter die Lupe zu nehmen. Das gilt allerdings nicht für alle weiteren Überlegungen, die man als Netzwerker beim Gang in die Cloud anstellen muss.
Eine Bemerkung noch zum Transit-Gateway: damit ist es nicht nur möglich, die VPCs desselben Cloud-Providers miteinander zu verknüpfen, es kann auch in Verbindung mit VPN-Gateways das eigene Rechenzentrum angebunden werden oder über Direct Connect eine Verbindung über einen Point of Presence (PoP) Provider, einen Rechenzentrumsprovider also, herstellen. Damit ist das Transit Gateway eine Variante, Clouds verschiedener Provider miteinander zu verknüpfen, sofern diese am selben PoP-Provider vertreten sind, auch dazu später mehr.
Verteilung der Daten
Nachdem die Netze nun geplant und die Regionen miteinander verbunden sind, müssen die Daten „verteilt“ werden. Dazu ein genauerer Blick auf die Art der Daten, die von der Anwendung genutzt werden. In Hinblick auf Schutzbedarf und DSGVO gibt es zwei Arten von Daten:
- Personenbezogene Daten
Ob Username, Passwort, Gewicht oder Essgewohnheiten: all das wird als personenbezogene Daten gewertet und sollte somit zum einen gut geschützt und zum anderen gemäß der DSGVO behandelt werden. In unserem Beispiel bedeutet das, die Daten der europäischen User müssen in Europa bleiben. Aus Gründen einer guten Performance sollten jedoch auch die Daten der Australier in Australien verbleiben, da sonst die Laufzeiten zu hoch werden. Reist ein Europäer nach Australien, verbleiben seine Daten natürlich in Europa. Die Nutzung der App sollte jedoch weiterhin funktionieren.
- Nicht-personenbezogene Daten, namentlich: Nahrungsmittel
Die verschiedenen Nahrungsmittel inkl. ihrer Nährwerte werden in einer Datenbank gespeichert. Sucht ein User nach Leberwurst, bekommt er verschiedene Produkte vorgeschlagen, von der Supermarkt-Wurst bis hin zu den Durchschnittswerten von Metzgerware.
Zusätzlich haben die User die Möglichkeit, Produkte selbst einzupflegen, wenn sie fehlen. Es ist offensichtlich, dass die Nährwerte von Nahrungsmitteln aus Sicht der DSGVO nicht relevant sind. Schützenswert sind sie höchstens dergestalt, dass ein Mitbewerber nicht die ganze Datenbank abgreifen kann, schließlich ist es sozusagen die Kernkompetenz der App. Hinzu kommt, dass die Lebensmitteldatenbank zwar oft abgefragt wird, aber seltener ergänzt wird. Aus diesen Gründen entscheidet man, diese Daten weltweit in den Cloud-Regionen zu verteilen. Das sichert eine schnelle Abfrage für die User und verstößt nicht gegen geltendes Recht.
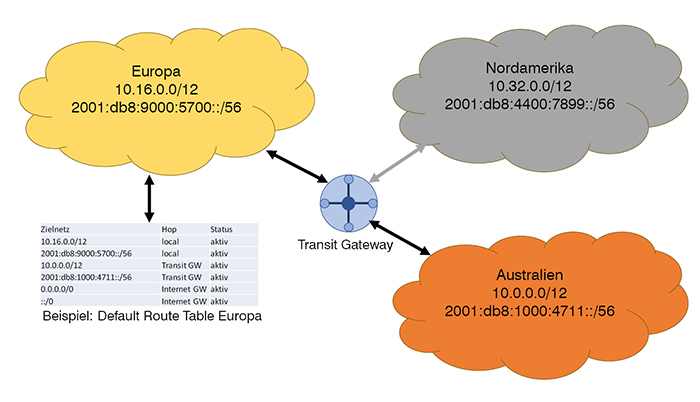
Abbildung 3: Verknüpfung mehrerer Clouds mittels Transit Gateway
Um diese Bedingungen zu erfüllen, installiert man in jeder Region zwei unabhängige Datenbanken: eine mit den Lebensmitteln, eine mit den Userdaten. Die Userdatenbank enthält jeweils nur die User, die dieser Region zugeordnet sind. Wer das ist, wie man sicherstellt, dass Europäer immer in Europa registriert werden, auch wenn sie mit der Diät in Neuseeland beginnen und wie man Daten von einer Region in eine andere transferiert, sind Fragen, mit denen sich Softwaredesigner, -entwickler und Anwälte befassen dürfen. Neben anderen Sicherheitsvorkehrungen, die ebenfalls eher in der Softwareentwicklung und Passwort-Policy liegen, kann man aber auch Mechanismen der Netzwerktechnik anwenden, um die Daten zu schützen.
Dabei muss der Netzwerker jedoch wissen, welche Art von Daten wo gespeichert und von wo abgerufen werden können, bzw. von wo nicht. Im Beispiel gibt es die bereits beschriebenen zwei Arten von Daten, die unterschiedlich behandelt werden müssen:
- Personenbezogene Daten
Diese müssen in der Region des Users verarbeitet werden. Entsprechend kann für die Datenbank, in der diese Daten liegen, eine Policy definiert werden, die den Zugriff auf die IP-Adressen der eigenen Region beschränkt. Produkte wären Security Group bei AWS oder Network Security Group (NSG) bei Azure. Weiß man genauer, welche Systeme Zugriff auf die Daten haben sollen, bzw. in welchen Subnetzen diese Systeme laufen, so kann man die Policy natürlich noch weiter einschränken, als das in Abbildung 4 dargestellt ist
- Nicht-Personenbezogene Daten
Bei diesen müssen nicht nur die Systeme der eigenen Region Zugriff haben, sondern auch die in anderen Regionen, oder vielmehr muss eine Synchronisation der Daten möglich sein. Wie das konkret realisiert wird, ist außerhalb des Skopes dieses Artikels. Für die Access-Policy ist nur notwendig zu wissen, dass es möglich sein soll. D.h. eine so eng gefasste Access-Liste wie bei den personenbezogenen Daten ist nicht möglich, aber auch nicht nötig. Auch hier zeigt Abbildung 4 beispielhaft eine sehr lasche Policy, die selbstverständlich bei genauerem Wissen um die Systeme weiter eingeschränkt werden sollte.
In beiden Fällen ist zu beachten, dass die Access Policies nicht als Access-Listen an ein Netzwerk oder an einen Router gebunden werden, sondern an die Datenbank. Nutzt man die Datenbank als Dienst des Cloud Providers, so bietet dieser auch an, jede Datenbankinstanz mit einer eigenen Policy zu verknüpfen. Zumeist muss man das sogar beim Einrichten, auch wenn man dort dann eine Policy „permit all“ anlegen könnte.
Richtet man die Datenbanken hingegen auf selbst gemanagten Systemen ein, also bspw. in einer virtuellen Maschine, so ordnet man die Policies den VMs zu. In diesem Fall müssen sie natürlich um die Bedürfnisse der VMs erweitert werden, beispielsweise sollte es ermöglicht werden, das Betriebssystem zu warten und upzudaten.
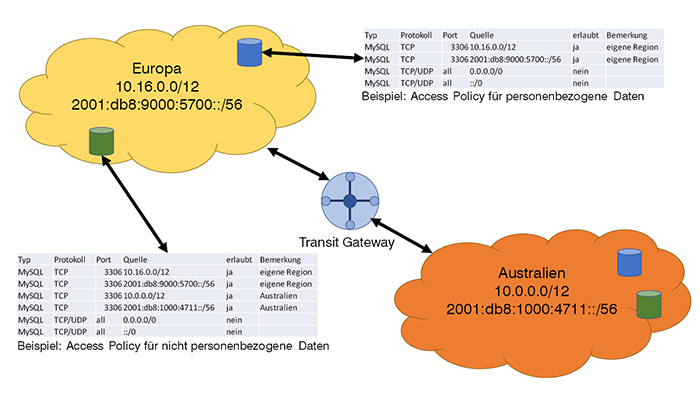
Abbildung 4: Beispiel für Access Policies
Aufbau einer Cloud
Für die Anwendung selbst hat sich das kleine Start-Up für Container entschieden. Die Vorteile, die es sich davon verspricht sind:
- Schnelle Entwicklungszyklen, da pro Container jeweils nur eine Funktion der Anwendung realisiert wird. So gibt es Container mit Skripten für die Eingabe der eigenen Daten, der verzehrten Lebensmittel und dem Einpflegen neuer Lebensmittel. Die unterschiedlichen Bereiche können dank der Container unabhängig voneinander weiterentwickelt werden.
- Skalierbarkeit, da diese Funktionen unterschiedlich oft genutzt werden, können sie per Container gut unabhängig voneinander skaliert werden.
Die Nutzung eines entsprechenden Orchestrierungstools erlaubt es zudem, diese Skalierung zu automatisieren.
- Einfache Integration neuer Funktionen: für die Zukunft sind weitere Funktionen geplant, wie die Ablage von Rezepten, Diskussionsforen oder Contest der Art, wer am schnellsten 5kg abgenommen hat. Diese neuen Funktionen können unabhängig von den bestehenden entwickelt werden.
- Unabhängigkeit vom Cloud-Anbieter: will man später doch den Cloud-Anbieter wechseln, so hofft man, das dank der Container schnell tun zu können, da alle Cloud-Provider entsprechende Angebote haben.
- Einhalten der DSGVO und anderer rechtlicher Rahmenbedingungen: bei Containern ist es möglich, Container-Images zu Tagen und Regeln für die Verteilung anzulegen. So ist es bspw. Möglich, ein Image als „EU-only“ zu tagen und eine Regel zu definieren, die besagt, dass dieses Image ausschließlich auf Hostsystemen laufen darf, die das Image „EU“ haben.Andererseits gibt es Container-Images, die man in allen Clouds einsetzen kann.
Es gibt noch weitere Vorteile von Containern in diesem Zusammenhang, ebenso zur Möglichkeit diese zu orchestrieren, also zu verteilen. Zur weiteren Lektüre sei der Netzwerk Insider vom Januar 2017 empfohlen.
Um Ausfallsicherheit und Skalierbarkeit möglichst zu gewährleiten, verteilt das Unternehmen die Container auf (mindestens) zwei Availability-Zonen pro Cloud. Pro Availability-Zone werden (mindestens) zwei Subnetze definiert: in dem einen sind die Webserver, bzw. die Container, die Webserver beinhalten, in dem jeweils anderen Subnetz sind die Container, die die Funktionen der Anwendung bereitstellen. Beispielsweise könnten in den Containern php installiert sein und die PHP-Skripte, die die eigentliche Anwendung zur Verfügung stellen. Die Datenbanken bekommen virtuelle Netzwerkverbindungen zu den Subnetzen, in denen die Anwendungscontainer laufen, nicht jedoch zu denen, in denen die Webserver positioniert sind. Für die Verteilung der Anfragen auf die Availability-Zonen nutzt man Loadbalancer-Dienste des Cloud-Providers. Auch hier kommen zwei zum Einsatz, je einer pro Availability-Zone, die Lastverteilung zwischen den Loadbalancern erfolgt mittels des DNS Dienstes des Providers. (Mehr zu der Skalierbarkeit mittels Loadbalancern im Netzwerk Insider vom August 2018). Die Auslastung der Webserver und Container-Hosts wird überwacht und automatisch werden bei Bedarf weitere hinzugenommen oder überflüssige heruntergefahren.
Die Aufgaben des Netzwerks bei diesem Design sind:
- Aufsetzen des DNS
Hier muss man sich reinarbeiten. Das DNS der Cloud-Provider bietet deutlich mehr Möglichkeiten als viele es gewohnt sind. Es geht nicht nur um die reine Zuordnung von Name zu IP-Adresse und umgekehrt. Loadbalancing ist da noch fast das einfachste. Später wird noch eine weitere Anforderung beschrieben.
- Konfiguration der Loadbalancer
Eine statische Konfiguration ist in dieser Umgebung nicht möglich. Da dynamisch Webserver hinzugeschaltet und heruntergefahren werden, muss eine Rückkopplung zwischen der Orchestrierungsebene der Container und den Loadbalancern konfiguriert werden.
- Definition der Routing Tabellen im Virtuellen Router
Ein Baustein zur Absicherung der Anwendung in der Cloud ist es, die Anwendungsserver von außen nicht unmittelbar erreichbar zu machen. Das kann und sollte u.a. mittels den Routing-Tabellen geschehen. Für die Subnetze, in denen die Anwendungscontainer laufen, wird kein Default-Gateway ins Internet definiert, so dass diese nicht nach außen kommunizieren können.
Eine Alternative dazu wären reine „Egress-Gateways“. Das sind Router zum Internet, die zwar erlauben, dass ein Cloud-interner Host auf das Internet zugreift, den Verbindungaufbau vom Internet zum Cloud-internen Host jedoch unterbindet. Diese Variante bietet sich an, wenn Updates für die Hosts aus dem Internet gezogen werden.
- Definition von Access-Listen
Neben der Absicherung durch die Routing Tabelle sollten auch Access-Listen genutzt werden. Um diese ordentlich aufsetzen zu können, muss der Netz- und Serveradministrator wissen, welche Container mit welchen anderen Containern kommunizieren und welche Ports dabei genutzt werden. Dasselbe gilt natürlich auch für den Zugriff auf die Datenbanken. Die Absicherung sollte dabei sowohl auf Netzebene erfolgen, wie bei einer klassischen Router-Access-Liste, wie auch pro Host/Container/Datenbank/… Hier funktionieren Access-Listen wie man es von IP-Tables her gewohnt ist.
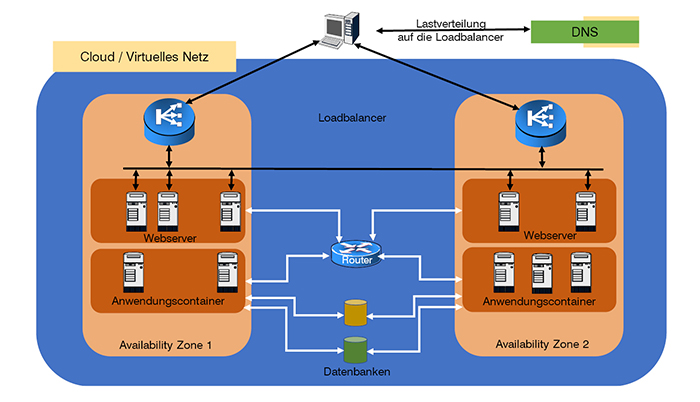
Abbildung 5: Anwendungsdesign in einer Cloud
Weltweiter Cloud-Betrieb
Wird eine Anwendung wie im Beispiel in mehr als einer Region betrieben, so sollen Anfragen natürlich möglichst an die nächstliegende Cloud geroutet werden. Greift man aus Neuseeland auf die Daten zu, so sollen die Anfragen in die Cloud nach Australien geschickt werden, von Deutschland aus sollen sie zur Europäischen Cloud gehen.
Das wirft zwei Probleme aus Sicht der IT-Infrastruktur auf:
- Die DNS-Antworten müssen sich in unterschiedlichen Regionen dieser Welt unterscheiden.
- Nutzt ein Europäer die App in Indonesien, so verbindet sie sich mit den Anwendungsservern in Australien, die Daten müssen jedoch aus Europa bezogen werden.
Bereits im letzten Absatz wurde DNS genutzt, um das Loadbalancing für eine einzelne Cloud mit zwei oder mehr Availability-Zonen zu ermöglichen. Wie dort bereits geschrieben, bieten die Cloud-Provider für DNS jedoch weit mehr Möglichkeiten. Für das erste Problem ist „Geolocation-Routing“ das Zauberwort: der DNS-Dienst ermittelt anhand der IP-Adresse des anfragenden Systems, wo sich dieses (ungefähr) befindet, und gibt dann eine entsprechende Antwort. Erkennt das DNS also, dass die Anfrage aus Irland kommt, gibt es die IP-Adresse eines der europäischen Loadbalancer zurück, kommt die Frage aus Indonesien, wählt es einen australischen Loadbalancer.
Die beiden Beispiele (Lastverteilung und Geolocation-Routing) zeigen, dass es sich lohnt, sich mit dem DNS der Cloud-Provider intensiv zu beschäftigen. Neben der externen Kommunikation gibt es auch zahlreiche Cloud-interne Anwendungsfälle. Wer also glaubt, alles über DNS zu wissen, wird beim Einstieg in die Cloud noch jede Menge dazulernen können.
Zugriff von „Außerhalb“ der eigenen Region
Das zweite, eben angesprochene Zugriffsproblem, das es zu lösen gilt, ist das Routing von Usern, die sich außerhalb ihrer „normalen“ Region aufhalten. Also beispielsweise eines Iren, der gerade auf Tuvalu in der Südsee Urlaub macht. Seine Daten liegen innerhalb der EU und sollen möglichst auch nur dort verarbeitet werden.
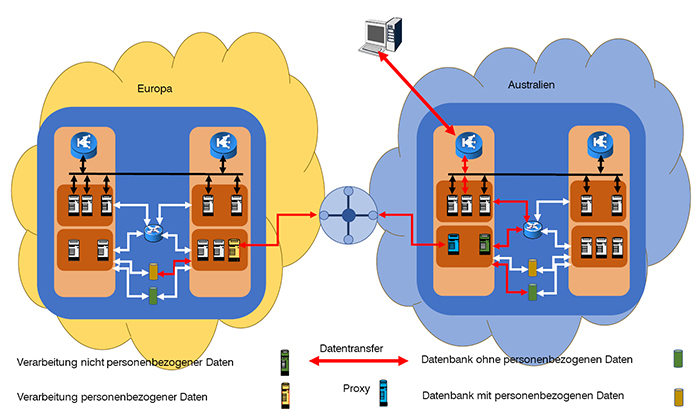
Abbildung 6: Beispiel für ortsgebundene Datenverarbeitung
Um das Problem zu lösen, gibt es viele Möglichkeiten, die sich Softwaredesigner und -entwickler einfallen lassen können. Einige davon sind unabhängig vom Netzdesign, so könnten die Entwickler der App die Loadbalancer bspw. in der App hinterlegen. Dann aber würden sämtliche Datenströme im Beispiel rund um die Welt fließen, auch wenn das gar nicht nötig ist, weil bspw. nur die Lebensmitteldatenbank abgefragt wird.
Die Alternative ist, dass die App, wie eben geschildert, per DNS an das nächstgelegene Rechenzentrum geleitet wird. Nun müssen sich die Entwickler eine Lösung für die Weiterleitung der Anfragen und Antworten einfallen lassen, so dass die Datenhaltung und Verarbeitung dort geschieht, wo der User für gewöhnlich zu verorten ist, also für einen Europäer DSGVO-konform in Europa.
Die in Abbildung 6 dargestellte Struktur stellt nur eine von vielen Möglichkeiten dar: stellt die App eine Verbindung her, sendet sie eine Kennung, in welcher Region ihr Nutzer seine Daten speichert, daraufhin werden alle personenbezogenen Daten über einen Proxy geleitet, die das Transit-Gateway für die Weiterleitung in die Stammregion nutzt, dort werden die Daten verarbeitet und gespeichert, in unserem Beispiel wären das seine Essgewohnheit, aber auch die eigentliche Useranmeldung mit Username und Passwort. Die Anfragen an die Lebensmitteldatenbank jedoch und andere nicht-personenbezogenen Aktionen können von der lokal günstigeren Cloud abgewickelt werden.
Aus Sicht des Netzes benötigen wir an dieser Stelle eine Verbindung zwischen den Regionen. Diese haben wir jedoch bereits beim IP-Design durch das Transit Gateway sichergestellt. Des Weiteren müssen auch hier Routing-Tabellen und Access-Listen angelegt und gepflegt werden. Um dies ordentlich zu erledigen und nicht einfach allen Traffic zwischen den Regionen zu erlauben, ist es notwendig, dass sich die Netzwerkverantwortlichen mit der Anwendungsarchitektur vertraut machen, so dass sie wissen, welche Server/Container einer Region mit welchen der anderen kommunizieren. Einige der Automatismen, die von Cloud-Providern angeboten werden, sind regionsübergreifend nicht verfügbar: startet ein Container in Australien, so gibt es nicht zwingend einen Mechanismus, der das in Europa bekannt gibt, so dass Access-Listen automatisch angepasst werden. Hier ist man gut beraten, mit den Entwicklern und Severadministratoren zusammen ein Konzept zu erstellen, das auch bei hoher Dynamik einerseits die Kommunikation sicherstellt, andererseits nicht zu viel erlaubt, um eine möglichst hohe Sicherheit zu gewährleisten.