Sollten Sie noch nicht in unserem Informationsverteiler sein, können Sie sich gerne hier anmelden
VMware NSX und Mikrosegmentierung in Theorie und Praxis
Virtualisierung hat in alle Bereiche des modernen Rechenzentrums Einzug gefunden. Nach Software Defined Compute und Software Defined Storage wird Software Defined Networking (SDN) und mit Letzterem auch „Network Function Virtualization“ (NFV) immer häufiger eingesetzt. In diesem Artikel sollen die einzelnen Komponenten und Grundlagen kurz beschrieben werden, die sowohl SDN als auch NFV ausmachen. Am Beispiel des Produktes VMware NSX werden die Eigenschaften und Möglichkeiten sowie die betrieblichen Aspekte des Einsatzes von SDN detaillierter betrachtet. Dabei wird ein Fokus auf der sogenannten „Mikrosegmentierung“ liegen, die in vielen Fällen ein Treiber für die Einführung von SDN und NFV ist.
In einem modernen Rechenzentrum wird die Virtualisierung auf allen Ebenen immer ausgeprägter. Während Software Defined Compute (SDC) durch Virtualisierungslösungen wie Hyper-V, VMware vSphere oder KVM schon die Norm ist, werden Software Defined Storage (SDS) und Software Defined Networking (SDN) – Letzteres in Verbindung mit Network Function Virtualization (NFV) – erst langsam eingeführt. Ein Grund für die zögerliche Einführung: SDN und NFV stellen einen besonders tiefen Einschnitt sowohl in die Architektur als auch für den Betrieb dar.
Dieser Artikel wird sich mit diesen Einflüssen beschäftigen. Dazu sollen zunächst die grundlegenden Eigenschaften und Funktionen von SDN und NFV erläutert werden.

Kommunikation im Wandel
Wer den Kommunikationsmarkt in den vergangenen 10 Jahren beobachtet hat, der konnte zwei bestimmende Strömungen wahrnehmen:
- VoIP und UC haben in modernen Büro-Umgebungen die Kommunikation stark vereinfacht und flexible Arbeitsmodelle kostengünstig ermöglicht.
- Die klassische Kanalvermittlung, incl. DECT, ist im Bereich der Produktion nur schwer zu ersetzen.
Was aber beide Strömungen gemein haben, ist die Tatsache, dass sie bis heute meist auf lokale Infrastrukturen aufsetzen.
Dieser Umstand ist ja auch zunächst nicht verwunderlich. Warum sollte ein Service wie die Telefonie anders bereitgestellt werden als zum Beispiel die Infrastruktur eines LANs? Beide Dienste stellen Anforderungen an die lokale Verfügbarkeit. Hier der LAN Port am Switch, dort das Tischtelefon. Daher scheint es nur logisch, solche Dienste lokal zu betreiben. Diese Sichtweise gerät jedoch seit nunmehr fünf Jahren immer härter unter Beschuss.
Wie konnte das passieren?

Markus Geller
ComConsultWarum jede Organisation einen CTO braucht
An keinem Bereich des Lebens geht der technologische Wandel spurlos vorbei. Arbeiten und Abläufe, die Jahrtausende lang kaum Änderungen unterlagen, werden durch die Digitalisierung verändert. Internet of Things bedeutet wirklich die digitale Erfassung aller Dinge. Sind wir darauf vorbereitet? Die Antwort darauf ist ein klares Nein. Diese Aussage basiert auf Erfahrungen aus den letzten drei Jahrzehnten, in denen wir fast alle Branchen und Typen von Organisation beratend begleitet haben. Immer wurden viele Organisationen vom technologischen Wandel überrascht. Sie haben auf große Trends im Markt erst mit Verzug reagiert. Bleibt es auch in Zukunft so, werden viele Unternehmen den technologischen Wandel nicht überleben. Eine Organisation, die diesem Schicksal entgehen will, braucht einen Mechanismus für die Früherkennung der sie betreffenden Technologietrends. Dieser Mechanismus muss ein dauerhafter sein. An einem Chief Technology Officer (CTO) und der dazu gehörigen Organisationsstruktur geht kein Weg vorbei.
Bisher haben sich viele Organisationen damit begnügt, hin und wieder Reden und Schriften sogenannter Gurus Aufmerksamkeit zu schenken. Prognosen aus dem Munde oder der Feder dieser Propheten sind beliebt. Allein der Umstand, dass es jemand im Glücksspiel der Wirtschaft zum Milliardär schaffte, reicht aus, um ihm teure Vortragshonorare zu sichern.

Dr. Behrooz Moayeri
Die Personalabteilung als Schmelztiegel von Informationssicherheit und Datenschutz
In meinen Projekten bei Kunden stelle ich immer wieder fest, dass die Personalabteilung der jeweiligen Institution einen höchst interessanten Schmelztiegel sowohl für die Informationssicherheit als auch für den Datenschutz darstellt. Einerseits werden in der Personalabteilung höchst schützenswerte personenbezogene Daten verarbeitet. Andererseits müssen die Mitarbeiter mit vergleichbar hohen Freiheiten Internet-Dienste nutzen dürfen, um ihre Arbeit zu verrichten.
Dies beinhaltet beispielsweise, dass E-Mails mit Anhängen, die von zunächst Unbekannten (Bewerbern) stammen, geöffnet werden müssen. Außerdem ist eine intensive Präsenz in Sozialen Netzen notwendig, um sich für Bewerber attraktiv zu machen, Kontakte zu pflegen und geeignete Kandidaten zu finden. Die Policies auf einer Firewall, einem Secure Web Gateway oder einem Secure E-Mail Gateway müssen für die Mitarbeiter der Personalabteilung entsprechend freigiebig sein, damit sie ihre Arbeit verrichten können.

Dr. Simon Hoff
VMware NSX und Mikrosegmentierung in Theorie und Praxis
Fortsetzung
Einige Aspekte davon wurden schon in früheren Artikeln des Netzwerk-Insiders erläutert, beispielsweise in [1]. Aus diesem Grund, und um den Umfang des Artikels zu begrenzen, wird hier nicht genau auf zugrundeliegende Techniken wie Netzwerk-Verkapselung oder „klassische“ Virtualisierung von Servern eingegangen. Es werden lediglich die kritischen Aspekte und die Konsequenzen für den Einsatz von SDN und NFV erwähnt werden.
Am Beispiel von VMware NSX werden dann diese Eigenschaften und Funktionen dargestellt. Die daraus resultierenden technischen und betrieblichen Auswirkungen werden anhand von Beispielarchitekturen und -prozessen genauer beleuchtet, wie sie typischerweise in einem Unternehmen auftreten.
Ein besonderer Fokus wird auf der sogenannten Mikrosegmentierung liegen, da sie neue Ansätze zur Netzwerksegmentierung bietet, die auch in bestehenden Umgebungen große Vorteile bieten kann. Ein Beispiel hierfür ist der Umzug eines Systems zwischen verschiedenen Netzwerksegmenten ohne die Änderung einer IP-Adresse.
1.1 Netzwerkvirtualisierung
SDN und NFV sind zwei Aspekte, die oft gemeinsam genutzt werden, insbesondere bei einer tiefen Integration in eine Virtualisierungsumgebung, wie es z.B. bei VMware NSX der Fall ist. Dabei werden die Aspekte des „klassischen“ Netzwerks wie folgt aufgeteilt:
- SDN:
SDN hat das Ziel, die Control-Ebene von der Datenebene des Netzwerks zu trennen. Das Hauptziel dieser Technologie ist, Netzwerke aus einer zentralen Kontrollinstanz flexibel zu konfigurieren und nicht jede einzelne Netzwerkkomponente manuell anpassen zu müssen. Ein weiterer großer Vorteil neben der Flexibilität ist die geringere Fehleranfälligkeit. - NFV:
Bei NFV werden Netzwerkdienste virtualisiert, für die im „klassischen“ Netzwerk dedizierte Appliances betrieben werden. Darunter fallen beispielsweise Routing, Load-Balancing, Firewalls, Spam-Filter, Threat Intelligence zur Erkennung von Angriffen und andere.
Dabei ist in den allermeisten Fällen – so auch bei VMware NSX – die Kontrolle des Netzwerks bis auf Ebene der einzelnen VMs oder für einzelne Container möglich. Dadurch werden sowohl die Sichtbarkeit als auch die Sicherheit bei korrekter Nutzung verbessert. Das Troubleshooting bietet durch die verbesserte Sichtbarkeit neue Möglichkeiten und wird deutlich erweitert. Durch den Einsatz von Netzwerkverkapselung und häufig auch von herstellerspezifischen Erweiterungen ergeben sich aber auch neue Herausforderungen. Der Einsatz von speziellen Tools kann hier Abhilfe schaffen. Diese Tools werden typischerweise vom Hersteller der jeweiligen Netzwerk-Virtualisierungslösung (NVL) angeboten.
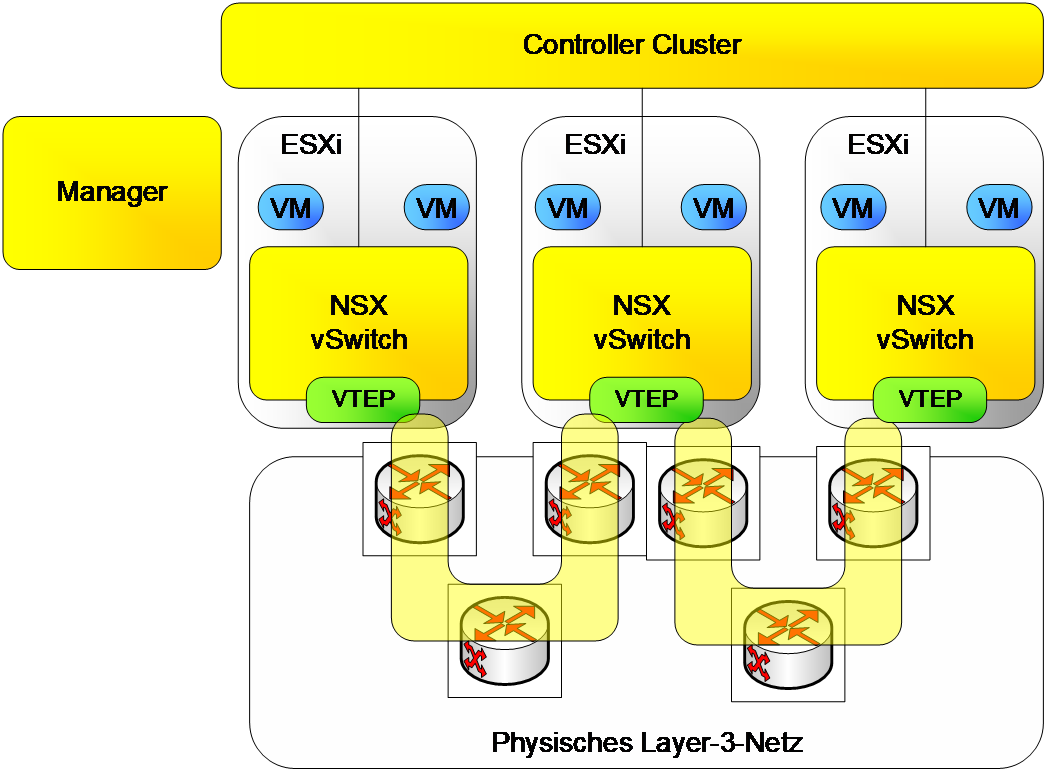
Abbildung 1: Schematische Darstellung der verschiedenen Ebenen in einer NVL am Beispiel VMware NSX
Im Netzwerk werden bei SDN und NFV typischerweise die folgenden drei Ebenen unterschieden, wie sie in Abbildung 1 dargestellt sind:
- Management-Ebene:
Auf dieser Ebene interagieren Nutzer bzw. Administrator mit der NVL. Hier wird die Konfiguration vorgenommen, gespeichert und an die Controller-Ebene weitergeleitet. Dies beinhaltet Firewall-Regeln, Zugriffslisten, Netzwerk-Routen zu allen angeschlossenen (auch virtuellen) Systemen und so weiter. Um eine Automatisierung und/oder eine Kommunikation mit anderen Software-Tools zu ermöglichen, bieten NVLs im Allgemeinen auch eine Rest-API, welche die einzelnen Funktionen von außen ansprechbar macht. - Controller-Ebene:
Die Controller-Ebene leitet die Konfiguration der Management-Ebene an die beteiligten Endpunkte weiter. Die Controller-Ebene kann, je nach konkreter Umsetzung, sowohl zentral als auch dezentral umgesetzt sein. Im zentralen Fall werden ein oder mehrere Controller-Instanzen als virtuelle Appliances eingesetzt. Bei diesem zentralen Ansatz ist im produktiven Fall der Einsatz von mehreren Instanzen die Regel, um beim Ausfall einer Instanz weiterhin den Betrieb sicherzustellen. Ein Beispiel für eine verteilte Controller-Ebene ist BGP-EVPN, wie es von der IETF standardisiert, in den Produkten führender Hersteller implementiert und bei einigen Providern im Einsatz ist. - Daten-Ebene:
Auf dieser Ebene wird der eigentliche Netzwerk-Verkehr zwischen den verschiedenen beteiligten Hosts weitergeleitet.
Die NVL nutzt Overlay-Netzwerke, um die Trennung von Netzwerken ohne Einfluss auf das zugrundeliegende physische Netzwerk zu realisieren. Diese verkapseln den Netzwerkverkehr zwischen zwei (virtuellen) Systemen so, dass er für das physische (Layer-3-)Netzwerk transparent ist. Der Einsatz von Overlays bedeutet, dass der Header der Netzwerkpakete vergrößert werden muss, da zusätzliche Header eingeführt werden. Um die Größe der Nutzdaten nicht zu beeinträchtigen, muss die maximal mögliche Paketgröße (Maximum Transmission Unit, MTU) entsprechend groß sein. Ein typischer Wert für die minimale MTU bei der Nutzung von Overlay-Netzen wie VXLAN oder Geneve ist 1600 Bytes. Sollten also nicht flächendeckend Jumbo Frames im Netzwerk genutzt werden, kann dies eine Anpassung an den physischen Netzwerk-Komponenten bedeuten. Zur Realisierung von Overlays können verschiedene Technologien zum Einsatz kommen. Die häufigste Verkapselungs-Technologie ist VXLAN. VXLAN und andere Verkapselungsmechanismen ermöglichen eine Virtualisierung von Layer-2-Netzwerken innerhalb eines bestehenden Layer-3-Netzwerks. Die Ver- und Entkapselung werden dabei – je nach Produkt bzw. Hersteller – an verschiedenen Stellen durchgeführt. Bei VMware NSX als Lösung für virtualisierte Umgebungen sind dies die Virtualisierungshosts. Bei Cisco ACI erfolgt dieser Schritt auf den Access-Switches. Gängige Server-Betriebssysteme unterstützen ebenfalls die Nutzung von VXLAN-Overlays.
Zunächst werden NFV und eine dadurch mögliche „Mikrosegmentierung“ genauer beschrieben.
Als konkretes Beispiel wird in diesem Artikel VMware NSX präsentiert und die typischen Komponenten dieser Netzwerk-Virtualisierungslösung genauer beschrieben.
Eine Besonderheit bei VMware NSX ist die Tatsache, dass diese Lösung in zwei Versionen angeboten wird: NSX-T und NSX-V. Es werden die Unterschiede, Gemeinsamkeiten und Einsatzszenarien für beide Versionen dargestellt und die strategische Position der beiden Produkte betrachtet.
1.2 Network Function Virtualization
Wie bereits im letzten Kapitel beschrieben, löst NFV verschiedene Dienste innerhalb des Netzwerks von spezialisierter und meist kostenintensiver Hardware. Darunter können viele Dienste aus den verschiedensten Bereichen fallen. Von typischen Netzwerkdiensten wie Load Balancing, Routing und Firewalling bis zu netzwerkbasierter Threat Intelligence, Spam-Filter, Anti-Virus, Data Loss Prevention und vielem mehr. Für typische Virtualisierungslösungen im Data-Center-Umfeld spielen v.a. die folgenden Funktionen bzw. Netzwerkkomponenten eine wichtige Rolle:
- Router
- Firewall
- Load Balancing
Diese Komponenten können in einer NVL unterschiedlich realisiert werden. Bei einer ausreichend tiefgreifenden Integration in die Architektur bietet sich hier eine verteilte Architektur an, da hierdurch die Ressourcen einer typischerweise zentralisierten, sehr performanten und kostenintensiven Komponente auf viele, weniger leistungsfähige Komponenten verteilt werden können. Dabei werden an den Endgeräten (bei NSX den Virtualisierungshosts) maximal ca. 10% der Leistung benötigt. Außerdem ergibt diese Verschiebung hin zum Endpunkt und damit so nahe wie möglich an die Endgeräte des Netzwerks (VMs und physische Systeme) eine wesentlich bessere Sichtbarkeit. Dies ermöglicht eine Überwachung der Endgeräte im Netzwerk in einer Art und Weise, die bisher nur sehr umständlich möglich war.
Besonders interessant ist dies im Bereich der Firewalls, da diese im „klassischen“ Netzwerk außerhalb der Virtualisierungsumgebung verortet sind und sich besondere Herausforderungen bei der Durchsetzung von Firewall-Regeln auf VM-Ebene ergeben:
Sämtlicher Traffic aller Systeme müsste zu einer (oder mehreren) zentralen Firewall(s) geführt werden, die eine ausreichende Leistung dafür besitzen müsste. Diese Übertragung des Traffics ist nur sehr umständlich möglich, indem beispielsweise Private VLANs auf VM-Ebene oder sehr kleine Subnetze genutzt werden. Der Betrieb einer solchen Lösung ist extrem aufwendig und wenig erprobt und ist daher nicht zu empfehlen.
Die Skalierbarkeit, bedingt durch die verteilte Funktionalität und damit Vermeidung zentraler Instanzen für Firewalling, Load Balancing etc. ist ein wesentliche Vorteil einer NVL gegenüber Hardware-basierten Netzfunktionen. Der weitere wesentliche Vorteil besteht darin, dass durch die Positionierung der Netzvirtualisierung im Kern des Hypervisors Netzfunktionen wie Segmentierung und Lastverteilung auf der Ebene virtueller Maschinen (VM-Ebene) wahrgenommen werden.
Diese Genauigkeit bietet die Möglichkeit, mit begrenztem Aufwand Firewall-Regeln auf Ebene einzelner VMs durchzusetzen.
1.3 Mikrosegmentierung
Eine der Möglichkeiten beim Einsatz einer NVL, die eine Sichtbarkeit des Netzwerkverkehrs bis auf VM-Ebene ermöglicht, ist die „Mikrosegmentierung“. Diese Technologie ist eines der größten Alleinstellungsmerkmale für kombinierte Lösungen für SDN und NFV, z.B. VMware NSX. In vielen Umgebungen stellt die Mikrosegmentierung sogar einen der Hauptgründe für die Einführung einer NVL dar.
In einer Architektur, welche die Firewall näher an die VM rückt und in der die notwendige Leistung nicht zentral bereitgestellt werden muss, ist dies gegenüber zentralisierten Komponenten stark vereinfacht. Bei einer entsprechenden Integration per API ist es möglich, die vorhandenen Endgeräte ohne eine feste Bindung an eine IP-Adresse aufzulisten. Speziell die Abkehr von Firewall-Regeln auf Basis von IP-Adressen ist hier der Schlüssel. Der Unterschied zwischen der „klassischen“ Segmentierung und der Mikrosegmentierung ist schematisch in Abbildung 2 dargestellt.
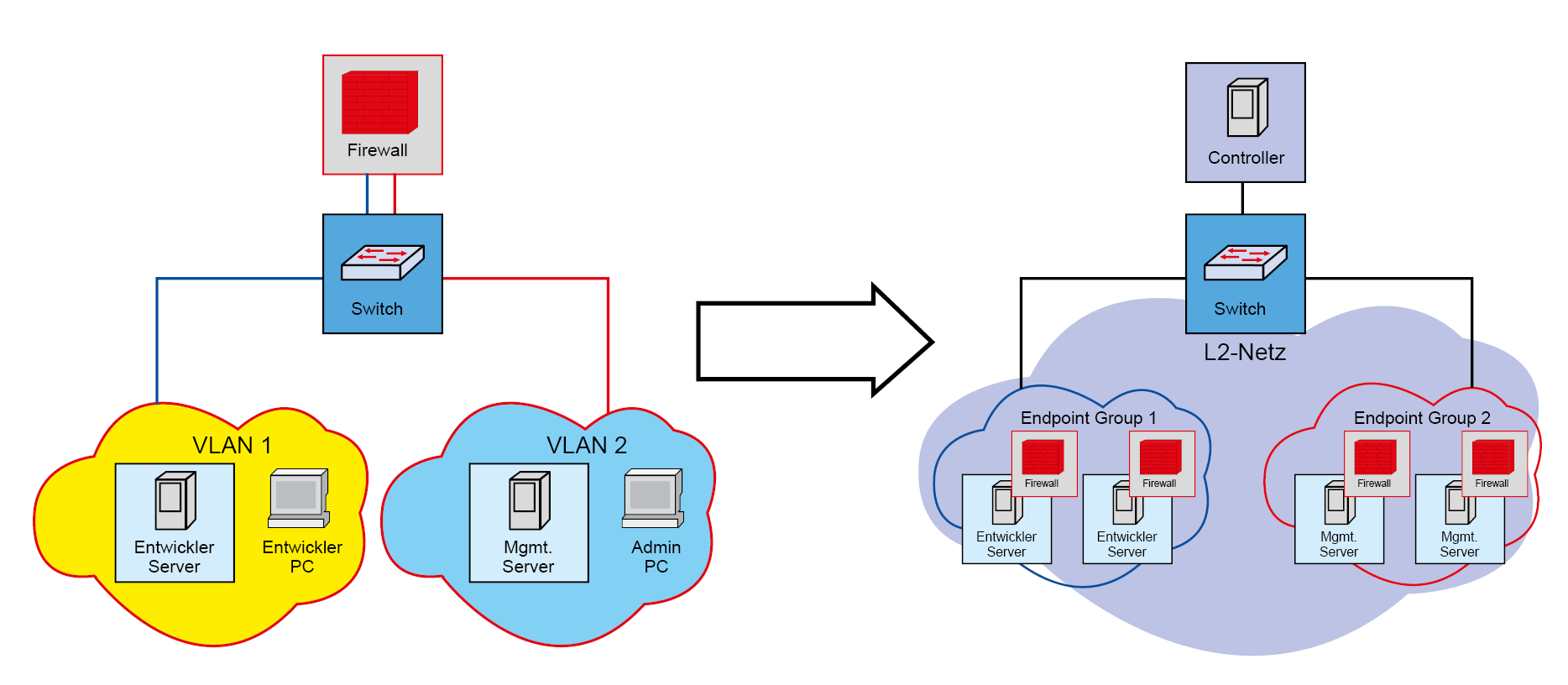
Abbildung 2: Von der zentralen Firewall zur Mikrosegmentierung
Dabei wird jeweils eine „kleine“ Firewall so nahe wie möglich an die jeweilige VM gebracht. Bei hochintegrierten Lösungen wie NSX-V ist diese Firewall direkt mit der VM „verbunden“ und folgt dieser auch bei einer Migration der VM. Bei weniger stark integrierten Systemen oder solchen, die auch Traffic zu und von physischen Systeme berücksichtigen soll, sind die technischen Details unterschiedlich. Im Allgemeinen ist ebenfalls ein Firewalling auf Ebene einzelner Hosts oder VMs möglich. Im Folgenden soll nur auf die für VMware NSX relevanten Fälle eingegangen werden.
2. VMware NSX – Grundlagen
In diesem Kapitel sollen zunächst die technischen Details von VMware NSX erläutert werden. Dazu gehört die Implementierung der Management- und Control-Ebenen gemäß Kapitel 1 sowie die genauen Funktionen, die NSX zur Netzwerkvirtualisierung (NFV) bietet. Die hier dargestellten Beispiele basieren auf NSX-V. Die Unterschiede zwischen NSX-V und NSX-T werden in einem eigenen Unterkapitel genauer erläutert.
2.1 NSX – Architektur-Elemente
Die Architekturelemente von NSX (Management-, Controller- und Daten-Ebene) stellen sich wie bereits in Abbildung 1 gezeigt dar.
Die Management-Ebene wird durch eine einzelne virtualisierte Appliance, den „NSX Manager“ dargestellt. Dieser stellt sowohl die GUI für den Anwender/Administrator als auch die API für eine (automatisierte) Steuerung bereit. Sollte diese Appliance ausfallen, schränkt dies den Betrieb der Umgebung nicht ein. Eine Änderung der Konfiguration ist in diesem Fall aber nicht mehr möglich. In Verbindung mit mehreren vCenter-Clustern (sog. „Cross-vCenter NSX“) ist auch die Nutzung eines zweiten NSX-Managers in einer Failover-Konfiguration möglich.
Es existiert ein Controller-Cluster, der für eine bessere Verfügbarkeit aus drei Instanzen besteht, die auf drei unterschiedliche Hosts verteilt werden sollten. Dadurch ergibt sich schon eine der grundlegenden Anforderungen für die Nutzung von NSX: Es müssen mindestens drei Virtualisierungshosts vorhanden sein, um eine ausreichende Ausfallsicherheit der Controller-Ebene zu gewährleisten.
Die Daten-Ebene und die „verteilten“ Funktionen innerhalb von NSX werden als Kernel-Module in den ESXi-Servern realisiert.
Abbildung 3 zeigt die Unterschiede zwischen der physischen Netzwerkstruktur (a), der variablen Verbreitung der einzelnen Segmente im Overlay-Netzwerk (b) und die für die angeschlossenen Endgeräte sichtbare, logische Netzwerkstruktur (c).
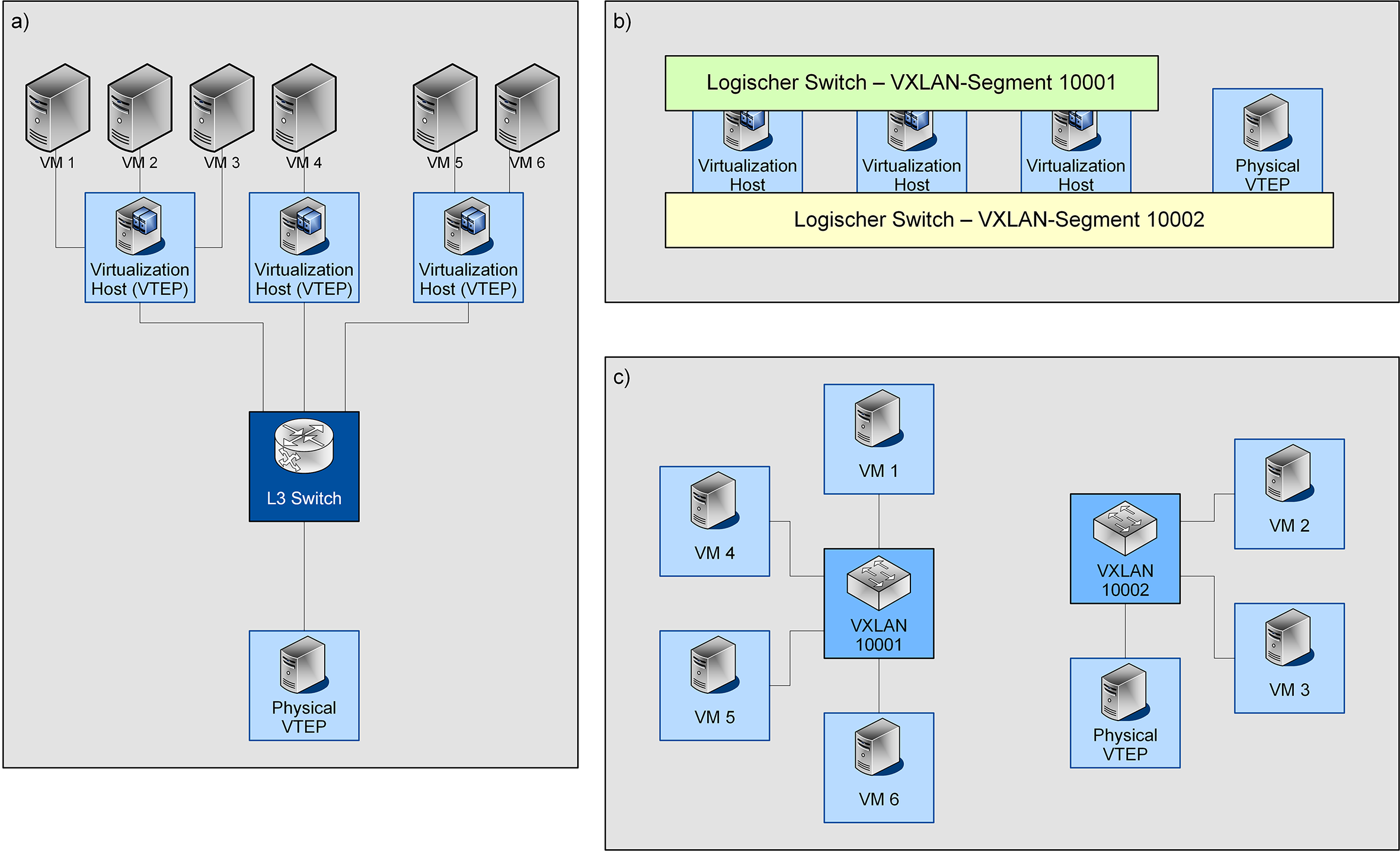
Abbildung 3: Schematische Darstellung der verschiedenen Ebenen in einer NSX-Umgebung: Physisches Netzwerk und Zuordnung der VMs (a), Verteilung von zwei VXLAN-Segmenten über die beteiligten physischen Systeme (b) und logische Struktur des Netzwerks (c)
2.2 NSX-V und NSX-T – Gemeinsamkeiten und Unterschiede
Ein Aspekt, der für die Nutzer von NSX zu Verwirrung führen kann, ist die Tatsache, dass VMware zwischen NSX-V und NSX-T unterscheidet. NSX-V ist die in vSphere hochintegrierte Version, die einen starken Fokus auf die Systeme innerhalb einer vSphere-Umgebung besitzt, aber auch physische Tunnel-Endpunkte einbinden kann. NSX-T bietet neben der Unterstützung von ESXi als Hypervisor auch KVM und ebenfalls physische Tunnelendpunkte. Ein prominentes Beispiel für eine Virtualisierungslösung mit KVM ist OpenStack. Der Fokus von NSX-T ist insgesamt sehr viel stärker auf hybride Szenarien und die Einbindung der Cloud und neuer Technologien wie Container ausgerichtet. Daher ist in den meisten Fällen bei der Einführung von NSX die T-Variante vorzuziehen. Zusätzlich dazu ergeben sich die in Tabelle 1 dargestellten Unterschiede zwischen NSX-V und NSX-T, auf die im Folgenden etwas genauer eingegangen werden soll.
Verkapselung auf Netzwerkebene
Wie in Kapitel 1.1 beschrieben gibt es verschiedene Möglichkeiten, den Netzwerkverkehr der NVL zu verkapseln. Dabei ist eines der primären Ziele, mehr als die mit VLANs nutzbaren 4094 (4096, von denen zwei reserviert sind) logischen Netzwerke bereitzustellen. Auch wenn diese Anforderung für die meisten Unternehmen etwas übertrieben erscheinen mag, so gibt es doch gerade bei großen Unternehmen und Betreibern von Shared Infrastructure durchaus einen Bedarf. Hier setzen NSX-T und NSX-V auf unterschiedliche Technologien. NSX-V nutzt VXLAN, welches die ältere und weiter verbreitete der beiden Verkapselungstechnologie ist. NSX-T nutzt GENEVE, welches eine große Ähnlichkeit zu VXLAN hat, aber aufgrund von variablen Header-Feldern mehr Flexibilität und Zukunftssicherheit bietet. Hier sieht VMware zum Beispiel die Möglichkeit, Private VLANs innerhalb des Overlay-Netzwerks oder verteilte Routing-Informationen zu übermitteln (s. [2]). Beide Technologien bieten einen VNI (Virtual Network Identifier), der die Rolle einer VLAN ID im Overlay-Netzwerk übernimmt und mit 24 Bit mehr als 16 Millionen Werte annehmen kann. Diese große Menge von VNIs wird heute noch von keinem Produkt am Markt regulär unterstützt. Eine schematische Darstellung des Hauptunterschieds (optionale Header in Geneve) findet sich in Abbildung 4.
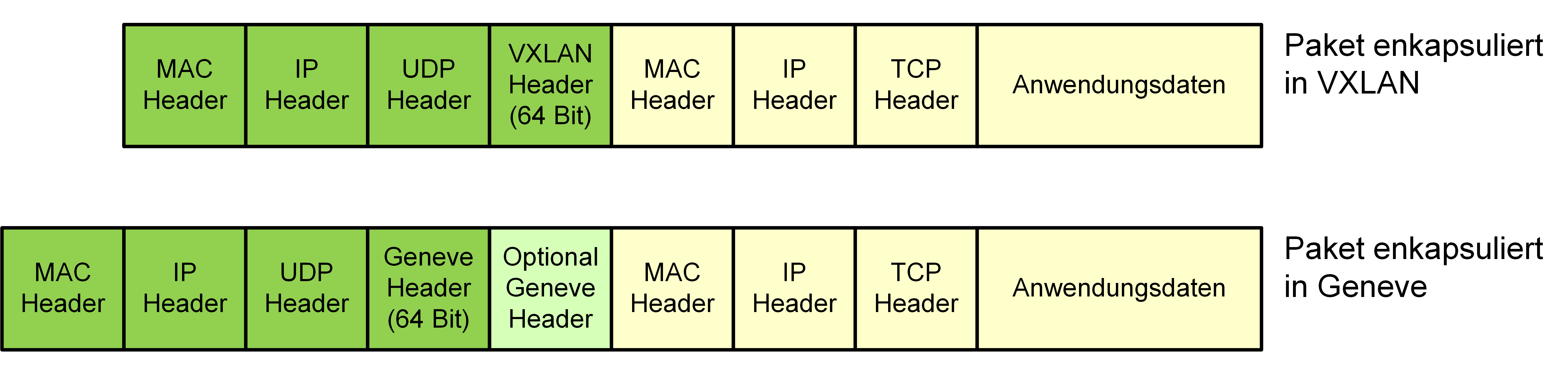
Abbildung 4: Header-Größen für VXLAN und Geneve
Unterstützte Hypervisoren und Integration in vSphere
Wie bereits erwähnt ist NSX-V speziell für die Nutzung in einer schon bestehenden VMware-Umgebung gedacht. Daher werden einerseits keine Hypervisoren von Drittherstellern unterstützt, andererseits ist die Integration in die schon bestehende GUI vorteilhaft für die Administration, sofern schon entsprechendes Know-how in der Bedienung von vSphere vorhanden ist. Die Management Appliance bietet hier zwar per Rest-API die Steuerung aller relevanten Funktionen, ihre eigene GUI ist aber aufgrund der Integration in vSphere stark reduziert. NSX-T hingegen ist als „Dritthersteller-Tool“ zu sehen, welches auch KVM-basierte Virtualisierungscluster um SDN-Funktionen erweitern kann. Die GUI des NSX-T-Managers ist dementsprechend so aufgebaut, dass sämtliche Funktionen von hier genutzt werden können.
Einen funktionalen Vorsprung besitzt NSX-T im Bereich der unterstützten Technologien auch jenseits des Hypervisors. So werden beispielsweise Container als eigenständige Endpunkte im Netzwerk unterstützt sowie die Anbindung von Public Clouds für Hybrid-Cloud-Szenarien.
Router-Typen
Die beiden NSX-Versionen unterstützen verschiedene Router-Typen, die sich sehr ähnlich sind, aber unterschiedliche Bezeichnungen haben. Generell bieten Edge (NSX-V) oder Tier-0 (NSX-T) Router einen erweiterten Funktionsumfang und mehr Leistung, sind aber dedizierte Appliances, so dass jedweder Traffic, der über diese Router läuft, zu einem bestimmten Virtualisierungshost übertragen wird. Sie stellen außerdem das Bindeglied zwischen SDN- und physischer Welt dar und übersetzen den Netzwerkverkehr, der zwischen NSX und externem Netzwerk ausgetauscht wird. DLRs oder Tier-1 Router erzeugen zwar auch eine virtuelle Appliance, Routing-Informationen werden aber über die angebundenen Virtualisierungshosts verteilt, so dass die beteiligten Komponenten die benötigten Ressourcen für das Routing über alle Hosts verteilt bereitstellen. Daher auch der Name DLR – Distributed Logical Router im Falle von NSX-V. Dies erfolgt in beiden NSX-Versionen über die Virtualisierungshosts verteilt, allerdings – wie in Tabelle 1 dargestellt – basierend auf unterschiedlichen virtuellen Switches. Beispiele für den Einsatz der verschiedenen Router-Typen sind in Kapitel 3.1 beschrieben.
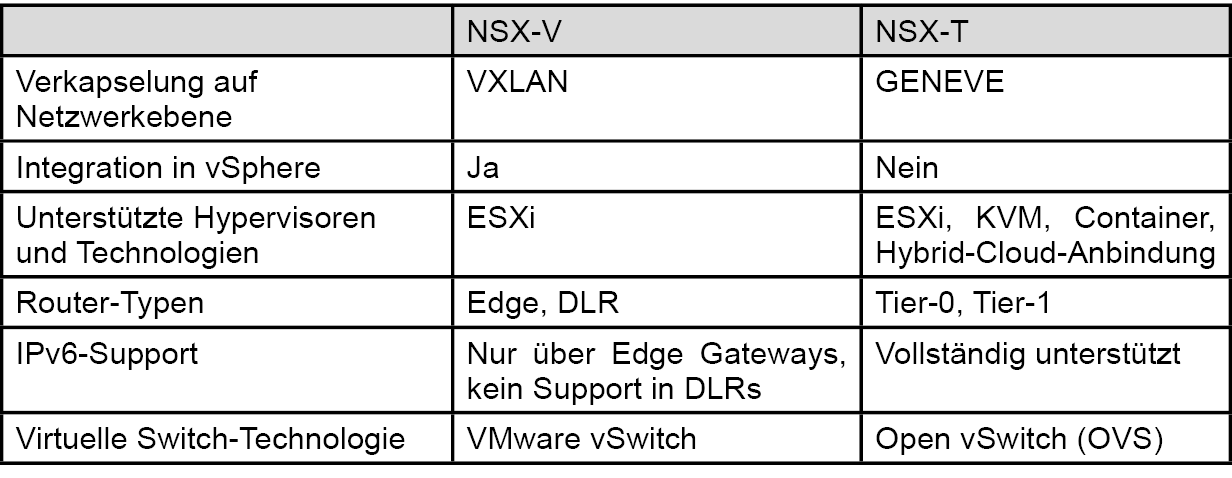
Tabelle 1: Vergleich der Kernelemente zwischen NSX-V und NSX-T
Auch die GUI der beiden Versionen unterscheidet sich maßgeblich voneinander. Beispiel-Screenshots für das zentrale Dashboard von NSX-V (oben) bzw. NSX-T (unten) sind in Abbildung 5 dargestellt.
Abbildung 5: Dashboard von NSX-V (oben) und NSX-T (unten)
3. Technische Funktionen und Auswirkungen
In diesem Kapitel werden die wichtigsten Funktionen von VMware NSX-V kurz erläutert. Anhand einer Beispielumgebung werden auch einige Details dargestellt.
3.1 Grundlegende Funktionen
NSX bietet eine ganze Reihe von Funktionen, die man auch im und in Verbindung mit dem physischen Netzwerk benötigt. Im Detail sind dies:
- Switching
- Routing
- Firewalls
- DNS-Weiterleitung (Forwarding)
- VPN-Tunnel
- DHCP-Relays
- Load-Balancer
- Gruppierung von Elementen
Mit der Mikrosegmentierung als häufigste Motivation für die Einführung von NSX sollen hier speziell diejenigen Funktionen genauer beleuchtet werden, die hierfür relevant sind. Diese sind:
- Logische Switches
- Distributed Firewall
- DLRs und Edge Gateways
- Security Groups
Die logischen Switches in NSX stellen dabei die zentrale Komponente des SDN dar, alle anderen Komponenten dienen der Virtualisierung von Netzwerk-Funktionen (NFV). Es wird hier jeweils die NSX-V-Variante betrachtet und dementsprechend auch die Nomenklatur aus NSX-V übernommen. NSX-T verhält sich äquivalent.
Logische Switches (SDN)
Das Kernstück von NSX stellen die logischen Switches dar. Diese stellen das NSX-Äquivalent eines Switches mit festem VLAN dar. Jedem logischen Switch wird ein Virtual Network Identifier (VNI) (bei NSX-V: VXLAN-ID) zugewiesen (s. Abbildung 3 (b)), welcher der logischen Separierung der Netzwerke untereinander dient. Für einen VMware-Administrator stellen sich diese wie Distributed Port Groups an einem vSwitch dar.
Distributed Firewall (NFV)
Die Distributed Firewall von NSX stellt die Basis für eine Mikrosegmentierung in NSX dar. Sie ist bei NSX-V im Kernel der Virtualisierungsserver verankert und unterstützt Filtern bis auf Ebene von TCP- und/oder UDP-Ports (Layer 4) für jede einzelne VM. Eine weitere Besonderheit ist, dass Regeln nicht nur auf IP-Adressen, sondern auf jeder Art von Objekt in der Virtualisierungsumgebung basieren können. Dies können beispielsweise VM-Namen, Gast-Betriebssysteme, Security Groups (s.u.) oder Tags sein, die zur Gruppierung von VMs genutzt werden. Dadurch ist Firewalling ohne Beschränkung auf IP-Adressen möglich. Dies kann zum Beispiel nützlich sein, um eine Netzwerk-Segmentierung einzuführen, ohne IP-Adressen zu ändern. Schematisch ist diese Loslösung von klassischen Subnetzen und IP-Adressen in Abbildung 2 dargestellt.
Wie bereits in Kapitel 1.2 beschrieben, sind diese Funktionen bei modernen Hardware-Firewalls zwar ebenfalls möglich, allerdings werden dafür in den meisten Fällen zusätzliche Tools wie ein Radius-Server oder eben eine Anbindung an eine SDN-Lösung wie VMware NSX benötigt.
Die Verwaltung der Firewall-Regeln erfolgt zentral und diese werden dann auf alle Virtualisierungshosts verteilt, so dass die notwendigen Ressourcen (CPU und Arbeitsspeicher) durch eine Vielzahl von Hosts bereitgestellt werden.
DLRs und Edge Gateways (NFV)
Die Router dienen der Verbindung von verschiedenen logischen Switches (DLR bzw. Tier 1) und der Verbindung von der VXLAN-basierten NSX-Welt mit der physischen Außenwelt (Edge Gateway bzw. Tier 0). Außerdem ermöglichen Tier 0 oder Edge Gateways auch das Routing zwischen verschiedenen Mandanten in einer Umgebung mit strenger Mandantentrennung. In diesem Fall befindet sich der Edge Gateway bzw. Tier-0-Router unter der Kontrolle des den Mandanten übergeordneten Betreibers.
Es können zwischen den Routern und auch mit der physischen Außenwelt Routen über verschiedene Routing-Protokolle ausgetauscht werden. NSX-T setzt ausschließlich auf BGP, NSX-V unterstützt BGP und OSPF. DLRs sind außerdem so realisiert, dass zur Nutzung statischer Routen die DLR-VM nicht benötigt wird, sondern nur, falls dynamisches Routing zum Einsatz kommt. Um ein dynamisches Routing auch bei Ausfall einer DLR-VM weiterhin zu ermöglichen, bietet sich die Nutzung der Hochverfügbarkeitsfunktionen der Virtualisierungsumgebung an. Wird diese Funktion nicht genutzt, kann ansonsten nicht schergestellt werden, dass Traffic zwischen verschiedenen Endpunkten korrekt geroutet wird.
Edge Gateways als Übergang zum physischen Netzwerk stellen einen potentiellen Bottleneck für die Bandbreite der Virtualisierungsumgebung dar. Daher empfiehlt VMware einen dedizierten „Edge Cluster“ in größeren Umgebungen und eine Kombination des Edge Clusters mit dem Management Cluster in kleineren Umgebungen. So wird vermieden, dass eventueller East-West-Traffic zwischen VMs auf unterschiedlichen Hosts die Bandbreite beim Übergang in das externe Netz beeinflusst. Für eine bessere Lastverteilung des Traffics „nach außen“ wird die Nutzung von Equal Cost Multipath (ECMP) empfohlen, welches die Netzwerklast auf bis zu 8 Edge Gateways verteilen kann. Eine solche Architektur wird in Kapitel 3.3 genauer dargestellt.
Security Groups
Security Groups bilden in NSX-V Gruppen von Objekten, die gemeinsame Sicherheitsrichtlinien erhalten sollen. Diese Objekte können z.B. VMs aber auch logische Switches oder VNICs sein. Auch eine automatische Zuordnung von neuen Objekten zu Security Groups ist möglich. Bei einem standardisierten Namensschema für virtuelle Maschinen können beispielsweise Teile dieses Namens für die Zuordnung genutzt werden. Dieses Kriterium wird aber von VMware explizit nicht empfohlen. Alternativ kann auch – sofern die entsprechenden Tools verfügbar sind – der Betriebssystem-Typ genutzt werden.
3.2 Anbindung an Dritthersteller-Tools
Bei der Einführung von NSX in eine schon bestehende Umgebung ist es häufig erstrebenswert, die neue Technologie in schon bestehende Verwaltungssysteme einzubinden. In bestimmten Umgebungen ergeben sich auch Compliance-Anforderungen, beispielsweise bezüglich der Überwachung und der Speicherung von Log-Daten. Eine beispielhafte Übersicht ist in Abbildung 6 dargestellt.
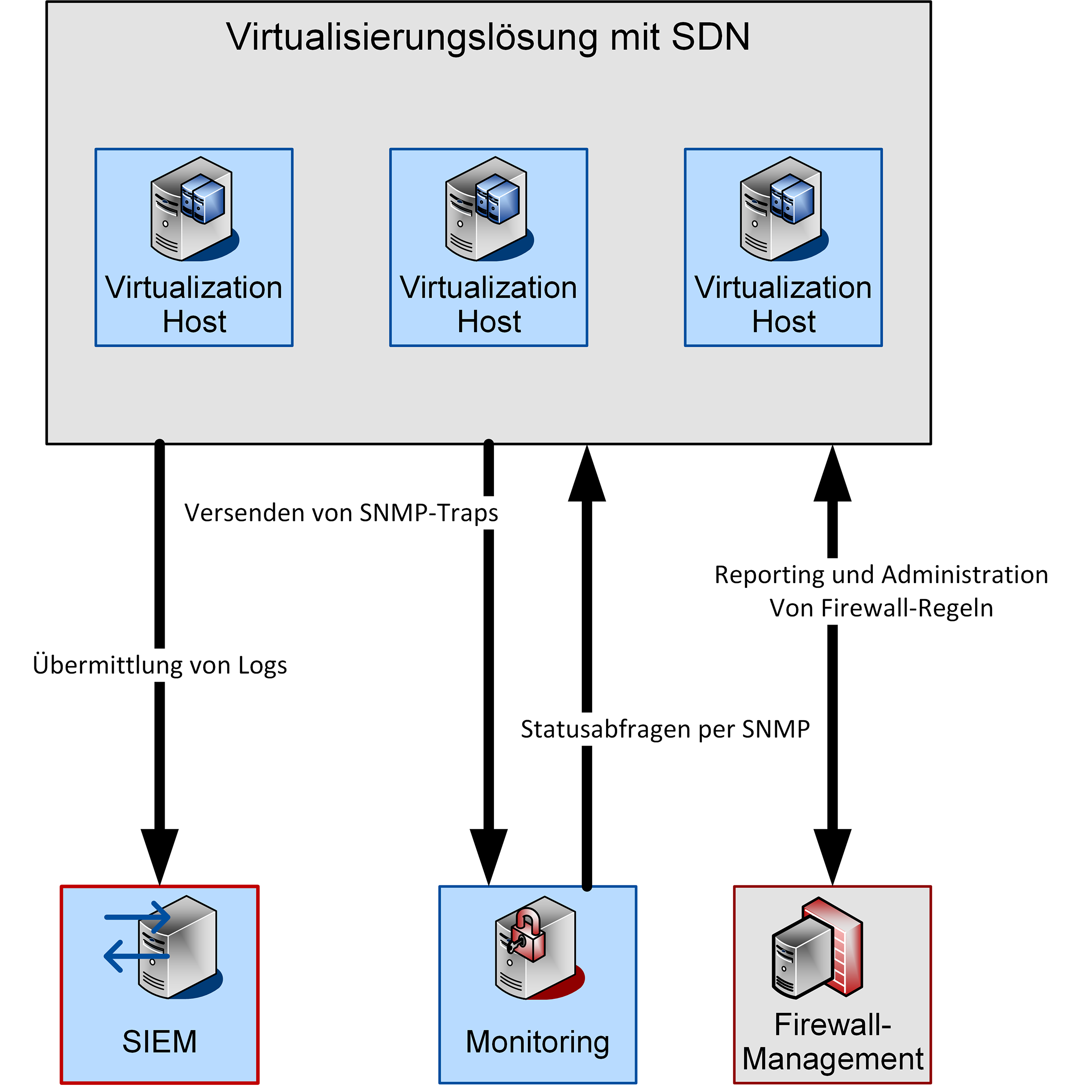
Abbildung 6: Anbindung von Drittherstellertools für Logging, Monitoring und Firewall-Management
Aus diesem Grund ist auch für NSX die Anbindung an Dritthersteller-Tools möglich und in einigen Bereichen explizit vorgesehen. Die Verfügbarkeit einer Rest-API ermöglicht beispielsweise die Anbindung an zentrale Firewall-Management-Tools wie Tufin.
Für die Anbindung an zentrale Logging- und Monitoring-Lösungen werden Standardprotokolle genutzt. Dabei können Logs an zentrale Systeme per Syslog versendet werden. Das Monitoring von NSX erfolgt per SNMP. Die Management-Appliance ist einerseits in der Lage, SNMP Traps zu verschicken. Andererseits können sämtliche sonstigen virtuellen Appliances – DLR, Edge Gateways und Controller VMs – per SNMP abgefragt werden.
3.3 Beispielumgebung
Eine Beispielumgebung für eine NSX-Umgebung ist in Abbildung 7 dargestellt. Wichtige Aspekte hier sind die Hochverfügbarkeit der Edge Gateways und der DLRs. Virtuelle Maschinen können, auch bei Einsatz von NSX, weiterhin an normalen Distributed Port Groups genutzt werden, ohne dass Anpassungen notwendig sind. Die Distributed Firewall ist aber auch für diese VMs aktiv, so dass auch „alte“ VMs von einer Mikrosegmentierung profitieren. Um die Verfügbarkeit bei Ausfall einer Appliance und Nutzung von dynamischem Routing weiterhin zu gewährleisten (s.o.), ist die gängige Lösung für DLRs, wie schon erwähnt, die Nutzung der HA-Mechanismen in NSX. Die Anbindung an die „Außenwelt“ erfolgt, wie von VMware empfohlen und bereits erwähnt per ECMP. Dies führt jenseits der verbesserten Ausfallsicherheit auch zu einer besseren Auslastung der Netzwerk-Interfaces und einer größeren Gesamtbandbreite in das physische Netz.
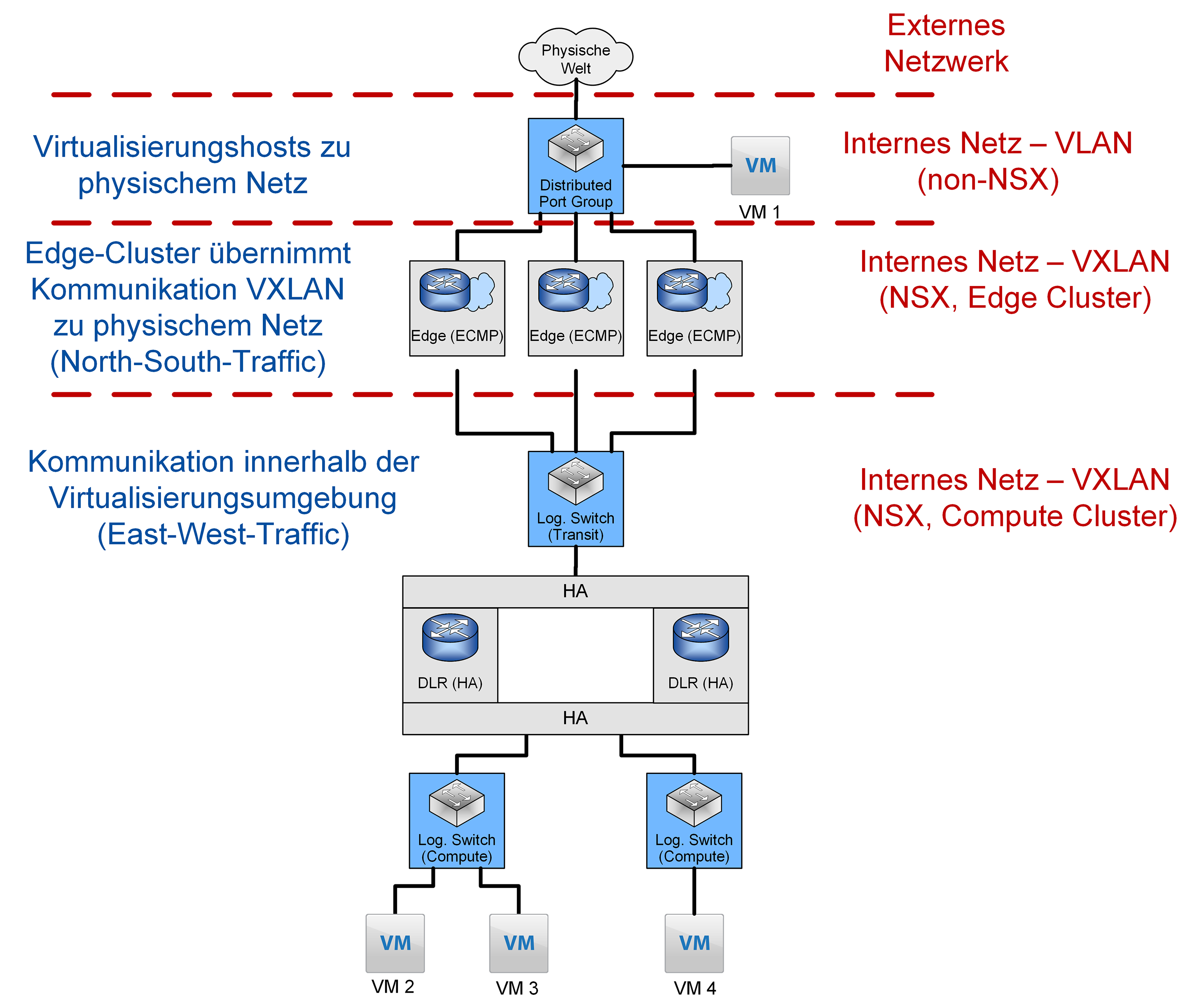
Abbildung 7: In NSX umgesetzte Beispiel-Umgebung
Performance-Impact von NSX
SDN und NFV, insbesondere die Verkapselung und die Distributed Firewall, benötigen natürlich Ressourcen auf den beteiligten Hosts. Dies würde auch für andere Elemente von NFV gelten, zum Beispiel das Load Balancing. Verkapselung und Distributed Firewall sollen hier aber im Fokus stehen, da diese in jeder Umgebung eine Rolle spielen, in der eine Mikrosegmentierung eingeführt werden soll. Nicht umsonst sind Data Center Firewalls normalerweise mit vielen CPU-Kernen (oder Spezialchips) und viel Arbeitsspeicher ausgestattet, um allen relevanten Traffic zu filtern. Daher stellt sich auch die Frage, welche Auswirkungen der Einsatz von NSX auf die Auslastung der Virtualisierungshosts hat. Eigene Tests zwischen verschiedenen VMs haben dabei für eine Übertragungsrate von ca. 8 Gbit/s folgende Host-CPU-Auslastung ergeben (pro Host 32 physische Kerne):
- NSX zu non-NSX: 1,2 % non-NSX-VM, 2,6 % bei NSX-VM
Abbildung 7, VM 1 zu VM 2 - NSX zu NSX, Firewall geschlossen: 2,5 % an sendendem Host
Abbildung 7, VM 2 zu VM 4 - NSX zu NSX, Firewall offen: Jeweils 2,5 % an sendendem und empfangenden Host
Abbildung 7, VM 2 zu VM 3
Diese Werte zeigen, dass die Funktionen von NSX beim Sizing der Virtualisierungshosts berücksichtigt werden müssen, um bei Lastspitzen eine gegenseitige negative Beeinflussung von Netzwerk-Funktionen und VM-Performance auszuschließen.
Zusammenfassung
Aus technischer Sicht ist NSX ausgereift und bietet umfangreiche Funktionen für das Management und den Betrieb aller relevanten Netzwerkfunktionen. Einschränkungen ergeben sich v.a. dadurch, dass die Firewall nur bis OSI Layer 4 filtert und Next-Generation-Funktionen nicht vorhanden sind. Hierzu können Dritthersteller-Tools eingebunden werden, die allerdings den betrieblichen Aufwand erhöhen.
4. Betriebliche Aspekte
Die technischen Aspekte, wie sie im letzten Kapitel dargestellt wurden, sind nur ein Teil des erfolgreichen Einsatzes von NSX bzw. einer NVL. Der andere, in den meisten Fällen weitaus wichtigere und aufwendigere Teil betrifft den Betrieb und die Betriebsprozesse. Speziell Teamstruktur und Kommunikationskultur spielen eine entscheidende Rolle. Im Folgenden soll anhand eines Beispielprozesses dargestellt werden, welchen Einfluss die Einführung eines SDN-Produktes auf den Betrieb hat.
Beispielprozess – Ausgangslage
Als Beispiel soll hier die Erstellung einer virtuellen Maschine in einem Netzsegment dienen, die zusätzlich Kommunikationsbeziehungen zu einem anderen Netzsegment benötigt.
Die grundlegenden Schritte sind in Abbildung 8 dargestellt. Dabei wird von einem Unternehmen mit „Silos“ für die Bereiche Sicherheit, IP-Adressmanagement (IPAM), Netzwerk, Firewall und Virtualisierung ausgegangen. Die Details des Prozesses sind wenig relevant und von Unternehmen zu Unternehmen unterschiedlich. Die wichtigsten Aspekte dabei sind:
- Eine große Anzahl beteiligter Teams
- Eine große Zahl von sequentiellen Schritten, die abgearbeitet werden müssen
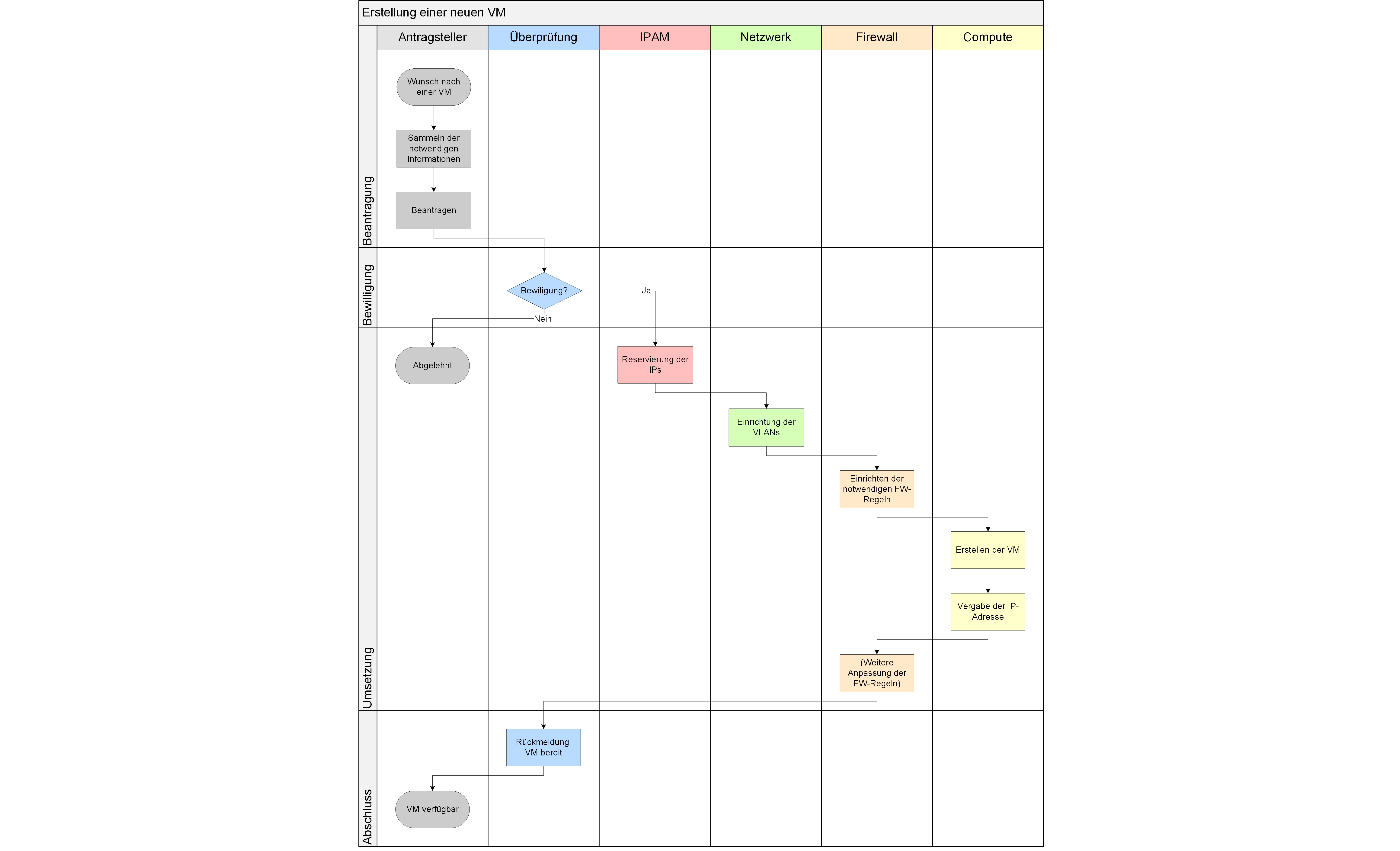
Abbildung 8: Beispielprozess zur Erstellung einer VM in einem neuen Netzsegmen
Grob dargestellt gestaltet sich der Prozess wie folgt:
Ein Antragsteller sammelt die notwendigen Informationen wie Netzsegment, Kommunikationsbeziehungen und Grund für die Anforderung des Systems. Die Überprüfung und Genehmigung erfolgt in einer eigenen Abteilung und basiert auf den Informationen des Antragstellers. Wird dem Antrag stattgegeben, müssen folgende Aktionen (sequentiell) von den jeweiligen Abteilungen durchgeführt werden, um dem Antragsteller das System zur Verfügung zu stellen:
- IPAM: Ein IP-Adressbereich wird für die neue VM bereitgestellt.
- Netzwerk: Die notwendigen VLANs werden eingerichtet.
- Firewall: Auf der Firewall wird das neue Netzsegment mit dem zugehörigen IP-Adressbereich angelegt.
- Compute: Die VM wird erzeugt.
- Firewall: Die vorgesehenen Kommunikationsbeziehungen müssen eingerichtet werden.
- Antragsteller: Dem Antragsteller wird mitgeteilt, dass sein System fertiggestellt ist.
Auf Basis dieses Prozesses, der viele Aspekte des alltäglichen Betriebs berücksichtigt, werden im Folgenden die notwendigen Anpassungen für den Einsatz einer SDN-Lösung an diesem Prozess dargestellt.
Anpassungen am Prozess unter Beibehaltung von Silos
Bei der Einführung von NSX ergibt sich vor allem eine Änderung bei der Verwaltung von Netzsegmenten. Da bei der Erstellung von Firewall-Regeln und damit bei der Abbildung von Kommunikationsbeziehungen mit Objekten statt IP-Adressen oder Subnetzen gearbeitet wird, können Netzsegmente innerhalb von NSX per Security Groups oder Tags dargestellt werden. In einem Umfeld, in dem eine bestehende physische Umgebung eingebunden werden soll, ergeben sich somit zusätzliche, aber überschaubare Arbeitsschritte.
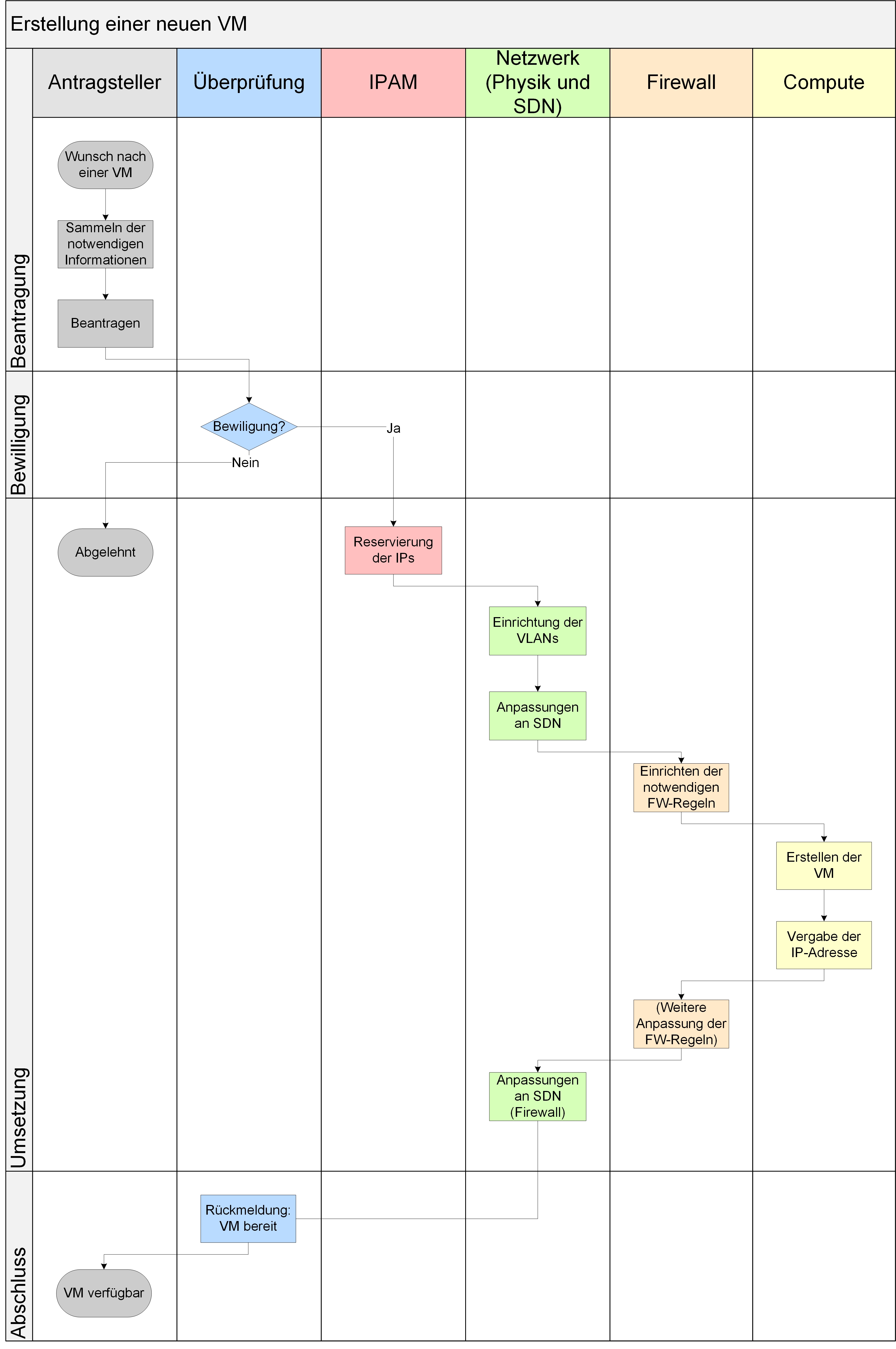
Abbildung 9: Beispielprozess zur Erstellung einer VM in einem neuen Netzsegment mit Nutzung von SDN
In einem Umfeld, in dem die einzelnen Abteilungen als Silos funktionieren, wird der Prozess durch die Einführung von SDN zusätzlich verkompliziert. Wie stark der Aufwand steigt, hängt davon ab, welcher der Silos später den Betrieb der Lösung übernehmen soll. In den folgenden Beispielprozessen wird davon ausgegangen, dass der Betrieb an den Netzwerk-Silo fällt.
Dabei fällt auf, dass durch die Konfiguration der SDN-Umgebung nur zusätzlich Schritte hinzugekommen sind. Eine Vereinfachung von Prozessen findet in dieser Kombination nicht statt.
In einer komplett virtualisierten Umgebung gestaltet sich dieser Prozess selbst bei Beibehaltung von Silos deutlich einfacher, wie er in Abbildung 10 gezeigt ist. Dadurch, dass sämtliche Netzwerk- und Firewall-Konfiguration in der NVL vorgenommen werden kann und das physische Netzwerk nicht mehr angepasst werden muss, entfallen hier die Aufgaben der Abteilung Firewall und Teile der Aufgaben der Abteilung Netzwerk. In diesem Beispiel bleibt die Einbindung der Abteilung IPAM für eine IP-Adressvergabe bestehen.
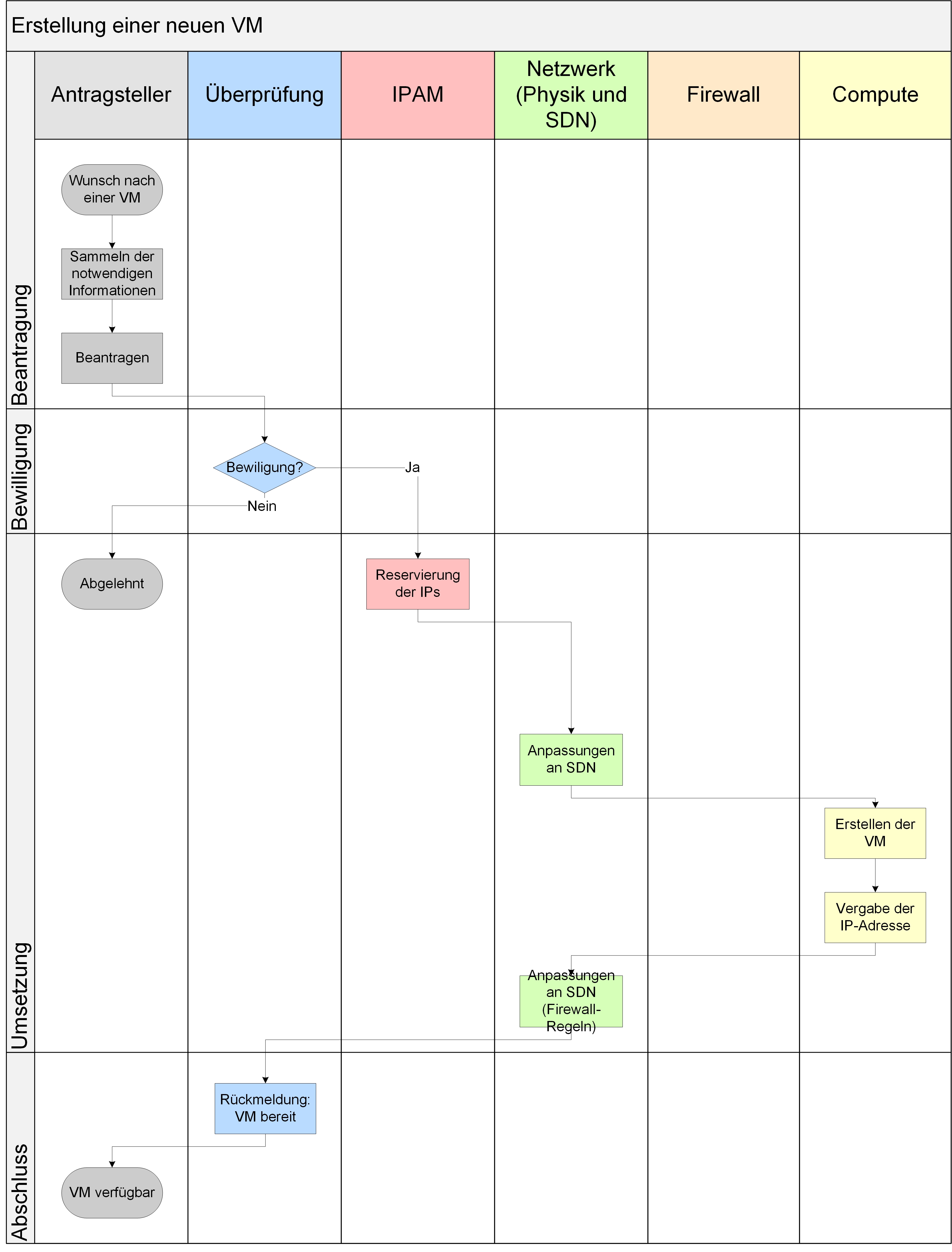
Abbildung 10: Beispielprozess neue VM in neuem Netzsegment in komplett virtualisierter Umgebung
Für den Einsatz von SDN empfohlene Anpassungen an der Team-Struktur
Für eine Verringerung des betrieblichen Aufwands wird von den meisten Herstellern von Lösungen im Bereich SDN und SDDC (Software-Defined Data Center) empfohlen, bestehende Silostrukturen abzubauen und Teams zu bilden, die alle Aspekte des IT-Betriebs vereinen. Eine gute Darstellung hierzu findet sich in [3].
Bei einem Zusammenlegen der Teams ergibt sich daraus ein vereinfachter Prozess, wie er in Abbildung 11 dargestellt ist. Dieser Prozess geht immer noch von einer Anbindung physischer Endgeräte aus, wie zum Beispiel physische Datenbankserver. Durch die Zusammenlegung der Teams wird vor allem die Kommunikation stark vereinfacht.
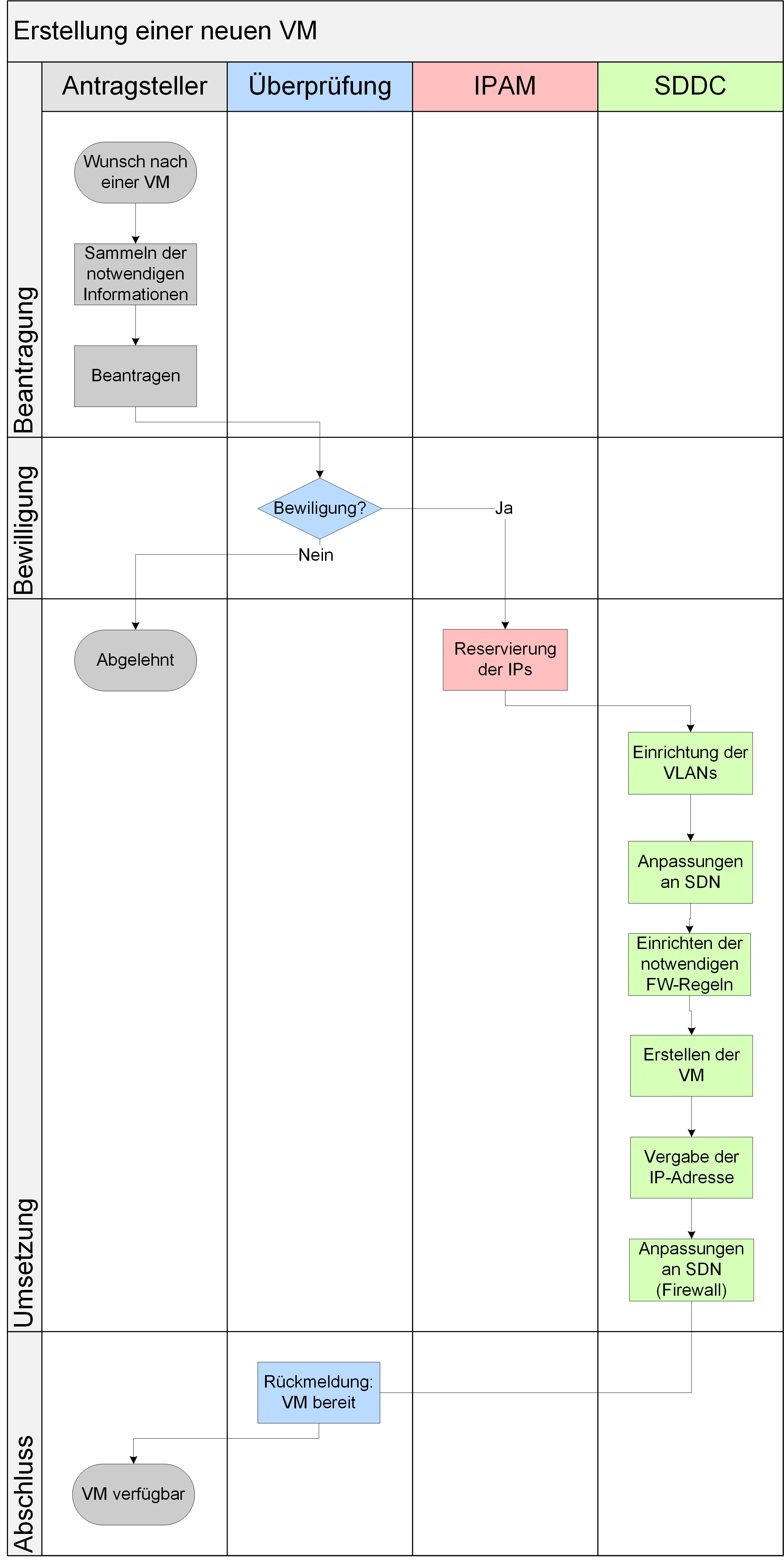
Abbildung 11: Beispielprozess in einer Organisation ohne Silos
In einem vollständig virtualisierten Rechenzentrum, also einem umfassenden SSDC ohne physische Endgeräte, reduziert sich der Aufwand erneut, da das physische Netzwerk nicht angepasst werden muss. Diese Darstellung findet sich in Abbildung 12.
Diese Prozesse gehen davon aus, dass Anpassungen an den entsprechenden Komponenten (IPAM, Netzwerkkomponenten, Firewall(s) und Virtualisierungsumgebung) größtenteils manuell erfolgen. Daher ergibt sich auch bei jeder abgeschlossenen Arbeit einer Abteilung zusätzlicher Aufwand durch die Kommunikation zwischen den verschiedenen Abteilungen.
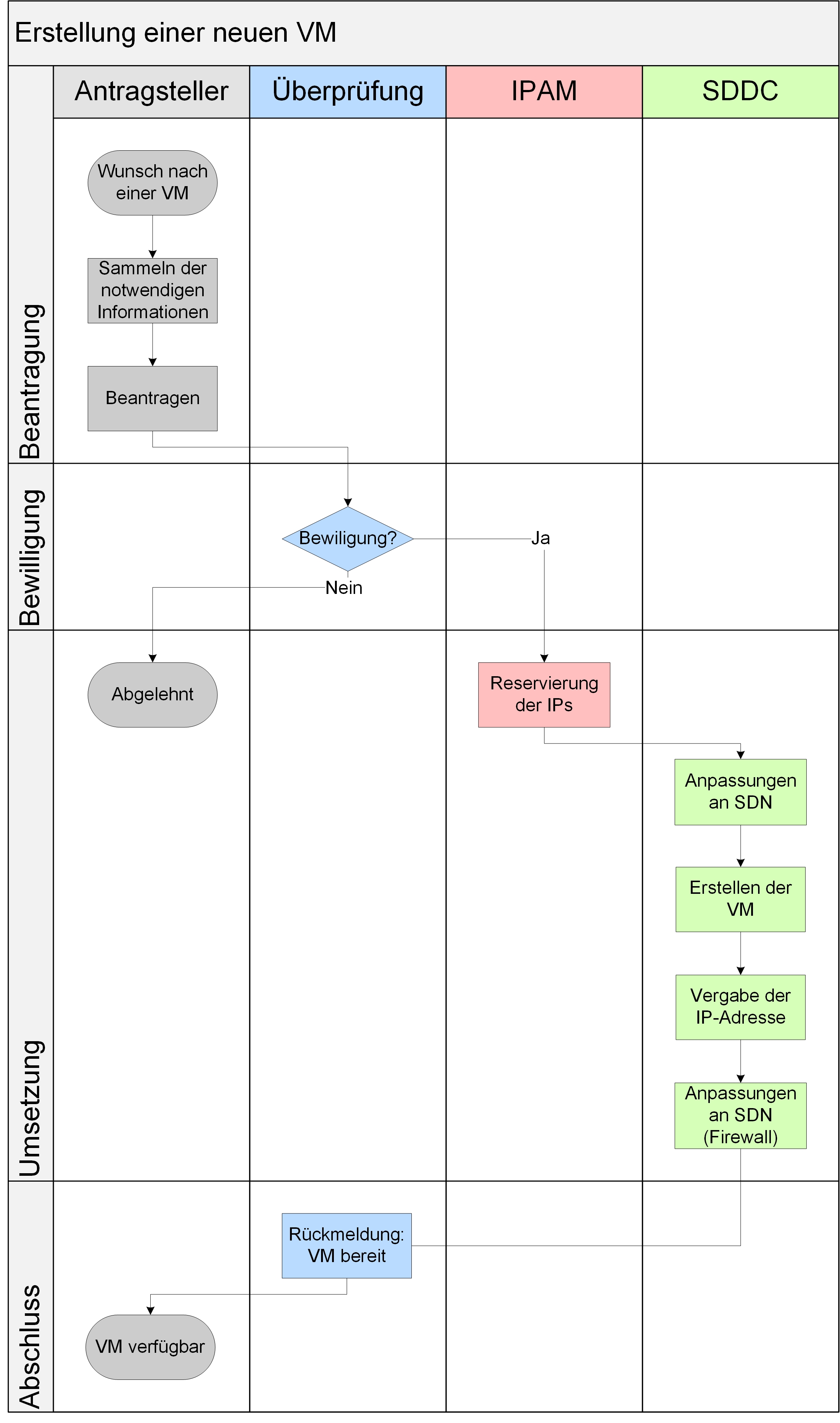
Abbildung 12: Optimierter Prozess bei der Nutzung von NSX in vollständig virtualisierter Umgebung
Eine weitere Vereinfachung ist durch eine Automatisierung der Prozesse möglich, die eine Kommunikation zwischen den Abteilungen reduziert. Diese Automatisierung ist Teil des nächsten Kapitels.
5. Automatisierung in und mit NSX
Für eine Optimierung durch Automatisierung müssen entsprechende Mechanismen in den genutzten Produkten vorhanden und einfach benutzbar sein. Bei der reinen Nutzung von NSX, ohne zusätzliche Tools, ist die Automatisierung recht eingeschränkt. Lediglich die automatische Zuordnung von Objekten zu Security Groups ist „von Hause aus“ möglich.
Eine weitere Automatisierung ist nur bei Nutzung zusätzlicher Tools möglich. Hier gibt es drei Ansätze, die im Folgenden kurz dargestellt werden sollen. Eine Zusammenfassung der Vor- und Nachteile der einzelnen Lösungen findet sich in Tabelle 2.

Tabelle 2: Vor- und Nachteile verschiedener Automatisierungsansätze
Entwicklung eigener Tools
Durch Nutzung der Rest-API von VMware NSX ist es möglich, eigene Software zu entwickeln, die Teile der Bereitstellung automatisiert. Sollten schon umfangreiche Tools vorhanden sein, kann eine Anpassung für NSX sinnvoll sein. Wenn allerdings noch keinerlei Automatisierung vorhanden ist, sollte eine Aufwandsabschätzung erfolgen. Sofern nur bestimmte Funktionen automatisiert werden sollen, kann eine Entwicklung sinnvoll sein. Die Entwicklung einer umfassenden Automatisierungslösung ist aufgrund des hohen Aufwands und auch des hohen Fehler-Risikos oft nur bei großen Umgebungen mit vielen Virtualisierungshosts und unterschiedlichen Mandanten sinnvoll.
Nutzung von Hersteller-Tools
Die Nutzung von Tools aus dem Portfolio von VMware bietet eine einfache, wenn auch kostenintensive, Alternative zu einer Eigenentwicklung. Von VMware werden die Tools „vRealize Operations“ (vRO) und „vRealize Automation“ (vRA) platziert, welche eine Zusammenstellung verschiedener Arbeitsschritte zur Automatisierung beinhalten. Es sind in diesen Tools auch Elemente vorhanden, die Drittherstellertools ansprechen können, um zum Beispiel IP-Adressen in einem IPAM zu reservieren. vRO richtet sich primär an Administratoren und bietet eine GUI zur Erstellung und Ausführung von Workflows, die eher an klassische Skripte erinnern. vRA erweitert vRO um eine grafische Oberfläche und Funktionen wie ein Self Service Portal, in dem User Systeme ähnlich wie in einer Cloud anfordern können. Um den User nicht zu überfordern, wird ihm eine Reihe von Templates für virtuelle Systeme präsentiert, die von den Administratoren vorbereitet und verwaltet werden.
Nutzung von Dritthersteller-Tools
VMware NSX wird auch von Plattformen anderer Hersteller unterstützt, die dann die Rest-API für die automatisierte Konfiguration des Netzwerks nutzen. Hier gibt es ebenfalls eine Vielzahl von Produkten, die nur anhand von Beispielen dargestellt werden sollen. Eine genaue Beschreibung dieser Lösungen würde den Rahmen dieses Artikels sprengen.
Von Interesse sind in größeren Umgebungen sog. Cloud Management Plattformen (CMPs), auch Cloud Broker genannt. Diese bieten eine Anbindung an verschiedene Virtualisierungs- und SDN-Lösungen. Dabei bieten sie eine Mandantentrennung und ein Self-Service-Portal für die Kunden (interne wie externe). Damit decken diese Lösungen einen ähnlichen Funktionsumfang ab wie VMware vRealize Automation, können aber im Allgemeinen eine breitere Auswahl von Herstellern anbinden. Produktbeispiele in diesem Umfeld sind BMC Cloud Lifecycle Management (CLM) Oder ActiveEon ProActive. Die Zielgruppe der jeweiligen Lösung sowohl auf Administrator- als auch auf Nutzerseite kann unterschiedlich sein. BMC bietet hier eine typische Cloud-Umgebung mit Self-Service-Portal an, ActiveEon bietet eher eine Automatisierung von Workflows aus dem Bereich High Performance Computing.
6. Fazit
Software-Defined Networking im Allgemeinen und VMware NSX im speziellen bieten viele Ansätze, welche die Administration von Netzwerken für virtuelle Maschinen vereinfachen können. Insbesondere die Mikrosegmentierung bietet neue und effiziente Ansätze zur Absicherung von VMs. Allerdings ist diese Technologie keine „Silver Bullet“, welche die Administration des Netzwerks auf magische Weise einfach und sicher macht. Insbesondere die Planung der (virtuellen) Netzwerke und deren Einrichtung sowie die korrekte Platzierung von VMs und die Erstellung von Regeln spielen, wie im „klassischen“ Netzwerk auch, eine entscheidende Rolle und müssen nach einer erfolgreichen Implementierung immer wieder überprüft und optimiert werden.
Der Betrieb einer SDN-Lösung oder sogar eines vollständigen SDDCs stellt viele Firmen vor neue Herausforderungen:
- Wer trägt die Verantwortung für die SDN-Lösung?
- Wie wird der Betrieb der Lösung in bestehende Prozesse integriert?
- Welche Kommunikations-Schnittstellen bestehen beim Einsatz von SDN/SDDC?
Diese Fragen müssen vor der Anschaffung und der Implementierung einer solchen Lösung geklärt sein. Speziell ein Aufbrechen der, oft noch vorhandenen, Silos ist für den Einsatz einer umfangreichen SDDC-Lösung fast unumgänglich. Sollten Sie also den Einsatz einer solchen Lösung in Erwägung ziehen, holen Sie alle Stakeholder an einen Tisch und machen Sie sich gemeinsam Gedanken zu den notwendigen Transformationen! Dann kann SDN für Sie und Ihre Mitarbeiter oder Kollegen eine Möglichkeit sein, die Arbeitsbelastung für den alltäglichen Betrieb Ihrer Umgebung zu reduzieren und mehr Zeit in Innovationsprojekte zu investieren!
Verweise
[1] J. Wetzlar, „Cisco „Campus Fabric“ oder Software-defined Access,“ Der Netzwerk-Insider, pp. 21-26, August 2017.
[2] B. Davie, „VMware | OCTO Blog,“ 13 Juni 2014. [Online]. Available: https://octo.vmware.com/geneve-vxlan-network-virtualization-encapsulations/.
[3] K. Lees, „Operationalizing VMware NSX,“ 2017.
Kommunikation im Wandel
Wie Cloud Produkte die bekannte Telefonie ersetzen
Fortsetzung
Wer den Kommunikationsmarkt in den vergangenen 10 Jahren beobachtet hat, der konnte zwei bestimmende Strömungen wahrnehmen:
1. VoIP und UC haben in modernen Büro-Umgebungen die Kommunikation stark vereinfacht und flexible Arbeitsmodelle kostengünstig ermöglicht.
2. Die klassische Kanalvermittlung, incl. DECT, ist im Bereich der Produktion nur schwer zu ersetzen.
Was aber beide Strömungen gemein haben, ist die Tatsache, dass sie bis heute meist auf lokale Infrastrukturen aufsetzen.
Dieser Umstand ist ja auch zunächst nicht verwunderlich. Warum sollte ein Service wie die Telefonie anders bereitgestellt werden als zum Beispiel die Infrastruktur eines LANs?
Beide Dienste stellen Anforderungen an die lokale Verfügbarkeit. Hier der LAN Port am Switch, dort das Tischtelefon. Daher scheint es nur logisch, solche Dienste lokal zu betreiben.
Diese Sichtweise gerät jedoch seit nunmehr fünf Jahren immer härter unter Beschuss.
Wie konnte das passieren?
Nun, aus der Vergangenheit kennen wir Centrex Dienste. Diese Dienste beruhten auf der Bereitstellung einer vollständigen, unternehmensweiten Telefon-Infrastruktur durch einen Provider. Die ersten dieser Services wurden in den 1960er Jahren in New York eingerichtet und hatten in der Spitze weltweit bis zu 20 Millionen Nutzer. Davon entfielen jedoch fast 85% auf die USA und Kanada, so dass man wohl von einem lokalen Phänomen sprechen konnte.
Jedoch ist diese Grundidee nicht mit der Kanalvermittlung verschwunden. Mit dem Aufkommen der Kommunikation über IP sollte diese Art der Bereitstellung einen neuen Schwung aufnehmen, den sie bis heute trägt und immer beliebter macht.
Durch den Einsatz eines unabhängigen Transportnetzes, welches genau wie vormals die Telefonie mit dem Rest der Welt verbunden ist, stellt sich nicht mehr die Frage „Wo“ ein Dienst angeboten wird.
Ein solcher Service kann heute geographisch unabhängig für alle Teilnehmer erbracht werden.
Dieses Grundprinzip kennen wir alle durch den Einsatz unternehmensweiter, zentraler VoIP- und UC-Lösungen. Warum also nicht die eigene Infrastruktur durch einen zentralen Dienst beim Provider ersetzen? Also den eignen zentralen Ansatz konsequent weiterentwickeln?
Und genau an diesem Punkt sind wir heute angekommen.
Schauen wir daher einmal näher auf den Markt der PBX Anbieter. Alle wichtigen Marktteilnehmer haben ihr Produktportfolio in Richtung von Cloud-Angeboten erweitert, und das bisher noch unter Beibehaltung ihrer klassischen Produkte und Lösungen.
Aber einige von ihnen haben sich schon auf den Weg gemacht, diese bisherigen Angebote auszudünnen bzw. zukünftig den Bereich der lokalen Installationen vollständig einzustellen oder auslaufen zu lassen.
Ein gutes Beispiel für eine solche Entwicklung ist die Firma Microsoft. Seit der Einführung von Office 365 gehörte zum festen Bestandteil der kompletten Lösung immer auch die lokale Verfügbarkeit eines Lync- oder Skype-for-Business-Servers. Mit der Entwicklung des cloudbasierten Telefon-Services hat sich diese Betrachtung jedoch massiv verändert.
Der aktuelle Skype for Business Server, der im letzten Jahr vorgestellt wurde, ist voraussichtlich die letzte Variante, die noch für eine lokale Installation vertrieben wird.
Derzeitige Aussagen von Microsoft lassen vermuten, dass es keinen Nachfolger für dieses Produkt geben wird, so dass wir heute schon sagen können, dass ab 2024 oder 2025 das Ende der lokalen Telefonie im Rahmen von Microsoft-Lösungen eingeläutet wird.
Diese Betrachtung führt uns aber noch weiter, denn ähnlich wie es dem Skype for Business Server ergehen wird, so wird auch das lokal installierte Office Paket in der Zukunft vom Markt verschwinden. (siehe Abbildung 1)
Abbildung 1: Microsoft Teams
Es sind die Aussagen von Satya Nadella, dem Chef von Microsoft, die diese Entwicklung unterstreichen: Mobile First, Cloud First!
In diesem Szenario werden am Ende weltweit über 80% aller Unternehmen ihr Office aus der Cloud beziehen. Schon heute ist Office 365 eine Voice-, Video-, Unified-Communications- und Collaboration-Plattform, die eine klassische TK- und UC-Lösung überflüssig macht.
In Kombination mit dem im Consumer-Markt beheimateten Skype könnte somit eine Plattform entstehen, über die mehrere 100 Millionen Nutzer weltweit direkt miteinander kommunizieren können.
Die daraus resultierende und – zugegeben – recht ketzerische Frage lautet dann folgerichtig:
• Wozu benötige ich dann noch einen Telefonie-Provider?
Denn eine Grundvoraussetzung für die Nutzung dieser Dienste ist der Zugang zur Office-Cloud über das Internet.
Nun wird der ein oder andere Leser vehement mit dem Kopf schütteln und einwenden, dass „sowas“ über das Internet nicht funktionieren kann, da man die Kontrolle über den Datenaustausch verliert.
Aber stimmt das wirklich?
Unternehmen wie NFON oder sipgate betreiben auf dieser Basis erfolgreich seit Jahren ihr Geschäftsmodell. Viele von unseren Lesern haben, wie auch wir, die Erfahrung gemacht, dass solche Lösungen durchaus eine ausgereifte, technisch verlässliche Plattform darstellen.
Und machen wir uns nichts vor: die Ressourcen, die im Internet zur Verfügung gestellt werden, übersteigen oft die doch recht teuren MPLS-Netze, die wir von unseren Providern anmieten.
Allerdings stellen Provider wie Microsoft auch gewisse Anforderungen an die Konnektivität. So müssen Jitter- und Delay-Voraussetzungen erfüllt werden, und es ist ausreichend Bandbreite beim Internetzugang zu berücksichtigen. Tabelle 1 und 2 sollen dabei die Situation verdeutlichen, in die wir uns bei einer entsprechenden Umstellung begeben.
Tabelle 1 verweist auf klassische QoS Paramater, die eingehalten werden müssen. Interessant ist dabei der Hinweis auf den Microsoft Edge. Welche Aussage verbirgt sich dahinter?
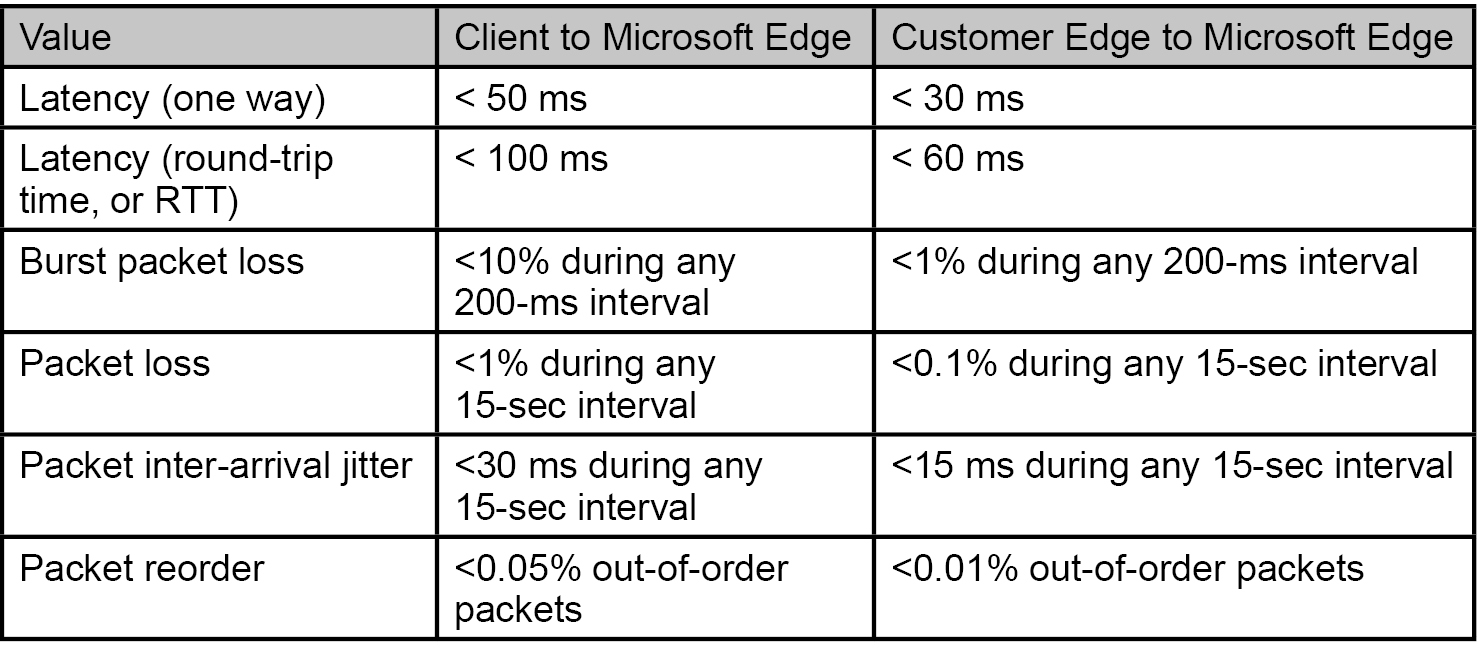
Tabelle 1: Jitter und Delay Anforderungen
Bisher sind wir immer davon ausgegangen, dass wir eine Internetverbindung zur Kommunikation nutzen.
Ist das aber wirklich so? Nein, nicht so ganz, denn über das Internet wird nicht wirklich eine Ende-zu-Ende-Kommunikation etabliert.
Zunächst einmal nutzen wir unser eigenes Unternehmens-LAN bis zur Internet DMZ. Von dort aus geht der Weg über den ISP zum Cloud Anbieter.
Dieser Cloud Anbieter, in unserem Fall Microsoft, unterhält ein eigenes weltumspannendes Cloud-Netzwerk, man könnte es auch als Corporate WAN bezeichnen. Dieses Cloud WAN hat an vielen öffentlichen Internetknoten weltweit direkte Zugänge und Verbindungen zu Providernetzen (PoP, Point of Presence). Dies bedeutet für einen Kunden z.B. in Deutschland, dass er das Internet tatsächlich nur von seinem Anschluss-Punkt bis zum DE CIX in Frankfurt nutzt und dort direkt in das Cloud-Netzwerk des Anbieters geroutet wird.
Dieser Microsoft PoP (Point of Presence) in Frankfurt wäre dann der in der Tabelle erwähnte Microsoft Edge. Dies erklärt dann auch die – im Verhältnis zu den ITU-Vorgaben – kurzen Zeiten für die Verzögerung von lediglich 30 bzw. 50ms statt der bekannten 180ms aus der ITU Empfehlung.
Die restliche Zeit wird für den Transport durch das Microsoft Backbone benötigt.
Der zweite wichtige Faktor ist eine ausreichende Bandbreite des Internetzuganges. Um diese kalkulieren zu können, müssen zunächst die zu erwartenden Kommunikations-Beziehungen mit den dazugehörigen Bandbreiten berechnet werden.
Um ein Gespür dafür zu bekommen, was uns erwartet, müssen wir uns Tabelle 2 anschauen.
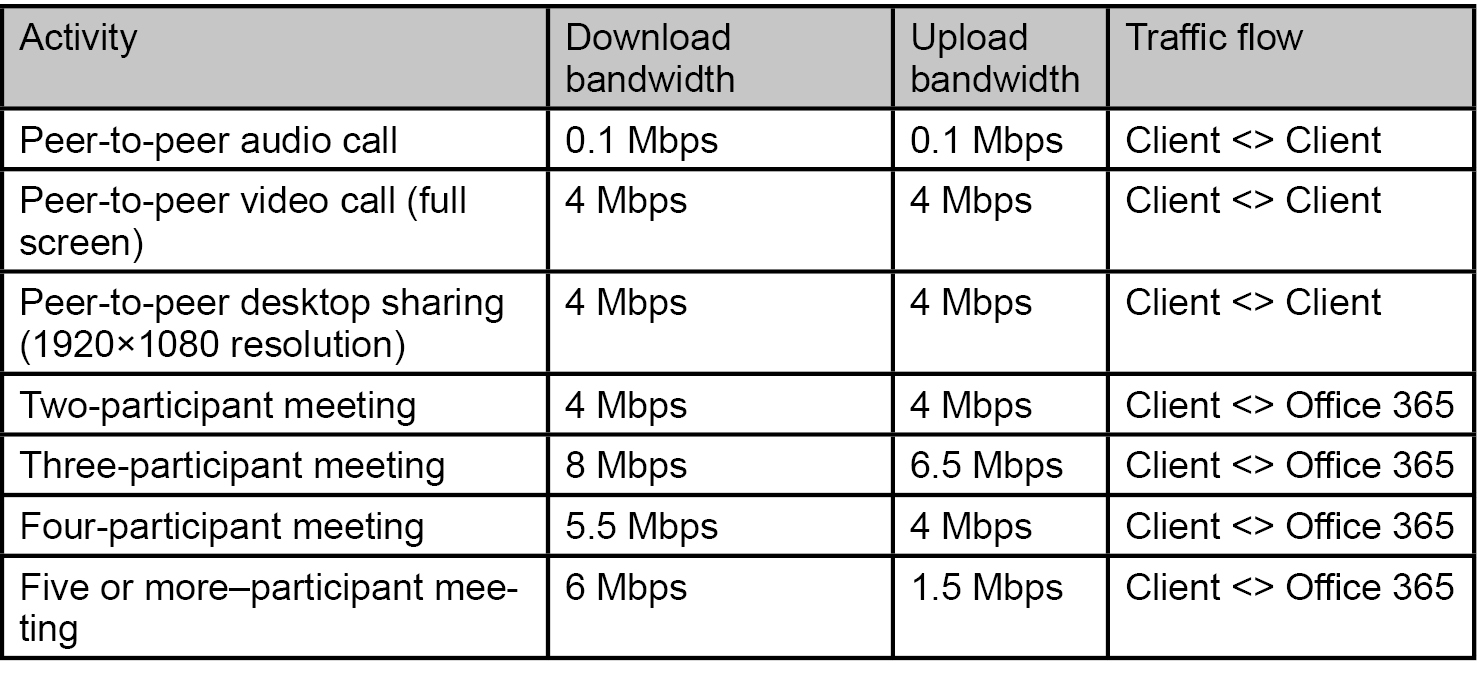
Tabelle 2: Bandbreiten Anforderung
Hierbei erkennen wir sehr schnell, dass gerade die intensive Nutzung von Video-Konferenzen den Bedarf an Bandbreite explodieren lassen kann. Während eine Punkt-zu-Punkt-Kommunikation wie bisher lokal stattfindet und somit nur die Signalisierung über die Cloud realisiert wird, gehen bei Konferenzen sämtliche Verkehrsströme über das Internet zum Cloud Anbieter.
Dieser Umstand stellt daher sehr hohe Anforderungen an die Bandbreite. Anschlüsse jenseits von 100 Mbit/s bis zu n-fach Gbit/s werden in einem solchen Szenario eher die Regel als die Ausnahme bilden.
Eine Alternative zur Nutzung des Internet ist die Möglichkeit, einen Co-Location Service in Anspruch zu nehmen.
Co-Location bedeutet zunächst nur, dass bei einem Rechenzentrums-Anbieter wie e-shelter oder Equinix ein oder mehrere Server-Racks angemietet werden können. Darüber hinaus können von einem solchen Rack direkt Verbindungen ins Internet oder zu Cloud-Anbietern wie Microsoft, Google oder Amazon zur Verfügung gestellt werden.
Die Anbindung dieser Racks an das eigene RZ erfolgt im Regelfall über einen MPLS Service oder über eine dedizierte Verbindung, die man bei einem lokalen oder überregionalen Provider einkaufen kann.
Hierbei sollte man allerdings berücksichtigen, dass eine solche Bereitstellung zu bedeutend höheren Kosten führt als die Nutzung des herkömmlichen Internetzuganges. Unsere Recherche hat dabei ergeben, dass es sich immer um Projektangebote handelt und diese sich, bei einer 1Gbit-Anbindung, in einem mittleren bis hohen 4-stelligen monatlichen Bereich bewegen.
Außerdem sollte man rechtzeitig klären, ob der Betreiber des Cloud-Services die Möglichkeit einer solchen Co-Location überhaupt zur Verfügung stellt. Anbieter wie Unify mit ihrer OpenScape Cloud Plattform stellen dies zwar in Aussicht, jedoch verfügbar sind solche Anbindungen noch nicht.
Eine Besonderheit hat an dieser Stelle Microsoft zu bieten. Hier gibt es mit ExpressRoute einen Zugang, der im Wesentlichen mit dem übereinstimmt, was wir schon im Abschnitt Co-Location betrachtet haben.
Gedacht ist dieses Produkt als direkter Zugang zur Azure Cloud, allerdings unter Ausschluss von Office 365.
Wer also mit dem Gedanken spielt, Office 365 unter Umgehung des Internet mittels ExpressRoute anzusprechen, wird keinen Erfolg haben. Microsoft unterbindet jeglichen Datenaustausch, der entsprechend adressiert ist. Einzige Ausnahme: man bittet Microsoft um eine Einzelfallprüfung und kann gut begründet darlegen, warum man diese Variante benötigt.
Nun könnte man versucht sein zu sagen: dass Microsoft ihren Schwerpunkt in der Cloud sieht, verwundert mich nicht, aber die anderen Marktteilnehmer sehen das bestimmt anders.
Diese Annahme trifft nicht zu.
Egal wohin Sie schauen, alle bereiten sich auf das Zukunftsmodell Cloud vor:
• Cisco entwickelt WebEx Teams weiter und hat mit Broadsoft einen der größten Anbieter von cloudbasierten UC- und VoIP-Lösungen aufgekauft.
• Alcatel stellt mit Rainbow ein komplettes Cloud Portfolio für Kommunikation und Datennetze zur Verfügung und rundet dies mit der Akquise von sip:wise ab.
• Unify erweitert Circuit um OpenScapeCloud (OSC) und stellt damit ihre UC-Lösung als Public Cloud Service zur Verfügung.
• Avaya stellt mit der Avaya Cloud Business-Telefonie und Teamwork eine On-Demand Kommunikations-Lösung bereit.
Um diese Aussagen ein wenig zu konkretisieren, möchte ich an dieser Stelle die Lösung von Unify als Beispiel näher erläutern.
Warum gerade Unify? Nun, Unify ist einer der großen Anbieter im deutschen PBX-Markt, sowohl was VoIP bzw. Hybride als auch was klassische Telefonie betrifft.
Aber auch hier hat man die Zeichen der Zeit erkannt und entsprechend den Schwenk hin zu UCaaS-Produkten vollzogen. Zunächst mit Circuit als Cloud Collaboration Dienst ähnlich Microsoft Teams, und jetzt auch mit dem UC Softswitch von OSC (OpenScapeCloud).
Der Focus der Unify-Lösung liegt jedoch, im Gegensatz zu Microsoft, mehr auf den bisherigen Telefonie-Leistungsmerkmalen, erweitert um Kollaboration und Meeting.
Eine Office Integration inkl. gemeinsamer Dokumentenbearbeitung, wie sie Microsoft anbietet, finden wir hier dagegen aktuell vergebens.
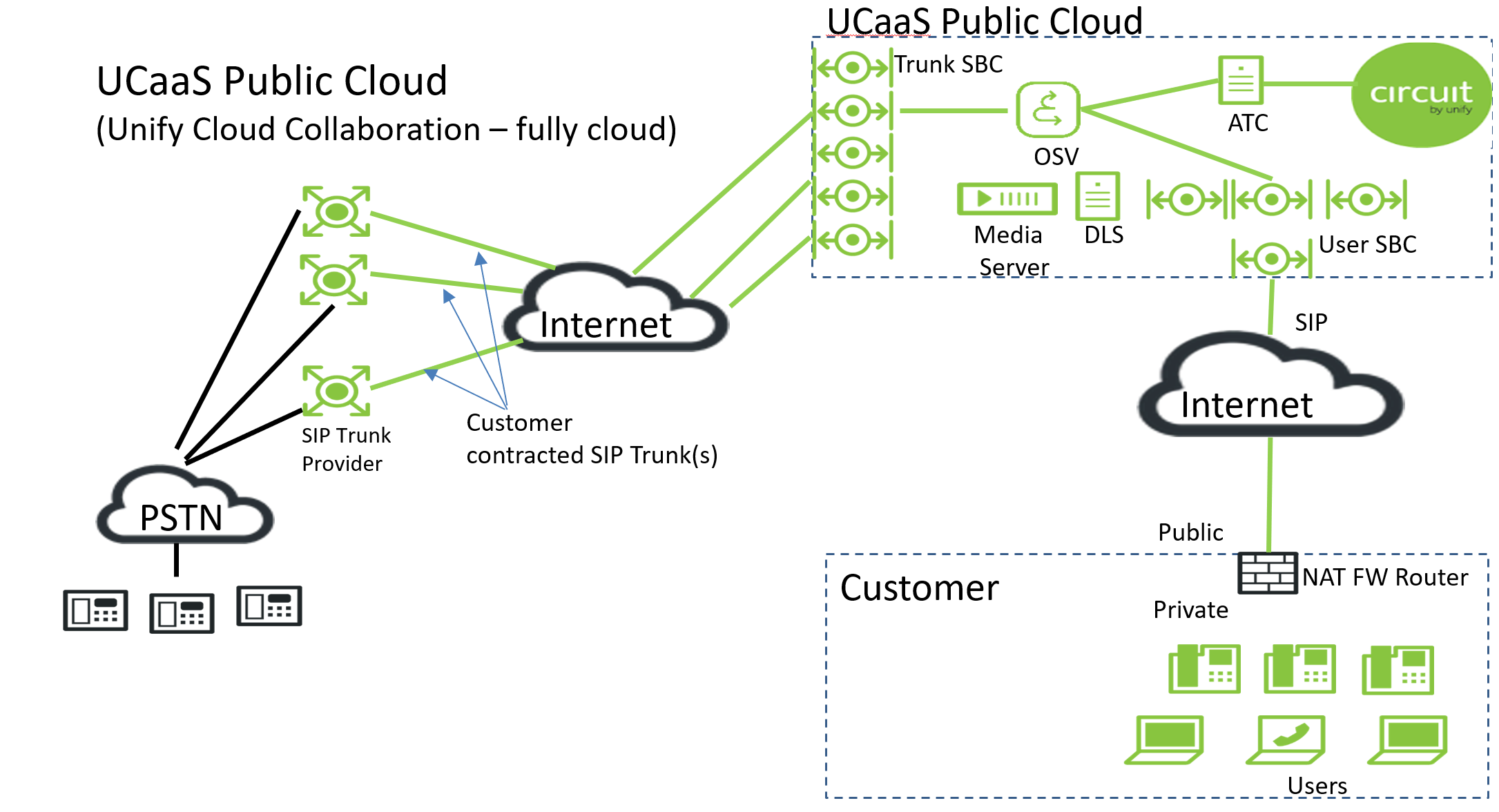
Abbildung 2: Unify UCaaS Portfolio
Um diese Bereiche ebenfalls in Zukunft abdecken zu können, plant Unify eine Kooperation mit Google’s G-Suite. Die Zusammenarbeit wird durch den Umstand erleichtert, dass die genutzte Cloud-Infrastruktur ebenfalls durch Google bereitgestellt wird.
Diese Neu-Ausrichtung ist jedoch zunächst einmal strategisch zu sehen. Noch ist der deutsche TK-Markt nicht so weit, dass er mit fliegenden Fahnen in das Cloud-Lager hinüberwechselt. Es sind, Stand heute, eher kleinere bis mittelständische Unternehmen, die mit der Einführung solcher Dienste liebäugeln und das aus gutem Grund. Oftmals stellt die Anschaffung einer neuen UC-Plattform mit ihren erweiterten Möglichkeiten die Betriebsmannschaft vor zusätzliche Herausforderungen, die sie nicht abdecken können.
Oder aber es zeichnet sich bei der Geschäftsführung ein Umdenken ab, weg von einer CAPEX-lastigen hin zu einer OPEX-basierten IT.
Dazu kommt von Seiten der Cloud-Anbieter die Zusage, nie mehr auf einem veralteten System arbeiten zu müssen, denn Cloud Service bedeutet auch permanente Teilhabe an Neuerungen beim Produkt. Allein seit der Einführung von Unify Circuit wurden weit über 120 sogenannte Sprints, also kleinere und auch größere Updates, den Kunden automatisch zur Verfügung gestellt und somit auch laufend neue Funktionen angeboten.
Bei größeren Unternehmen stehen dagegen oft ganz andere Faktoren einer Cloud-Strategie im Wege.
Dort geht es oft um Fragen der Datensicherheit, und damit ist nicht nur die Verschlüsselung von Sprache gemeint. Gerade beim Einsatz von Kollaborations-Lösungen fallen bedeutend umfangreichere Betrachtungen bezüglich der Sicherheit an. Angefangen von:
• einer zentralen Benutzerauthentifizierung auf Zertifikats-Basis,
• Mobile Device Management,
• Data Loss Prevention & Dokumenten-Management
• bis hin zur Einhaltung der DSGVO Regeln.
Dies in einem Kontext mit mehreren tausend Mitarbeitern, und vielleicht Millionen von Kundendaten, ist eine nicht zu unterschätzende Herausforderung und Bedarf einer längerfristigen Planung.
Bleibt zuletzt aber doch noch die Frage:
• Und was ist, wenn ich in der Zukunft die Cloud nicht nutzen darf oder nicht nutzen möchte?
Was mache ich, wenn die Anbieter ihr Heil in der Cloud suchen? Welche Möglichkeiten bleiben mir noch?
Auch hier gilt es, die Situation nüchtern zu betrachten. Dass „Kommunikation“ mittelfristig nur noch aus der Cloud zu beziehen sein wird, ist unrealistisch.
Kein bekannter Marktteilnehmer, weder Avaya noch Unify noch andere, plant, eigene OnPrem-Produkte in den kommenden zehn Jahren vom Markt zu nehmen. Dies sollte alle beruhigen, die eine Cloud-Lösung aktuell aus rechtlichen oder organisatorischen Gründen nicht berücksichtigen können.
Jedoch sollte man nicht darauf hoffen, dass sich bei diesen Produkten noch größere Technologie-Sprünge ergeben werden. Die eingesetzten Finanzmittel für F&E gehen zu 90% in die Entwicklung der Cloud-Lösungen. Das Produkt Telefonanlage ist am Ende seiner Entwicklung angekommen.
Trotz alledem wird es weiterhin lokale Lösungen geben. Gerade kleinere Marktteilnehmer, deren Situation es aktuell nicht ermöglicht, eine Cloud-Offensive zu starten, werden dafür sorgen, dass der Markt weiterhin bedient wird.
Anbieter wie Innovaphone sehen dies sogar als Chance, sich im Markt neu zu positionieren, indem sie ihren Cloud-kritischen Kunden versichern, weiterhin an lokalen Lösungen zu arbeiten und diese durch Private-Cloud-Dienste aufzuwerten.
So verweist man gerne auf die Möglichkeit, Dienste, wie sie Office 365 bietet, auch mit lokalen Infrastrukturen zu ermöglichen. Eine Kombination aus lokalem VoIP Service, einer gemeinsamen Dokumentenablage und Groupware mittels Own- oder NextCloud und die Nutzung von Collabora Online Office ermöglicht ähnliche Ergebnisse wie Microsoft-Produkte.
Natürlich ergeben sich in dieser Kombination auch Nachteile gegenüber den großen Anbietern wie Google oder Microsoft. Gerade die Verknüpfung von Themen wie Big Data und künstlicher Intelligenz lassen sich mit lokalen Installationen schlecht abbilden, aber vielleicht ist das auch nicht das Ziel dieses Weges. Jedenfalls verspricht eine OnPrem-Lösung ein höheres Maß an Unabhängigkeit.
Denn eins ist gewiss: Begeben Sie sich erstmal in die Cloud, gibt es nur sehr schwer einen Weg zurück.
Aufgrund dieser vielen aktuellen Veränderungen im Markt werden wir auf unserem diesjährigen ComConsult UC-Forum die möglichen Entwicklungen und Alternativen mit Ihnen intensiv diskutieren und auch die strategische Ausrichtung der Hersteller genau unter die Lupe nehmen. Wir würden uns daher sehr freuen, Sie im November im Maritim Hotel Königswinter begrüßen zu können.
Warum jede Organisation einen CTO braucht
Fortsetzung
An keinem Bereich des Lebens geht der technologische Wandel spurlos vorbei. Arbeiten und Abläufe, die Jahrtausende lang kaum Änderungen unterlagen, werden durch die Digitalisierung verändert. Internet of Things bedeutet wirklich die digitale Erfassung aller Dinge. Sind wir darauf vorbereitet? Die Antwort darauf ist ein klares Nein. Diese Aussage basiert auf Erfahrungen aus den letzten drei Jahrzehnten, in denen wir fast alle Branchen und Typen von Organisation beratend begleitet haben. Immer wurden viele Organisationen vom technologischen Wandel überrascht. Sie haben auf große Trends im Markt erst mit Verzug reagiert. Bleibt es auch in Zukunft so, werden viele Unternehmen den technologischen Wandel nicht überleben. Eine Organisation, die diesem Schicksal entgehen will, braucht einen Mechanismus für die Früherkennung der sie betreffenden Technologietrends. Dieser Mechanismus muss ein dauerhafter sein. An einem Chief Technology Officer (CTO) und der dazu gehörigen Organisationsstruktur geht kein Weg vorbei.
Bisher haben sich viele Organisationen damit begnügt, hin und wieder Reden und Schriften sogenannter Gurus Aufmerksamkeit zu schenken. Prognosen aus dem Munde oder der Feder dieser Propheten sind beliebt. Allein der Umstand, dass es jemand im Glücksspiel der Wirtschaft zum Milliardär schaffte, reicht aus, um ihm teure Vortragshonorare zu sichern.
Dabei lagen die berühmtesten Technik-Propheten weit häufiger daneben als richtig. Ein kleiner Ausschnitt aus der Reihe falscher Prophezeiungen:
- „Wir werden nie ein 32-Bit-Betriebssystem bauen.“ (Bill Gates, Mitbegründer von Microsoft, 1989)
- „Wireless Computing wird ein Flop sein – dauerhaft.“ (Bob Metcalfe, Mitbegründer von 3Com, auch bekannt als „Vater des Ethernet“, 1993)
- „Es gibt keine Chance, dass das iPhone einen signifikanten Marktanteil bekommen wird.“ (Steve Ballmer, damaliger Microsoft-Chef, 2007)
- „Ich würde Apple zumachen und das Geld den Anteilseignern zurückgeben.“ (Michael Dell, Inhaber der gleichnamigen Firma, 1997)
- „In zwei Jahren wird Spam der Vergangenheit angehören.“ (Bill Gates, 2004)
- „Die Amerikaner brauchen das Telefon, wir nicht. Wir haben jede Menge Boten.“ (Sir William Preece, Chefingenieur des königlichen britischen Postamts, 1878)
- „Dieses sogenannte ‚Telefon‘ hat zu viele Nachteile, um als ein ernstzunehmendes Mittel zur Kommunikation zu gelten. Dieses Gerät ist an sich für uns wertlos.“ (interne Note der US-Telegrafengesellschaft Western Union, 1876)
- „Bevor der Mensch den Mond erreicht, wird Ihre Post binnen Stunden mittels gelenkter Raketen von New York bis Australien transportiert werden. Wir stehen an der Schwelle zur Raketenpost.“ (Arthur Summerfield, Chef der US-Post, 1959)
- „Herumbasteln an Wechselstrom ist nur Zeitverschwendung. Niemand wird sie nutzen, niemals.“ (Thomas Edison, 1889)
Nachher ist man immer schlauer. Es wäre unfair, diesen Propheten mit Hohngelächter zu begegnen, wenn sie – oft lange nach dem Zenit ihres Erfolgs – nicht ein Geschäft daraus gemacht hätten, ihre Prognosen an den Mann zu bringen. Gesunde Skepsis gegenüber Kristallkugeln hat aber nie geschadet.
Der Job des CTO ist aber keine Konsultation der Glaskugel. Mehr als auf Prognosen sollte sich die CTO-Organisation auf bereits vorhandene Markt- und Technologieentwicklungen achten. Nicht Science Fiction, sondern aufmerksame Markt- und Technikbeobachtung ist gefragt.
Technologische Entwicklungen kommen äußerst selten wie der Blitz aus heiterem Himmel. Sie geben uns fast immer Monate, wenn nicht sogar ein, zwei Jahre Zeit, um sie zu erkennen. Schauen wir uns einige der wichtigsten Entwicklungen der letzten Jahrzehnte an:
- Dem Siegeszug des Personal Computer (PC) war in den 1980er Jahren einiger Hersteller von Heim-Rechnern wie Commodore und Atari vorausgegangen.
- Das iPhone hatte im iPod einen Vorgänger, der jahrelang millionenfach verkauft wurde und Apple erst die Möglichkeit gab, das bisher beliebteste mobile Gerät zu entwickeln. Und das zu einer Zeit, in der einige Pioniere des Mobiltelefons keine richtige Lust verspürten, mehr aus ihrem technologischen Vorsprung zu machen.
- Google war nicht die erste Internet-Suchmaschine. Jahre vor der Gründung von Google gab es schon die Suchmaschinen von Alta Vista and Yahoo.
- Packet Voice gehörte schon zu den ersten Anwendungen im Arpanet, dem Vorgänger des Internet. Vierzig Jahre später nennen wir es Voice over IP.
Wir hätten keine Propheten gebraucht, um die Bedeutung dieser Entwicklungen zu sehen. Sie waren vor unseren Augen. Und viele haben das gesehen. In den 1980er Jahren entwickelte ein Freund von mir auf der Basis von Commodore 64 ein sehr brauchbares Textverarbeitungssystem, das ich jahrelang genutzt habe. Lange wurde in der Branche darüber spekuliert, ob Apple in das Mobiltelefongeschäft einsteige, bevor dies Realität wurde. Ich habe die Suchmaschinen vor Google jahrelang genutzt, trotz ihrer Unzulänglichkeit. Und auf VoIP hat ComConsult bereits in den 1990er Jahren gesetzt, weil nicht viel Weitsicht dazu gehörte zu erkennen, dass diese Technologie die Zukunft der Kommunikation bestimmen würde. Wir waren keine Propheten. Wir hatten nur dank unserem Geschäftsmodell die Chance, am Puls der Zeit zu sein.
Nicht nur der technologische, sondern auch der demografische Wandel ist heute allzu sichtbar. Früher, bei einer Lebenserwartung von 70 Jahren, haben Menschen zwischen 20 und 65 in die Rentenkassen gezahlt, damit sie in den letzten 5 bis 10 Jahren ihres Lebens nicht arbeiten mussten, um in Würde zu leben. Jetzt steuern wir auf eine Lebenserwartung von 85 und mehr zu. Zugleich werden Ausbildungszeiten länger. Nicht selten fängt das aktive Berufsleben erst mit 30 an. Bei dem immer schneller werdenden technologischen Wandel ist es eine Illusion zu glauben, dass wir mit 30 „ausgelernt“ haben und nur 35 Jahre arbeiten müssen, um danach mindestens 20 Jahre ausreichende Renten und Pensionen zu beziehen. Das Berufsleben ist bereits heute von Fort- und Weiterbildung geprägt.
Warum soll es Organisationen, also Unternehmen und Verwaltungen, anders ergehen als ihren Beschäftigten? Auch Organisationen müssen ständig dazu lernen. Und den Rahmen dafür zu schaffen, das ist genau das Tätigkeitsprofil des CTO.
Das schreibe ich nicht als Außenstehender. Diese Funktion habe ich jahrzehntelang für das Unternehmen ausgeübt, dem ich angehöre. Ich behaupte, dass wir nun ein Stadium des technologischen Wandels erreicht haben, in dem kein Unternehmen ohne die Organisation des ständigen Dazulernens auskommt.
Wie ist dieses ständige Lernen möglich? Vor allem ist es Arbeit. Man muss mit der Unternehmensstrategie beginnen und sich darüber Gedanken machen, was die Umsetzung dieser Strategie behindert und wie diese Umsetzung bereits mit den heute verfügbaren technologischen Mitteln erleichtert werden kann. Die Unternehmensstrategie gibt vor, in welchen Geschäftsgebieten und welchen Märkten das Unternehmen tätig sein will. Der CTO macht sich vor allem mit den aktuellen Marktentwicklungen vertraut, die für die Geschäftsfelder des eigenen Unternehmens relevant sind oder werden können.
Angesichts des schnellen technologischen Wandels ist diese Marktbeobachtung keine einmalige Angelegenheit, sondern ein ständiger Prozess. Von Vorteil ist, dass wir mit den heute verfügbaren Mitteln der Kommunikation sehr schnell von den Erfolgen und Misserfolgen anderer erfahren. Der CTO ist mit den Abläufen und Kostenstrukturen des eigenen Unternehmens vertraut. Er weiß zum Beispiel, wie viel das Unternehmen an Geld und Arbeitszeit in Reisen investiert. Und er kann genauer hinschauen um zu erkennen, wie viel Einsparung bereits heute erzielt werden kann, wenn ein Teil der Präsenzmeetings durch Telefon-, Video- und Webkonferenzen ersetzt werden können. Er kann herausbekommen, wie schnell in der eigenen Organisation die Zusammenarbeit über Unternehmensgrenzen hinaus wächst. Damit kann er analysieren, welchen Nutzen eine offene Plattform der Kommunikation im Vergleich zu einer rein unternehmensinternen bringt. Der CTO weiß, ob das eigene Unternehmen ein neues Gebäude plant. Er kann untersuchen, welche Technologien in modernen Geschäftsgebäuden sich bewährt haben. Der CTO schaut sich die Art und Weise an, wie das eigene Unternehmen seine Kunden anspricht und mit ihnen in Kontakt bleibt. Er kann von den Erfolgen anderer lernen, was Kundenpflege (auf Neuhochdeutsch: Customer Relationship Management, CRM) betrifft. Der CTO weiß, wie das eigene Unternehmen produziert, Rohstoffe bezieht und die Logistik betreibt. Er kann diese Abläufe darauf abklopfen, ob sie mit neuen, aber bewährten technologischen Entwicklungen Schritt halten.
Dass technologische Entwicklung in unserer Zeit vor allen Digitalisierung ist, leuchtet ein. Und hier gibt es eine bemerkenswerte Entwicklung: Die Informationstechnik (IT) im Unternehmen wird zum gefragten Berater, wenn das Unternehmen die Zeichen der Zeit verstanden hat. Die IT muss aus ihrem Dasein als reiner Kostenverursacher ausbrechen. IT-Experten kennen sich mit der Digitalisierung aus, weil sie qua Aufgaben sich schon immer damit befassen mussten. Die CTO-Organisation braucht die eigenen IT-Experten. Diese erwartet ein wichtiger neuer Aufgabenbereich, für die sie prädestiniert sind. Sie wissen, wie Digitalisierung geht. Und sie kennen ihr eigenes Unternehmen. Solche Mitarbeiter kann man nicht „fertig“ aus dem Markt rekrutieren. Sie sind von großer Bedeutung, von großem Wert für ihren Arbeitgeber. Und dieser muss ihren Wert erhalten, indem er die Freiräume schafft, die für eine Markt- und Technologiebeobachtung nötig sind.
Wir bei ComConsult setzen darauf, dass diese Erkenntnisse in immer mehr Organisationen durchdringen. Für diese Unternehmen und Verwaltungen haben wir in diesem Jahr unsere Technologietage konzipiert, die am 1. und 2. Oktober in Aachen stattfinden. Um ein möglichst vollständiges Bild von den Themen zu präsentieren, die unsere Kunden beschäftigen, haben wir ca. 20 ComConsult-Berater darum gebeten, aus ihrer Projektpraxis zu berichten. Von Smart Building zu Security, von Netzen zu Kommunikationslösungen, von Rechenzentren bis Cloud Computing sind alle wesentlichen Technologien auf der Agenda der Veranstaltung. Wir freuen uns, Sie im innovativen Umfeld des Enterprise Integration Center Aachen zu begrüßen, umgeben von Deutschlands führenden innovativen Firmen. Eine Besichtigung des Demozentrums „Smart Commercial Building“ an der RWTH Aachen im Cluster Smart Logistik rundet das Programm ab. Hier wird zwei Jahre vor Fertigstellung eines Gebäudes die Präqualifikation von Produkten und Systemen in Bezug auf Funktionalität, Cyber-Security und die Inbetriebnahme durchgeführt. Ein passenderes Ambiente für die Technologie-Tage kann es nicht geben.
Ihr Dr. Behrooz Moayeri

Die Personalabteilung als Schmelztiegel von Informationssicherheit und Datenschutz
Fortsetzung
In meinen Projekten bei Kunden stelle ich immer wieder fest, dass die Personalabteilung der jeweiligen Institution einen höchst interessanten Schmelztiegel sowohl für die Informationssicherheit als auch für den Datenschutz darstellt. Einerseits werden in der Personalabteilung höchst schützenswerte personenbezogene Daten verarbeitet. Andererseits müssen die Mitarbeiter mit vergleichbar hohen Freiheiten Internet-Dienste nutzen dürfen, um ihre Arbeit zu verrichten. Dies beinhaltet beispielsweise, dass E-Mails mit Anhängen, die von zunächst Unbekannten (Bewerbern) stammen, geöffnet werden müssen. Außerdem ist eine intensive Präsenz in Sozialen Netzen notwendig, um sich für Bewerber attraktiv zu machen, Kontakte zu pflegen und geeignete Kandidaten zu finden. Die Policies auf einer Firewall, einem Secure Web Gateway oder einem Secure E-Mail Gateway müssen für die Mitarbeiter der Personalabteilung entsprechend freigiebig sein, damit sie ihre Arbeit verrichten können.
Das ist natürlich ein idealer Einstiegspunkt für Schadsoftware, Ransomware und zielgerichtete Angriffe (Advanced Persistent Threats, APTs). Ein schönes Beispiel ist hier der Kryptotrojaner Goldeneye, der Ende 2016 zielgerichtet Personalabteilungen mit einer professionell gestalteten Bewerbungs-E-Mail angegriffen hat [1]. Dabei handelte es sich um eine Excel-Datei im E-Mail-Anhang mit einem bösartigen Makro, also eine eigentlich alte Angriffsmethode, die bis heute immer wieder wunderbar funktioniert. Es ist auch kein Wunder, dass die momentan grassierende besonders gefährliche Ransomware Emotet es unter anderem auch auf Personalabteilungen abgesehen hat. Emotet macht deutlich, dass für die Verbreitung von Schadsoftware immer mehr professionelle Techniken, die man in der Vergangenheit nur von APTs kannte, verwendet werden [2]. Zu nennen sind hier beispielsweise professionelle, praktisch nicht zu erkennende Phishing-Mails, Zugriff auf Outlook-Kontakte, systematische Analyse der Netzwerkumgebung in Verbindung mit dynamischem und mehrstufigem Nachladen von Schadcode.
Da ein konventioneller Virenschutz hier oft überfordert ist, muss mit zusätzlichen Instrumenten gearbeitet werden. Dabei ist insbesondere das Sandboxing für E-Mails und sonstige Internet-Zugriffe eigentlich ein Muss. Wenn dann doch eine Infektion stattgefunden hat, hilft nur noch das hoffentlich effektive Instrumentarium zur Erkennung und Behandlung von Sicherheitsvorfällen als Bestandteil der operativen Informationssicherheit [3].
Neben dem Risiko, dass sich für eine Personalabteilung durch die Attraktivität als Angriffsziel und die Exponiertheit dem Internet gegenüber ergibt, sind noch andere Aspekte für die Informationssicherheit und den Datenschutz interessant, denn gerade im Personalbereich gibt es immer wieder kreative und innovative IT-Nutzungen. Kaum wurden beispielsweise Cloud-Dienste für die allgemeine IT langsam immer populärer, gab es schon längst Reisekostenmanagement, Zeiterfassung zur Arbeitszeiterfassung, Projektzeiterfassung, Urlaubsverwaltung und Personaleinsatzplanung als Software as a Service (SaaS) aus Public Clouds. Teilweise hatte dies auch zur Folge, dass Personalabteilungen solche Dienste unabhängig von der IT der Institution eingekauft und genutzt haben (es wurde ja schließlich keinerlei eigen betriebene IT mit Ausnahme des Browsers verwendet). Damit ist ein erster Schritt in Richtung einer Schatten-IT getan, der deswegen besonders kritisch ist, weil Beschaffung und Nutzung dieser Cloud-Dienste dann ggf. nicht konform zu Richtlinien erfolgt und insbesondere keine Schnittstellen zu wichtigen Prozessen, wie z.B. dem (Security) Incident Management und dem Schwachstellen-Management, bestehen.
Ein höchst interessanter aktueller Trend ist in Personalabteilungen die Unterstützung bei der Bewertung von Bewerbungen durch eine oder mehrere Künstliche Intelligenzen (KIs) zur
- automatisierten Analyse von Bewerbungsunterlagen (z.B. direkt beim Eingang einer entsprechenden E-Mail oder als Agent / Bot in Sozialen Netzen),
- Entlastung der menschlichen Mitarbeiter durch Chat Bots für Bewerbungsgespräche und Analyse der Gespräche sowie zur
- Online-Video-Analyse bzw. Analyse von Videoaufzeichnungen von Bewerbungsgesprächen.
Dabei ist oft die psychologische Einschätzung der Persönlichkeitsmerkmale im Fokus der KI. Es gibt hierzu sogar bewährte Methoden, um Persönlichkeitsmerkmale zu kategorisieren und zu quantifizieren (quasi Key Performance Indicators, KPIs, der Persönlichkeit), die sogenannten Big Five, auch als Fünf-Faktoren-Modell (FFM) oder OCEAN-Modell bezeichnet [4]:
- Openness / Offenheit für Erfahrungen (Aufgeschlossenheit)
- Conscientiousness / Gewissenhaftigkeit (Perfektionismus)
- Extraversion (Geselligkeit)
- Agreeableness / Verträglichkeit (Rücksichtnahme, Kooperationsbereitschaft, Empathie)
- Neuroticism / Neurotizismus (emotionale Labilität und Verletzlichkeit)
Die Big Five sind inzwischen durch viele Studien belegt und international als das universelle Standardmodell in der Persönlichkeitsforschung anerkannt. Diese Modelle und Methoden sind dabei prädestiniert für KI und können hier durch andere Komponenten (Betonung, Gestik, Mimik, …) leicht erweitert werden. Die Idee ist natürlich naheliegend: Eine KI filtert aus eingehenden Bewerbungen die besten Kandidaten heraus, die sich dann die Personalabteilung genauer anschaut. Vielleicht kann künftig sogar der komplette Rekrutierungsprozess per KI automatisiert werden (was vielleicht den Mitarbeitern der Personalabteilung weniger gefällt). Kein Wunder, dass es inzwischen mehrere Hersteller auf dem Markt gibt, deren Produkte auch in Deutschland eingesetzt werden [5]. Im Juni 2019 wurde zu diesem Themenbereich auch eine sehr interessante Studie unter dem Titel „Der maschinelle Weg zum passenden Personal – Zur Rolle algorithmischer Systeme in der Personalauswahl“ von der Bertelsmann Stiftung herausgegeben [6].
Die Gefahren, die sich für die Informationssicherheit und insbesondere für den Datenschutz ergeben, gehen hier über die klassischen Sicherheitsziele Vertraulichkeit, Integrität und Verfügbarkeit der Daten deutlich hinaus. Es besteht beispielsweise die Gefahr, dass eine selbstlernende KI Bewerber unbeabsichtigt systematisch diskriminiert. Dies ist tatsächlich schon vorgekommen, wie Amazon eindrucksvoll im Oktober 2018 bewiesen hat [7]. Amazon hatte für sich selbst eine KI für die Rekrutierung von Bewerbern geschrieben und diese KI mit den Daten von erfolgreichen Bewerbern der Vergangenheit angelernt. Es ist klar was passieren musste: In der IT haben wir nun einmal leider viel zu viele männliche Bewerber und dann auch einen gewissen Überhang erfolgreicher männlicher Bewerber. Die KI hat nun dank der Anlerndaten folgerichtig gelernt, dass es ein positives Merkmal ist, männlich zu sein und hat nach Eigenschaften gesucht, die insbesondere eine Bewerberin klassifizieren und diese dann mit einem geringeren Ranking versehen. Das war natürlich ein GAU.
Interessanterweise hat die Datenschutz-Grundverordnung (DSGVO) mit dem Artikel 35 [8] auch ein entsprechendes Instrument für solche Arten der Verarbeitung personenbezogener Daten geschaffen: die Datenschutz-Folgenabschätzung (DSFA). Mit der DSFA werden nun genau die Methoden des Risikomanagements im Datenschutz verankert, die schon seit geraumer Zeit in der Informationssicherheit mehr als bewährt sind (siehe speziell ISO 27001 und BSI IT-Grundschutz). Eine DSFA ist immer dann erforderlich, wenn durch die Verarbeitung ein hohes Risiko für die Rechte und Freiheiten natürlicher Personen entstehen kann. Eine DSFA ist nebenbei zwingend durchzuführen, wenn Art. 35 DSGVO in Absatz 3 greift, speziell „systematische und umfassende Bewertung persönlicher Aspekte natürlicher Personen, die sich auf automatisierte Verarbeitung einschließlich Profiling gründet“. Das passt verdächtig zum Einsatz von KI in der Rekrutierung von Personal. Nur haben wir hier ein spannendes Problem: Eine selbstlernende KI ist hier typischerweise eine Black-Box-KI auf Basis Neuronaler Netze, d.h. es ist oft auch für den Entwickler kaum noch zu beurteilen, in welche Richtung sich die KI je nach individuellem Einsatz tatsächlich entwickelt. Wie soll da eine noch klare Risikoeinschätzung möglich sein?
In Summe bedeutet diese Betrachtung, dass wir mehr zielgruppengerechte Sicherheits- und Datenschutzkonzepte benötigen. Ein und dieselbe Anwendung kann für unterschiedliche Nutzergruppen sehr unterschiedliche Sicherheitsmaßnahmen erfordern. Wir haben uns meiner Meinung nach in der Informationssicherheit in der Vergangenheit viel zu stark auf standardisierte (und standardisierbare) IT konzentriert. Cloud und insbesondere KI erfordern aber, dass wir uns viel stärker auf die Belange der eigentlichen IT-Nutzergruppen konzentrieren müssen.
Verweise
[1] Siehe z.B. https://www.projekt29.de/goldeneye-angriff-auf-die-personalabteilung/
[2] Siehe z.B. https://www.dfn-cert.de/aktuell/emotet-beschreibung.html und https://www.heise.de/ct/artikel/Trojaner-Befall-Emotet-bei-Heise-4437807.html
[3] Siehe „SecOps: Operative Informationssicherheit“ in Der Netzwerk Insider vom Juni 2019
[4] Siehe z.B. https://de.wikipedia.org/wiki/Big_Five_(Psychologie)
[5] Siehe z.B. https://www.deutschlandfunk.de/bewerbungsgespraech-kuenstliche-intelligenz-nimmt.676.de.html?dram:article_id=446234 und
https://www.focus.de/finanzen/karriere/bewerbung/wirtschaft-mein-bewerbungsgespraech-mit-einem-roboter_id_9547536.html
[6] Siehe https://www.bertelsmann-stiftung.de/de/publikationen/publikation/did/der-maschinelle-weg-zum-passenden-personal/
[7] Siehe https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G
[8] Siehe https://dsgvo-gesetz.de/art-35-dsgvo/

Kontakt
ComConsult GmbH
Burtscheider Markt 24
52066 Aachen
Telefon: 0241/887446-0
Fax: 0241/887446-200
E-Mail: info@comconsult.com
![]()