
aus dem Netzwerk Insider Juli 2023
Daten, Daten, Daten, …
Im stetigen Strudel des Informationszeitalters ist es oft schwer, den Überblick zu behalten. Ein Meer von Daten umgibt uns, immer in Bewegung, immer in Fluss. Doch was, wenn wir diese Flut kontrollieren könnten? Was, wenn wir aus den Tiefen dieses Ozeans von Informationen kostbare Perlen der Erkenntnis heben könnten? Ein Mann hatte früh genau diese Vision – und sein Name war John Naisbitt.
Naisbitt, ein US-amerikanischer Autor mit dem Themenschwerpunkt Trend- und Zukunftsforschung, war berühmt für seine klaren Einblicke in die Zukunft und erkannte als einer der ersten die wachsende Bedeutung der Daten bereits in den 1980er Jahren. In seinem Buch „Megatrends“ zeigte er auf, dass wir in ein Zeitalter der Informationsflut eintreten, das er als „Informationszeitalter“ bezeichnete. Doch weit über das einfache Erkennen dieses Trends hinaus verstand Naisbitt auch die immensen Möglichkeiten, die sich aus dieser Flut von Daten ergeben.
So verbergen sich in den Daten oft unentdeckte Zusammenhänge. Häufig ist es nur die riesige Menge von Zahlen oder Texten, die uns Menschen daran hindert, diese Zusammenhänge aus solchen Daten „rauszufischen“. Genau dabei kann uns der Computer helfen. Willkommen zu Data Science!
Daten in Netzwerken
In Netzwerken fallen ebenfalls viele verschiedene Arten von Daten an, die für die Analyse mit Data-Science-Techniken infrage kommen. Einige davon sind:
- Netzwerkverkehrs-Daten: Diese Daten enthalten Informationen über die Menge des Datenverkehrs, die Quelle, das Ziel, den Zeitstempel, die Art des Verkehrs (z.B. HTTP, HTTPS, SMTP) und andere Merkmale des Netzwerkverkehrs.
- Log-Daten: Netzwerkgeräte wie Router, Switches und Server erzeugen laufend Log-Daten, die wertvolle Informationen über das Netzwerkverhalten liefern können. Sie können Aufschluss über die Effizienz des Netzwerks, potenzielle Sicherheitsprobleme und andere nützliche Informationen geben.
- Sicherheitsdaten: Dazu gehören Daten über potenzielle Angriffe, Schwachstellen, Viren, und sonstige sicherheitsrelevante Ereignisse im Netzwerk. Sie helfen dabei, Netzwerksicherheitslösungen zu entwickeln und zu verbessern.
- Nutzungsdaten: Diese Daten zeigen, wie Benutzer das Netzwerk nutzen, z.B. welche Anwendungen sie verwenden, zu welchen Zeiten sie am aktivsten sind, und andere Benutzerverhaltensmuster.
- Performance-Daten: Diese Daten geben Aufschluss über die Leistungsfähigkeit des Netzwerks, wie z.B. Latenzzeiten, Bandbreite, Paketverlust-Raten und andere messbare Eigenschaften.
- Strukturdaten des Netzwerks: Diese beinhalten Informationen über die physische und logische Struktur des Netzwerks, einschließlich der Anzahl und Art der Geräte, ihrer Verbindungen, Protokolle usw.
All diese Daten können mit Data-Science-Methoden analysiert werden, um Muster zu erkennen, Vorhersagen zu treffen, Anomalien zu identifizieren oder um die Effizienz und Sicherheit des Netzwerks zu verbessern. Die Möglichkeiten sind so vielfältig wie die Daten selbst.
Der Data-Science-Prozess
Es stellt sich die Frage, ob es so etwas wie einen roten Faden bei dem Bergen von Erkenntnissen vom Grund eines solchen Datenmeers gibt. Zwar hat jedes Data-Science-Projekt seinen individuellen Charakter, doch die meisten Data Scientists sind sich dahingehend einig, dass es typische wiederkehrende Phasen in solch einem Projekt gibt. Genau diese Phasen versucht das sehr beliebte Prozessmodell CRISP-DM (Cross Industry Standard Process for Data Mining) festzuhalten. Übrigens finden wir hier in der Abkürzung nicht den Begriff „Data Science“, sondern „Data Mining“. Um es kurz zu machen: Das meint das Gleiche.
Dieses weitverbreitete Prozessmodell identifiziert sechs Phasen bei einem Data-Science- Projekt:
- Geschäftsverständnis (Business Understanding): Dies ist die anfängliche Phase, in der das Ziel des Projekts definiert wird, basierend auf den geschäftlichen Anforderungen. Hier werden die Ziele und Erfolgskriterien festgelegt und ein Projektplan erstellt.
- Datenverständnis (Data Understanding): In dieser Phase wird die vorhandene Datenlandschaft untersucht. Dazu gehören das Sammeln von Daten, die Überprüfung ihrer Qualität und das erste Kennenlernen durch einfache Analysen oder das Erstellen von Visualisierungen.
- Datenvorbereitung (Data Preparation): Hier werden die Daten für die Modellierung aufbereitet. Das kann das Reinigen von Daten, das Auswählen geeigneter Daten, die Transformation von Daten (zum Beispiel die Normierung) oder das Erzeugen neuer Daten (Feature Engineering) umfassen.
- Modellierung (Modeling): In dieser Phase werden verschiedene Modellierungstechniken angewendet und ihre Parameter kalibriert, um den bestmöglichen Ansatz zu finden. Dies könnte die Anwendung von maschinellem Lernen, statistischen Modellen oder anderen Data-Mining-Techniken beinhalten.
- Bewertung (Evaluation): Hier werden das Modell oder die Modelle bewertet, um zu bestimmen, ob die Geschäftsziele erreicht wurden. Dies könnte die Berechnung von Leistungskennzahlen oder die Überprüfung der Resultate auf deren Sinnhaftigkeit umfassen.
- Bereitstellung (Deployment): In der abschließenden Phase wird das Modell den Anwendern für den Arbeitsalltag zur Verfügung gestellt.
CRISP-DM läuft dabei nicht unbedingt linear ab. Es ist mehr ein iterativer Prozess, bei dem man oft mehrere Schritte zurückgeht, um die Daten oder das Modell basierend auf neuen Erkenntnissen anzupassen.
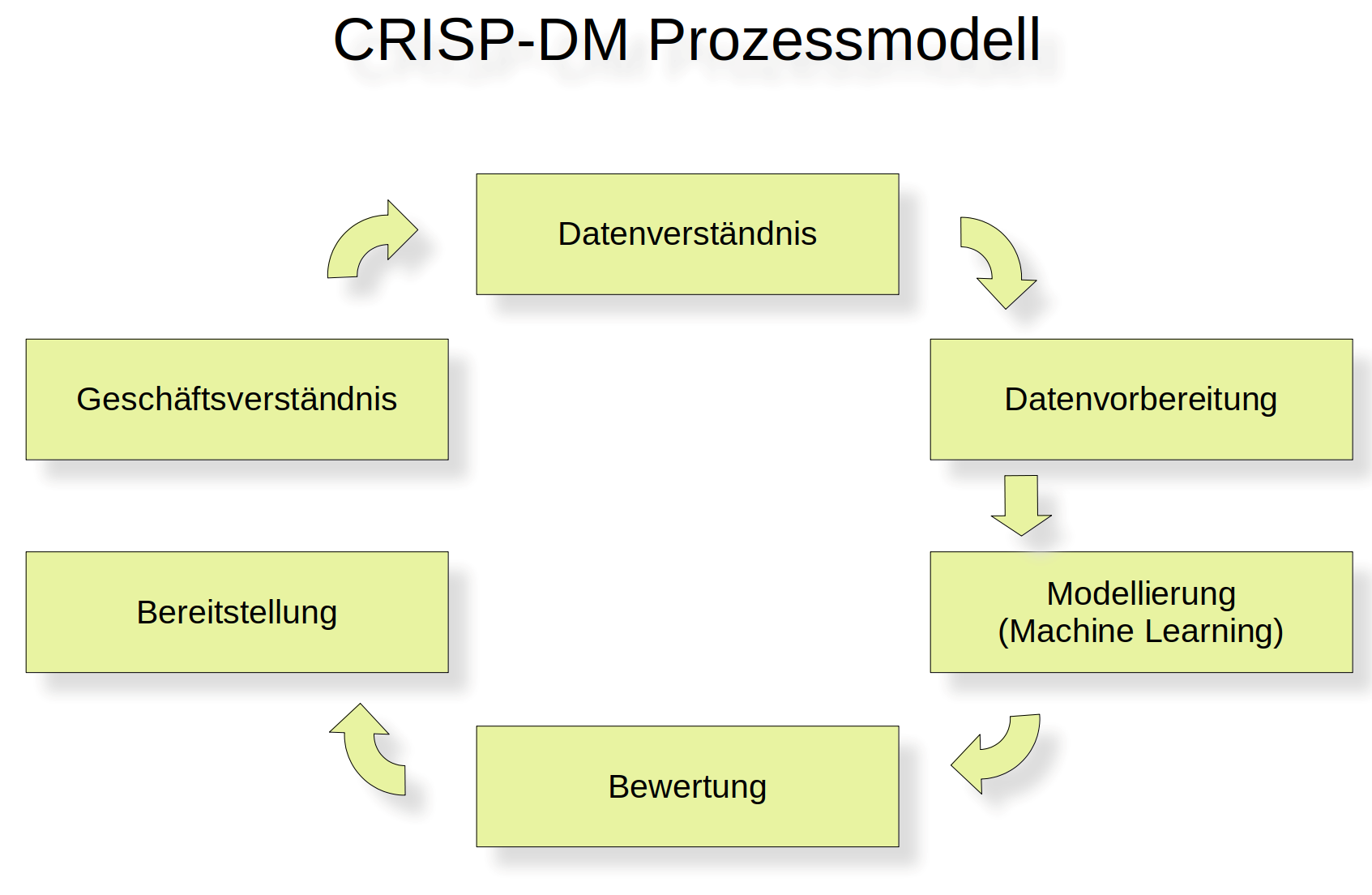
Abbildung 1: Das CRISP-DM-Prozessmodell
Theorie trifft Praxis
Solche Darstellungen sind oft allerdings ein wenig zu idealistisch. In der Praxis trifft man bei jedem Schritt des CRISP-DM-Prozesses nämlich meist auf vielfältige Herausforderungen.
- Geschäftsverständnis: In der Praxis existiert hier häufig eine Diskrepanz zwischen den geschäftlichen Erwartungen und den tatsächlichen technischen Möglichkeiten. Eine Herausforderung liegt darin, realistische Ziele zu setzen und sicherzustellen, dass alle Beteiligten eine klare Vorstellung von dem haben, was durch Data Science erreicht werden kann und was nicht. Gerade durch den „Hype“ von Data Science wurde viel Erde verbrannt. Unrealistische Erwartungen an die Möglichkeiten von Data Science führten in vorangegangenen Projekten oft zu Enttäuschungen aufseiten der Fachabteilungen.
- Datenverständnis: Hier besteht die Schwierigkeit oft darin, auf unvollständige oder ungenaue Daten zu stoßen. Die Datenqualität kann erheblich variieren, und es kann viel Zeit und Mühe erfordern, sie zu reinigen und vorzubereiten. Daten sind nämlich oft „schmutzig“. Damit sind zum Beispiel falsche Daten gemeint (z.B.: ein defekter Sensor) oder unvollständige Daten (z.B.: ein Sensor ist für einige Zeit ausgefallen). Zudem kann es sich als schwierig erweisen, alle relevanten Daten zu identifizieren und zu sammeln.
- Datenvorbereitung: Diese Phase ist häufig zeitaufwändig und arbeitsintensiv. Das Bereinigen und Transformieren von Daten kann komplex sein, insbesondere wenn die Daten aus verschiedenen Quellen stammen. Außerdem besteht eine mögliche Herausforderung darin, die richtigen Merkmale (Features) für die Modellierung zu wählen.
- Modellierung: Das Finden des richtigen Modells und die Feinabstimmung seiner Parameter kann schwierig sein. Es gibt oft nicht den „einen richtigen Weg“, und es erfordert Erfahrung und Fachwissen, die richtigen Methoden zu wählen. Overfitting, also das Überanpassen des Modells an die Trainingsdaten, kann ein weiteres Problem darstellen.
- Bewertung: Es kann sich als schwierig erweisen zu bestimmen, ob das Modell in der Praxis gut funktionieren wird, insbesondere bei unbalancierten Datensätzen oder wenn die Kosten für Fehlklassifikationen sehr unterschiedlich sind. Zudem besteht die Gefahr, dass das Modell zwar die Trainingsdaten gut erklärt, aber nicht gut generalisiert und auf neuen Daten schlecht abschneidet.
- Bereitstellung: Hier können Herausforderungen existieren, das Modell in bestehende Geschäftsprozesse und Systeme zu integrieren. Häufig gibt es technische oder organisatorische Hürden, und das Modell muss regelmäßig überwacht und gewartet werden, um sicherzustellen, dass es weiterhin korrekte Ergebnisse liefert.
Diese Überlegungen zeigen, dass die Theorie des CRISP-DM-Modells in der Praxis nicht selten durch eine Vielzahl von Herausforderungen ergänzt wird. Sind diese von Anfang an bewusst und werden im Projektplan mit berücksichtigt, kann die Wahrscheinlichkeit des Erfolgs eines Data-Science-Projekts deutlich erhöht werden.
Machine Learning als zentrale Phase
Auch wenn die Datensammlung und Datenaufbereitung meist arbeits- und zeitintensiv ist: Die Modellierungsphase ist zweifellos eine der zentralen und entscheidenden Phasen im CRISP-DM-Prozess. Sie ist das Herzstück des Data-Mining-Projekts, die Bühne, auf der die rohen, vorbereiteten Daten zu bedeutungsvollen Erkenntnissen transformiert werden. Dabei spielt das Machine Learning eine zentrale Rolle. Es ist das mächtige Werkzeug, das uns ermöglicht, komplexe Muster und Zusammenhänge in den Daten zu erkennen und Vorhersagen zu treffen, die oft weit über das hinausgehen, was wir als Menschen mit den Daten alleine leisten könnten.
Machine-Learning-Algorithmen lernen aus den Daten, identifizieren Trends und Muster und können diese Erkenntnisse nutzen, um auf neue, unbekannte Daten zu reagieren. Dabei bietet Machine Learning eine Vielzahl von Techniken – von einfachen linearen Regressionsmodellen bis hin zu komplexen künstlichen neuronalen Netzen. Jede Methode hat ihre Stärken und Schwächen, und die Kunst der Modellierung besteht darin, den richtigen Algorithmus für die spezifische Aufgabe zu wählen oder eine geschickte Auswahl unter den zur Verfügung stehenden Modellen durch geeignete Experimente automatisch durchzuführen.
Doch die Modellierungsphase und das Machine Learning sind mehr als nur die Anwendung einer Reihe von Algorithmen. Sie erfordern ein tiefgreifendes Verständnis der zugrunde liegenden Geschäftsproblematik und der Daten selbst. Ein gutes Modell berücksichtigt den Kontext und die Besonderheiten der Daten und kann diese in sinnvolle Erkenntnisse umsetzen, die Geschäftsentscheidungen vorbereiten oder unmittelbar einleiten.
Benötigte Kenntnisse
In der modernen Welt der Data Science sind technische Fähigkeiten und das Wissen um spezifische Werkzeuge und Technologien unerlässlich. Ein Data Scientist muss mehrere Hüte tragen und eine Vielzahl von Fähigkeiten beherrschen, von der Datenverarbeitung über die statistische Analyse bis hin zur Kommunikation komplexer Ergebnisse.
In diesem Zusammenhang spielen Python und Pandas eine entscheidende Rolle. Python ist eine der am weitesten verbreiteten Programmiersprachen in der Data Science, und das aus gutem Grund: Sie ist einfach zu erlernen, flexibel und verfügt über eine reiche Sammlung von Bibliotheken und Frameworks, die speziell für Data Science und Machine Learning entwickelt wurden. Pandas ist eine solche Bibliothek und bietet leistungsstarke Datenstrukturen und Funktionen zur Datenmanipulation und Analyse. Mit Python und Pandas können Data Scientists Daten effizient reinigen, transformieren und analysieren – essentielle Schritte in jedem Data-Science-Projekt.
Noch entscheidender sind die Fähigkeiten im Bereich des Machine Learning und Deep Learning. Machine Learning bildet den Kern der Modellierungsphase in Data-Science-Projekten und ermöglicht es, aus Daten Muster und Zusammenhänge zu erkennen und Vorhersagen zu treffen. Deep Learning, eine Untergruppe des Machine Learning, das auf künstlichen neuronalen Netzen basiert, hat sich als besonders effektiv bei der Verarbeitung großer Mengen von Bilddaten, Sprachdaten und sequentiellen Daten erwiesen.
Ein wenig Data Science sollte jeder können
In unserer zunehmend datengetriebenen Welt ist es nicht mehr ausreichend, dass nur Data Scientists oder technische Mitarbeiter ein Verständnis von Data Science und Machine Learning haben. Um wettbewerbsfähig zu bleiben und datengetriebene Entscheidungen auf allen Ebenen eines Unternehmens zu ermöglichen, müssen auch andere Rollen ein grundlegendes Verständnis für den Data-Science-Prozess entwickeln.
Betreiber von Netzwerken und Administratoren, die für die Überwachung und Wartung der Infrastruktur verantwortlich sind, können von einem Verständnis der Data Science profitieren, um Anomalien im Netzwerkverkehr zu erkennen und proaktiv auf potenzielle Probleme zu reagieren. Ebenso hilft ihnen dieses Wissen dabei, besser zu verstehen, wie sie ihre Systeme und Prozesse für eine effiziente Datenanalyse optimieren können.
Projektleitern, die oft die Brücke zwischen technischen Teams und der Geschäftsseite bilden, gelingt durch das Verständnis von Data Science besser einzuschätzen, was technisch machbar ist, welche Ressourcen benötigt werden und wie lange ein Projekt dauern könnte. Sie sind auch in der Lage sicherzustellen, dass die Ergebnisse der Datenanalyse in einer Weise präsentiert werden, die für Nicht-Techniker verständlich und nützlich ist.
Für Entscheider und Führungskräfte ist ein grundlegendes Verständnis der Data Science unerlässlich, um fundierte Entscheidungen zu treffen. Sie müssen fähig sein, die Ergebnisse von Datenanalysen zu verstehen, zu bewerten und in ihre Entscheidungsfindung einzubeziehen. Zudem können sie nur dann, wenn sie den Data-Science-Prozess verstehen, strategische Entscheidungen über Investitionen in Dateninitiativen, die Rekrutierung von Fachkräften oder die Entwicklung von datengetriebenen Produkten und Dienstleistungen effektiv treffen.
Insgesamt trägt ein breiteres Verständnis der Data Science in allen Ebenen eines Unternehmens zu einer stärkeren datengetriebenen Kultur bei, ermöglicht effektivere und informierte Entscheidungen und verbessert die Fähigkeit des Unternehmens, den Wert seiner Daten voll auszuschöpfen.
Kontakt
ComConsult GmbH
Burtscheider Markt 24
52066 Aachen
Telefon: 0241/887446-0
Fax: 0241/887446-200
E-Mail: info@comconsult.com
![]()